一,读写锁
前面几篇讲解了AQS的一些具体的实现,在对共享资源进行操作时,要么就是只能使用独占锁,对每一个线程都进行一个加锁的操作,要么就是单独使用共享锁,同时存在对多个资源的操作,但是在遇到类似缓存这种读多写少,读写同时存在的时候,那么就需要考虑独占锁和共享锁同时存在的需求了。
在AQS的具体实现类中,就存在同时对共享资源读和写的操作的实现类,就是并发包中提供的ReentrantReadWriteLock 类,在该类内部,就实现了读锁和一个写锁。总而言之就是在多个线程只需要读取数据的时候,可以使用共享结点实现,如果存在一个线程需要去写数据的时候,那么就需要通过独占结点实现,用一句话概况就是:读读共享、写写互斥
public class ReentrantReadWriteLock implements ReadWriteLock{
private static final long serialVersionUID = -6992448646407690164L;
/** Inner class providing readlock */
private final ReentrantReadWriteLock.ReadLock readerLock;
/** Inner class providing writelock */
private final ReentrantReadWriteLock.WriteLock writerLock;
}
1,读写锁的基本使用
在深入地了解这个类的底层原理之前,先了解一下这个类的基本使用,在这个 ReentrantReadWriteLock 类的注释中,已经有一个实例来方便我们了解这个类的基本使用,不得不说AQS里面所有的类的注释是非常的详细的
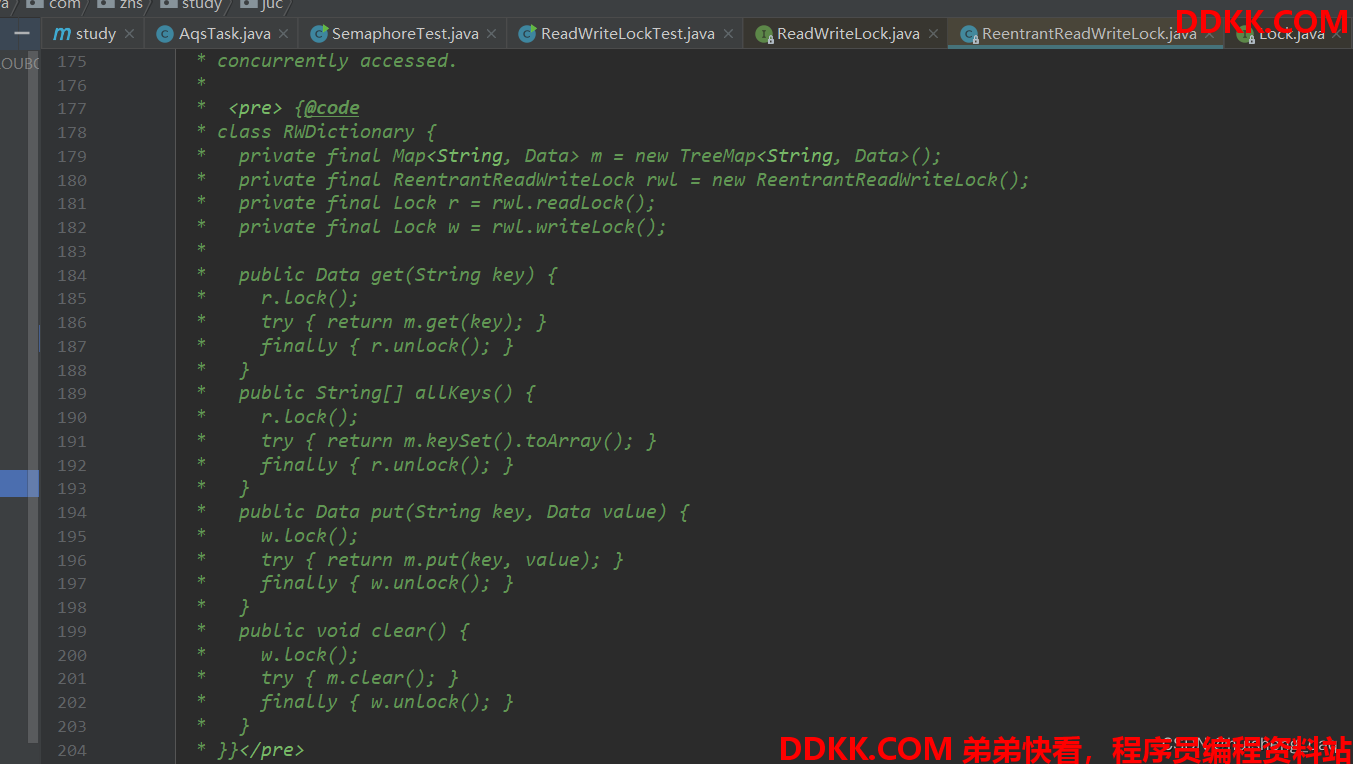
接下来参考他给的注释,仿写一个用例,用hashMap作为一级缓存,实现数据的缓存和读取。首先先定义一个线程池的工具类
/**
* 线程池工具
* @author DDKK.COM 弟弟快看,程序员编程资料站
* @date : 2023/10/06
*/
public class ThreadPoolUtil {
/**
* io密集型:最大核心线程数为2N,可以给cpu更好的轮换,
* 核心线程数不超过2N即可,可以适当留点空间
* cpu密集型:最大核心线程数为N或者N+1,N可以充分利用cpu资源,N加1是为了防止缺页造成cpu空闲,
* 核心线程数不超过N+1即可
* 使用线程池的时机:1,单个任务处理时间比较短 2,需要处理的任务数量很大
* 参考:https://blog.csdn.net/yuyan_jia/article/details/120298564
*/
public static synchronized ThreadPoolExecutor getThreadPool() {
if (pool == null) {
//获取当前机器的cpu
int cpuNum = Runtime.getRuntime().availableProcessors();
log.info("当前机器的cpu的个数为:" + cpuNum);
int maximumPoolSize = cpuNum * 2 ;
pool = new ThreadPoolExecutor(
maximumPoolSize - 2,
maximumPoolSize,
5L, //5s
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(), //数组有界队列
Executors.defaultThreadFactory(), //默认的线程工厂
new ThreadPoolExecutor.AbortPolicy()); //直接抛异常,默认异常
}
return pool;
}
}
接下来创建一个 PutHashMapTask 线程的任务类,用于添加数据,实现一个callAble接口,可以将添加后的hashMap给返回
/**
* @Author: zhenghuisheng
* @Date: 2023/10/6 22:41
*/
@Data
public class PutHashMapTask implements Callable {
Lock writeLock;
Map<String,Object> hashMap;
public PutHashMapTask(Lock writeLock,Map<String,Object> hashMap){
this.writeLock = writeLock;
this.hashMap = hashMap;
}
@Override
public Object call() throws Exception {
