一、概述
从前面文章 中我们可以了解到,javac 的三个步骤中,程序员唯一能干预的就是注解处理器部分,注解处理器类似于编译器的插件,在这些插件里面,可以读取、修改、添加抽象语法树中的任意元素。因此,只要有足够的创意,程序员可以通过自定义插入式注解处理器来实现许多原本只能在编码中完成的事情。我们常见的 Lombok、Hibernate Validator 等都是基于自定义插入式注解器来实现的。
要实现注解处理器首先要做的就是继承抽象类 javax.annotation.processing.AbstractProcessor,然后重写它的 process() 方法,process() 方法是 javac 编译器在执行注解处理器代码时要执行的过程。
public abstract boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv);
该方法有两个参数,“annotations” 表示此处理器所要处理的注解集合;“roundEnv” 表示当前这个 Round 中的语法树节点,每个语法树节点都表示一个 Element(javax.lang.model.element.ElementKind 可以查看到相关 Element)。
该方法的返回值是一个 boolean 类型,通知编译器这个 Round 中的代码是否发生变化,是否需要构建新的 JavaCompiler 实例,是否需要开启新的 Round。
除了process() 方法外,还有两个可以配合使用的 Annotations:
@SupportedAnnotationTypes("*")
@SupportedSourceVersion(SourceVersion.RELEASE_8)
@SupportedAnnotationTypes 表示注解处理器对哪些注解感兴趣,“*” 表示对所有的注解都感兴趣;@SupportedSourceVersion 指出这个注解处理器可以处理最高哪个版本的 Java 代码。
另外AbstractProcessor 还有一个很常用的实例变量 “processingEnv”,它在 init() 方法执行的时候创建,它代表了注解处理器框架提供的一个上下文环境,要创建新的代码、向编译器输出信息、获取其他工具类等都需要用到这个实例变量。
public synchronized void init(ProcessingEnvironment processingEnv) {
// ...
}
**tips:**每一个注解处理器在运行的时候都是单例的。
二、自定义
我们现在要自定义一个插入式注解器 — NameCheckProcessor,它要做的事情是对 Java 程序命名进行检查,检查的规则如下:
-
类(或接口):符合驼式命名法,首字母大写
-
方法:符合驼式命名法,首字母小写
-
字段:
-
类或实例变量:符合驼式命名法,首字母小写
-
常量要求全部是大写字母或下划线构成,并且第一个字符不能是下划线。
@SupportedAnnotationTypes("*")
@SupportedSourceVersion(SourceVersion.RELEASE_8)
public class NameCheckProcessor extends AbstractProcessor {
private NameChecker nameChecker;
@Override
public synchronized void init(ProcessingEnvironment processingEnv) {
super.init(processingEnv);
nameChecker = new NameChecker(processingEnv);
}
@Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
if (!roundEnv.processingOver()) {
for (Element element : roundEnv.getRootElements()) {
nameChecker.checkNames(element);
}
}
return false;
}
}
从上面代码可以看到,NameCheckProcessor 最高能处理 JDK1.8 的代码,并对所有的注解都感兴趣,而在 process() 方法中是把当前 Round 中的每一个 RootElement 传递到一个名为 NameChecker 的检查器中检查逻辑,process() 方法返回 false,因为它只是检查命名规范,并未改变语法树。
NameChecker 负责检查命名规范,这是它 github代码链接,哈哈,具体代码就不在文章里贴了,再贴一下文章就没法看了都。
NameChecker 通过一个继承 javax.lang.model.util.ElementScanner8 的 NameCheckScanner 类,以 Visitor 模式来完成对语法树的遍历,分别执行 visitType()、visitExecutable() 和 visitVariable() 来访问类、方法和字段,这 3 个 visit 方法对各自的命名规则做相应的检查。
自定义注解器写好了,那么问题来了,注解器怎么用呢?
- 通过 javac 命令的 “-processor” 参数来执行编译时需要附带的注解处理器,如果有多个注解处理器的话,用逗号进行分割。
- 通过 JAVA SPI 加载。在 resources 目录下新增 META-INF/services 目录,目录内添加名为 javax.annotation.processing.Processor 的文件,内容是自定义注解器的全类名,一行表示一个注解器。
三、应用
这里主要介绍下利用 Java SPI 加载自定义注解器的方式,我们的目标是生成一个 jar 包,类似于 Lombok ,这样其它应用一旦引用了这个 jar 包,自定义注解器就能自动生效了。
1. 生成注解器 jar 包
首先,我们先来看下自定义注解器的目录结构,在 javax.annotation.processing.Processor 文件中是自定义注解器的全类名。
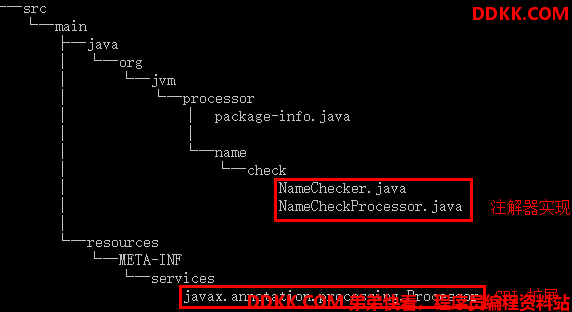
org.jvm.processor.name.check.NameCheckProcessor
然后,在 pom.xml 中配置 proc 属性,如果不配置的话,会有个 WARNNING 提示— 找不到 processor 的异常。
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<proc>none</proc>
</configuration>
</plugin>
</plugins>
</build>
最后,愉快的使用 mvn clean install 来 build 你的注解器 jar 包吧!
2. 使用注解器 jar 包
首先,在 pom.xml 中引入注解器 jar 包的依赖
<dependency>
<groupId>org.jvm.processor</groupId>
<artifactId>processor</artifactId>
<version>1.0.0-SNAPSHOT</version>
</dependency>
其实,进行到这一步你的自定义注解器已经生效了!另外,maven-compiler-plugin 支持手动对需要运行的注解器进行设置。
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<annotationProcessors>
<annotationProcessor>
org.jvm.processor.name.check.NameCheckProcessor
</annotationProcessor>
</annotationProcessors>
</configuration>
</plugin>
tips: maven-compile-plugin 等编译插件会吞掉 javax.annotation.processing.Messager 所打印的东西,而手动使用 javac 编译器则不会。
四、总结
上文的注解器案例主要参考《深入理解 JVM 虚拟机》,后来又在网上看了一些大家的实践,觉得还挺开拓思维的,大家可以试试看。
自定义注解器这东西,类似于拦截器功能,只要思维都大胆,感觉能玩出花来!
上文的演示的代码可参见:https://github.com/JMCuixy/jvm-demo