在高性能硬件上部署程序,目前主要有两种方式:
1、 通过64位JDK来使用大内存;
2、 通过若干个32位虚拟机建立逻辑集群来利用硬件资源;
32位的虚拟机和64位的虚拟机部署应用有什么区别?
1、 在32位的Windows平台中每个进程只能使用2GB内存,考虑到堆以外的内存开销,堆一般最多只能开到1.5GB;在Linux或者UNIX系统中,可以提升到3GB乃至接近4GB的内存,但仍然受到最高4GB(2^32)内存的限制使用64位的虚拟机可以管理更大的内存;
2、 64位虚拟机的内存回收将导致更长的时间停顿;
3、 现阶段,64位JDK的性能测试结果普遍低于32位的JDK;
4、 64位的JDK要是产生堆溢出几乎就无法产生堆存储快照(因为要产生十几GB乃至更大的Dump文件),哪怕产生了快照也几乎无法进行分析;
5、 相同程序在64位JDK消耗的内存一般比32位JDK大,这是由于指针膨胀,以及数据类型对齐补白等因素导致的;
除了Java 堆、虚拟机栈和元空间以外,下面这些区域还会占用较多的内存:
1、 DirectMemory:直接内存,多用于NIO操作,可通过-XX:MaxDirectMemorySize调整大小,内存不足时抛出OutOfMemoryErrorDirectMemory的回收只能等待老年代满了以后FullGC,然后“顺便地”帮它清理掉内存的废弃对象,否则它只能一直等到OutOfMemoryError时,先catch掉,再在catch块里面调用System.gc();
2、 Socket缓冲区:每个Socket连接都有Receive和Send两个缓冲区,分别占大约37KB和25KB的内存,连接多的话这块内存占用也比较可观如果无法分配,则可能会抛出IOException:Toomanyopenfiles异常;
3、 JNI代码:如果代码中使用JNI调用本地库,那本地库使用的内存也不在堆中;
4、 虚拟机和GC:虚拟机、GC的代码执行也要消耗一定的内存;
破坏双亲委派模型
1、 Java中所有涉及SPI的加载动作,比如JNDI、JDBC、JCE、JAXB和JBI等,都是违背了双亲委派模型来逆向使用类加载器,它利用“线程上下文类加载器”去加载所需要的SPI代码,也就是父类加载器请求子类加载器去完成类加载的动作;
2、 在OSGi里面,加载器之间的关系不再是双亲委派模型的树形结构,而是进一步发展成了一种运行时才能确定的网状结构OSGi的Bundle类加载器之间只有规则,没有固定的委派关系例如,某个Bundle声明了一个它依赖的Package,如果有其他的Bundle声明发布了这个Package后,那么对这个Package的所有类加载动作都会委派给发布它的Bundle类加载器去完成OSGi也是基于此实现模块级的热插拔功能,典型的案例就是EclipseIDE;
字节码执行引擎
1、 字节码执行引擎是Java虚拟机最核心的组成部分之一;
2、 在Java虚拟机规范中制定了虚拟机字节码执行引擎的概念模型,这个概念模型成为各种虚拟机执行引擎的统一外观(Facade);
3、 所有Java虚拟机的执行引擎都是一致的:输入的是字节码文件,处理过程是字节码解析的等效过程,输出的是执行结果;
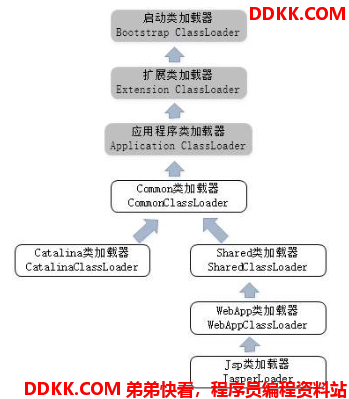
Tomcat 的 JSP 文件为什么可以实现热替换?
Tomcat 自定义了 CommonClassLoader、CatalinaClassLoader、SharedClassLoader 和 WebappClassLoader 四种类加载器,分别加载 /common/*、/server/*、/shared/* 和 /WebApp/WEB-INF/* 中 Java 类库的逻辑。其中 WebApp 类加载器和 JSP 类加载器通常会存在多个实例,每一台 Web 应用程序对应一个 WebApp 类加载器,每一个 JSP 文件对应一个 Jsp 类加载器,JSP 类加载器的加载范围仅仅是这个 JSP 文件所编译出来的那一个 Class,它出现的目的就是为了被丢弃:当服务器检测到 JSP 文件被修改时,会替换掉目前的 JSP 类加载器的实例,并通过再建立一个新的 JSP 类加载器来实现 JSP 文件的热替换。
JDK 的每次版本升级,新增的功能大致可以分为下面四类:
1、 在编译层面的改进如自动装箱拆箱、变长参数、泛型等;
2、 JavaAPI的代码增强如Collections、java.util.concurrent并发包等;
3、 需要在字节码层面支持的改动如升级版本号之类;
4、 虚拟机内部的改动这类改动对于程序员编写代码基本是透明的,但会对程序运行时产生影响;
其他
1、 学习JEE规范,去看JBoss源码;学习类加载器,就去看OSGi源码;
2、 动态代理中所谓的“动态”,是针对使用Java代码实际编写了代理类的“静态”代理而言的,它的优势不仅在于省去了编写代理类那一点工作量,而是实现了可以在原始类和接口还未知的时候,就确定代理类的代理行为,当代理类与原始类脱离直接联系后,就可以很灵活地重用于不同的应用场景之中;
3、 Cpuload、jvmgc在查看的时候,一般有个参考标准:Cpuload<0.4C(核心数)、Fullgc发生间隔>6小时,耗时<500ms;