//上锁
writeLock.lock();
for (int i = 0; i < 1000; i++) {
hashMap.put(i+"",i);
}
//解锁
writeLock.unlock();
return hashMap;
}
}
随后创建一个 GetHashMapTask 的任务类,用于获取数据,不需要返回,直接打印出即可
/**
* @Author: zhenghuisheng
* @Date: 2023/10/6 22:41
*/
@Data
public class GetHashMapTask implements Runnable {
Lock readLock;
Map<String,Object> hashMap;
public GetHashMapTask(Lock readLock, Map<String,Object> hashMap){
this.readLock = readLock;
this.hashMap = hashMap;
}
@Override
public void run() {
//上锁
readLock.lock();
System.out.println(hashMap.get(new Random(1000)));
//解锁
readLock.unlock();
}
}
随后创建一个主线程类,内部定义一把 ReentrantReadWriteLock 读写锁,然后创建线程池一级创建一个hashMap作为一级缓存,随后读写都操作这个hash桶
/**
* @Author: zhenghuisheng
* @Date: 2023/10/6 22:36
*/
public class ReentrantReadWriteLockDemo {
//定义一把读写锁
private static ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private static Lock readLock = readWriteLock.readLock();
private static Lock writeLock = readWriteLock.writeLock();
//初始化一个线程池
static ThreadPoolExecutor threadPool = ThreadPoolUtil.getThreadPool();
//创建一个hashMap作为一级缓存
static Map<String,Object> hashMap = new HashMap<>();
public static void main(String[] args) throws Exception {
//写入数据任务线程
PutHashMapTask putHashMapTask = new PutHashMapTask(readLock,hashMap);
//向线程池中添加任务
Future<?> submit = threadPool.submit(putHashMapTask);
hashMap = (Map<String,Object>)submit.get();
System.out.println(hashMap.size());
//读取数据任务线程
GetHashMapTask getHashMapTask = new GetHashMapTask(writeLock,hashMap);
threadPool.execute(getHashMapTask);
//主线程休眠
Thread.sleep(100);
System.exit(0);
}
}
上面只是讲解了这个基本使用,还有一些读读共享,写写互斥以及写锁降级成读锁在这个类中都有详细的注释。
在写锁降级成读锁时,会在写锁释放锁之前,给读锁进行一个加锁的操作,主要是为了解决在高并发的场景下,在修改状态时为了保证所有线程的可见性问题,因为在工作线程将变量刷新到主内存时,会有一定的延迟,这样做得好处就是提前将值刷回到缓存,从而解决可见性的延迟问题。总而言之,写锁到读锁降级是为了保证可见性的问题,通过提前刷盘,保证缓存一致性,防止来不及刷盘而读取到脏数据
{
rwl.readLock().lock();
if (!cacheValid) {
rwl.readLock().unlock();
rwl.writeLock().lock();
try {
//读锁在写锁释放锁之前先加锁
rwl.readLock().lock();
}
} finally {
rwl.writeLock().unlock();
}
}
在这个读写锁中,目前还是只支持锁的降级,并没有支持锁的升级的,主要还是因为这个线程可见性的问题,就是假设在同一时刻多个线程来读取数据,其中一个线程修改了数据,那么此时读取线程的数据就变成了脏数据,这就是为啥有延迟双删这个实现的原因,尤其是在缓存中,网络问题等等不可避免的因素,以及最主要的可见性的问题,因此在读写锁中,并没有这个读锁到写锁升级的过程
2,读写锁的底层实现原理
在看底层源码之前,先看这个ReentrantReadWriteLock的类图,如下图所示,其顶层接口是一个readWriteLock,内部定义读锁和写锁的的抽象方法,内部同时引入了Sync,该接口是一个AQS的子类,具有AQS的所有特性,一次内部具有公平锁和非公平锁,可重入等特性
而不管是读锁还是写锁,内部都实现了这个Lock的接口,Lock内部定义了所有的加解锁的规范,整个AQS中,Lock是作为一个全局的规范类来使用的
public static class WriteLock implements Lock{
}
public static class ReadLock implements Lock{
}
2.1,读写状态state的设计
在之前的AQS系列中,都是通过cas + 同步等待队列来实现这个加锁的方式,不管是共享锁还是独占锁,同步状态器state的值都是只用于表示独占状态或者共享状态,就是一个单一的职责,那么读写锁是如何通过这个state来表示两种状态的呢,直接看源码吧
在这个ReentrantReadWriteLock的内部类中,有一个Sync的抽象的静态内部类,在中间有一段注释,其翻译结果如下
读取与写入计数提取常量和函数。锁状态在逻辑上分为两个无符号短路:较低的一个表示独占(写入器)锁保持计数,而较高的是共享(读取器)锁保持数
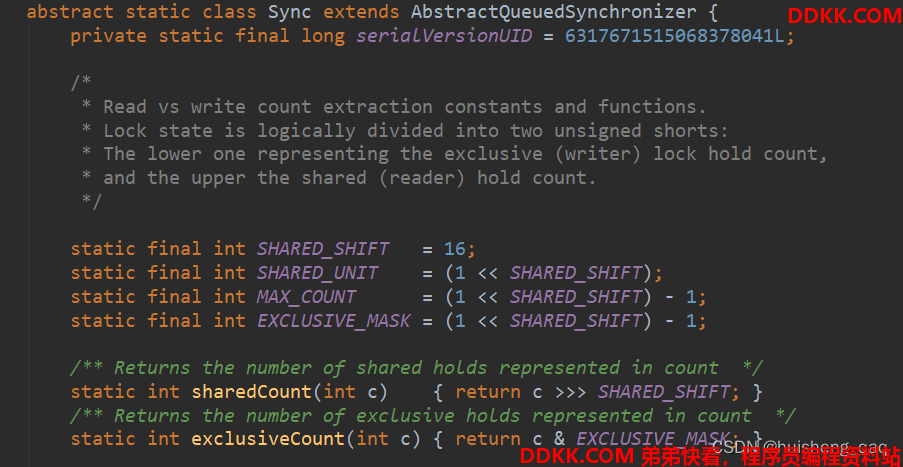
也就是说,读写锁也是通过这个state这个关键字来区分的,state是int的数据类型,占4个字节,就是32位,那么高16位表示的就是共享节点的数据,低16位表示的就是独占节点的数据
//高16位,共享节点 低16位,独占节点
00000000 00000000 00000000 00000000
因此就定义了变量 SHARED_SHIFT ,值为16,SHARED_UNIT 表示的是共享节点的单位,1右移16位;MAX_COUNT 表示的是最大线程的数据,不管是共享节点还是独占节点的最大值;EXCLUSIVE_MASK 表示的是独占节点的数据
static final int SHARED_SHIFT = 16;
static final int SHARED_UNIT = (1 << SHARED_SHIFT);
static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1;
static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1;
而且在获取数据时,内部已经定义好了返回值,如获取共享结点的线程数,独占结点的重入数等
//获取多少个线程占有这把共享锁,通过右移的方式获取
static int sharedCount(int c) {
return c >>> SHARED_SHIFT; }
//获取独占锁的总线程数,通过位运算
static int exclusiveCount(int c) {
return c & EXCLUSIVE_MASK; }
在共享锁中,通过 HoldCounter 方法和 ThreadLocalHoldCounter 来作为计数器的,内部主要是通过ThreadLocal 变量来记录可重入锁的次数。
static final class HoldCounter {
int count = 0;
// Use id, not reference, to avoid garbage retention
final long tid = getThreadId(Thread.currentThread());
}
static final class ThreadLocalHoldCounter
extends ThreadLocal<HoldCounter> {
public HoldCounter initialValue() {
return new HoldCounter();
}
}
2.2,写锁的底层实现
研究完这个state的底层设计之后,再来研究这个 writeLock 写锁底层的实现原理
private static Lock writeLock = readWriteLock.writeLock();
writeLock.lock();
writeLock.unLock();
2.2.1,lock加锁逻辑
首先依旧是通过这个lock方法作为入口,进去会进入这个 acquire 方法,首先会进入这个 tryAcquire 方法
public final void acquire(int arg) {
if (!tryAcquire(arg) && //尝试加锁
acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) //加锁失败则进入队列,独占节点
selfInterrupt();
}
随后查看这个方法,根据方法名称可知这是一个获取锁的方法。
由于是写锁加锁的逻辑,首先会获取state值,如果是0,那么高位肯定是没有值得,那么肯定是不存在读锁,后续直接操作这个写锁的逻辑即可。
如果state值不为0,那么就需要判断这个state是读锁还是写锁,首先会获取 exclusiveCount 写锁的总个数,如果个数为0,那么表示这个state的值都是读锁的,那么直接返回false,如果这个线程不是重入的,那么也会直接返回false;如果当前线程满足上面的任意条件,那么会判断当前线程重入的次数,不能超过2的32次方-1。总而言之可以总结成两句话:写写互斥,写读互斥
protected final boolean tryAcquire(int acquires) {
Thread current = Thread.currentThread(); //获取当前线程
int c = getState(); //获取状态,state位32位的值
int w = exclusiveCount(c); //获取独占的总线程个数
//如果state值不为0
if (c != 0) {
//如果独占的写锁个数为0并且不是重入锁,那么整个状态为读锁状态
if (w == 0 //写读互斥
|| current != getExclusiveOwnerThread()) //写写互斥
return false; //则直接返回false
//重入,个数不能大于2的16-1次方
if (w + exclusiveCount(acquires) > MAX_COUNT)
throw new Error("Maximum lock count exceeded");
//state的值+1,因为是写锁,只需要在低位加即可,不需要考虑左移
setState(c + acquires);
return true;
}
//如果获取的state值为0,那么高16位肯定是全为0,那么就进入独占锁逻辑
if (writerShouldBlock() || //阻塞操作,没有队列则创建
!compareAndSetState(c, c + acquires)) //cas抢锁
return false;
//同步状态器设置当前线程为独占锁线程
setExclusiveOwnerThread(current);
return true;
}
如果获取锁失败,则会执行入队的操作,前面几篇AQS的文章在写入队,阻塞的这些方法已经写了很多次了,因此这里不做详细的解释
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}
上面的是入队的操作,下面的是阻塞的逻辑,可以查看前面几篇AQS的文章,写的很详细了
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
2.2.2,unlock解锁逻辑
上面讲解了加锁的逻辑,下面的是writeLock解锁的逻辑,比较简单
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
}
首先会进入 tryRelease 方法中释放锁,就是将state的状态减1,由于是写锁,因此对低位操作刚好就是减少写锁的状态值
protected final boolean tryRelease(int releases) {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
int nextc = getState() - releases; //状态减1
boolean free = exclusiveCount(nextc) == 0; //判断写锁状态是否为0
if (free)
setExclusiveOwnerThread(null);
setState(nextc);
return free;
}
最后会调用这个 unparkSuccessor 进行出队和唤醒的操作,最终是调用这个LockSupport.unpark方法
LockSupport.unpark(s.thread);
2.3,读锁的底层实现
写锁的逻辑相对而言是比较简单的,接下来查看读锁的底层逻辑实现
private static Lock readLock = readWriteLock.readLock();
readLock.lock();
readLock.unLock();
2.3.1,读锁的加锁逻辑
依旧先查看这个readLock的lock加锁方法,很明显,操作的结点是一个共享结点,上面的写锁是一个独占结点。
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}
继续查看内部tryAcquireShared方法的加锁逻辑,很明显代码比写锁的更多。
首先依旧是会先判断是否存在写结点,如果存在直接返回-1,并且会判断在写结点降级成读结点时,结点是否为同一个结点,如果不是同一个结点则返回-1
如果只存在读结点,则会进行尝试加锁的操作,如果是第一次加这个读锁,则会单独记录,如果不是第一次加,则会将这些可重入锁存储在ThreadLocal里面,从而记录可重入锁的总数。最后如果加锁失败,则会自旋重试加锁
protected final int tryAcquireShared(int unused) {
Thread current = Thread.currentThread();
int c = getState(); //获取同步状态器的值
if (exclusiveCount(c) != 0 && //低位写结点的值不为0,读写互斥
getExclusiveOwnerThread() != current) //判断当前线程是否写线程,降级操作
return -1;
int r = sharedCount(c); //读锁的总数
if (!readerShouldBlock() &&
r < MAX_COUNT && //小于65535
compareAndSetState(c, c + SHARED_UNIT)) {
//尝试加锁,加65535
if (r == 0) {
//第一次进来获取读锁
firstReader = current;
firstReaderHoldCount = 1;
} else if (firstReader == current) {
//代表重入
firstReaderHoldCount++;
} else {
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++; //threadLocl + 1
}
return 1;
}
return fullTryAcquireShared(current); // 加锁失败再次尝试获取
}
2.3.1,读锁的解锁逻辑
接下来继续查看这个unlock方法,首先会进入这个 releaseShared 方法
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
接下来查看这个 tryReleaseShared 释放锁的方法,其内部主要就是做了两件事,第一件就是将重入锁的值降低为0,第二件事就是讲高位的值进行减1的操作
protected final boolean tryReleaseShared(int unused) {
Thread current = Thread.currentThread();
//如果有可重入锁,则清0
if (firstReader == current) {
// assert firstReaderHoldCount > 0;
if (firstReaderHoldCount == 1) firstReader = null;
else firstReaderHoldCount--;
} else {
ReentrantReadWriteLock.Sync.HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
rh = readHolds.get();
int count = rh.count;
if (count <= 1) {
readHolds.remove();
if (count <= 0) throw unmatchedUnlockException();
}
--rh.count;
}
for (;;) {
int c = getState();
int nextc = c - SHARED_UNIT; //减高位的值
if (compareAndSetState(c, nextc)) return nextc == 0;
}
}
3,总结
ReentrantReadWriteLock读写锁底层也是通过AQS实现,通过state的高低位来区分读锁和写锁,高位表示读锁,低位表示写锁,高位读锁采用的是共享结点,低位写锁采用的是独占节点,共享结点中采用ThreadLocal来保存重入锁的次数,在整个读写锁中,主要是满足以下的规则:读读共享、读写互斥、写写互斥、写读降级
内部的ReadLock和WriteLock满足AQS的所有特性,内部也全部实现了CAS抢锁、失败入队、队列不存在则先创建队列,线程阻塞、修改结点状态、结点出队、线程唤醒等操作