一、概述
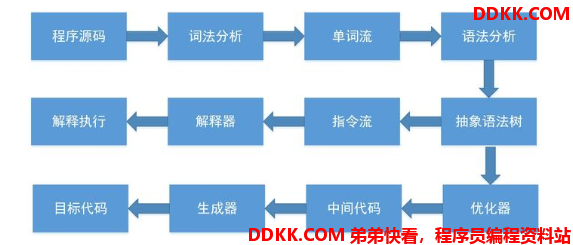
如今,基于物理机、Java虚拟机或者是非 Java 的其他高级语言虚拟机(HLLVM)的语言,大多数都遵循如下现代经典编译原理的思路,在执行前先对程序源码进行词法分析和语法分析处理,把源码转化为抽象语法树。对于一门具体语言的实现来说,词法和语法分析乃至后面的优化器和目标代码生成器都可以选择独立于执行引擎,形成一个完整意义的编译器去实现,这类代表是 C/C++ 语言。也可以选择把其中一部分步骤(如生成抽象语法树之前的步骤)实现为一个半独立的编译器,这类代表是 Java 语言(以下介绍的 javac 编译器)。又或者把这些步骤和执行引擎全部集中封装在一个封闭的黑匣子之中,如大多数的 JavaScript 语言。
我们都知道 *.java 文件要首先被编译成 *.class 文件才能被 JVM 认识,这部分的工作主要由 Javac 来完成,类似于 Javac 这样的我们称之为前端编译器;
但是*.class 文件也不是机器语言,怎么才能让机器识别呢?就需要 JVM 将 *.class 文件编译成机器码,这部分工作由JIT 编译器完成;
除了这两种编译器,还有一种直接把 *.java 文件编译成本地机器码的编译器,我们称之AOT 编译器。
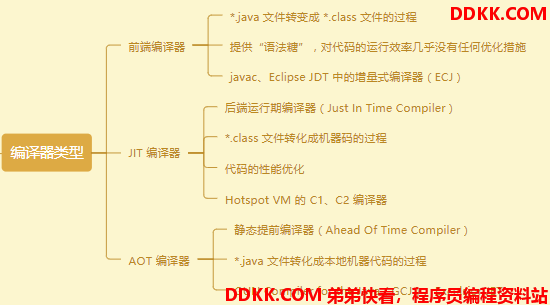
AOT编译器一直以来都没有掀起什么大风浪,直到 JDK9 中出现的 Jaotc 提前编译器,这是一个基于 Graal 编译器实现的新工具,目的是让用户可以针对目标机器,为应用程序进行提前编译。HotSpot 运行时可以直接加载这些编译的结果,实现加快程序启动速度,减少程序达到全速运行状态的时间。但是提前编译器无可避免的具有破坏平台中立性、导致字节膨胀等特点,尽管如此,提前编译无疑已经成为了一种极限榨取性能的手段,且被官方 JDK 关注,可以预想未来会有一个好的发展。
此外,由于 Jaotc 是基于 Graal 编译器开发的,所以现在 ZGC 和 Shenandoah 收集器还不支持 Graal 编译器,自然它们在 Jaotc 上也是无法使用的。事实上,目前 Jaotc 只支持 G1 和 Parallel 两种垃圾收集器。
二、javac 的编译过程
首先,我们先导一份 javac 的源码(基于 openjdk8)出来,下载地址:https://hg.openjdk.java.net/jdk8/jdk8/langtools/archive/tip.tar.gz,然后将 JDK_SRC_HOME/langtools/src/share/classes/com/sun 目录下的源文件全部复制到工程的源码目录中,生成的 目录 如下:
我们执行 com.sun.tools.javac.Main 的 main 方法,就和我们在命令窗口中使用 javac 命令一样:
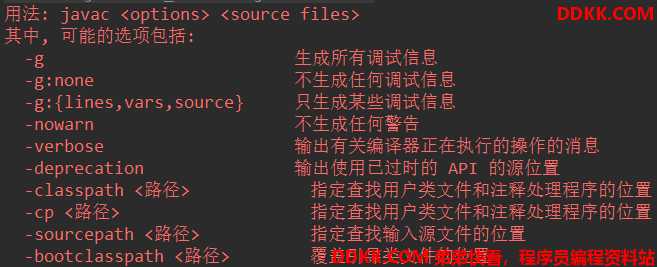
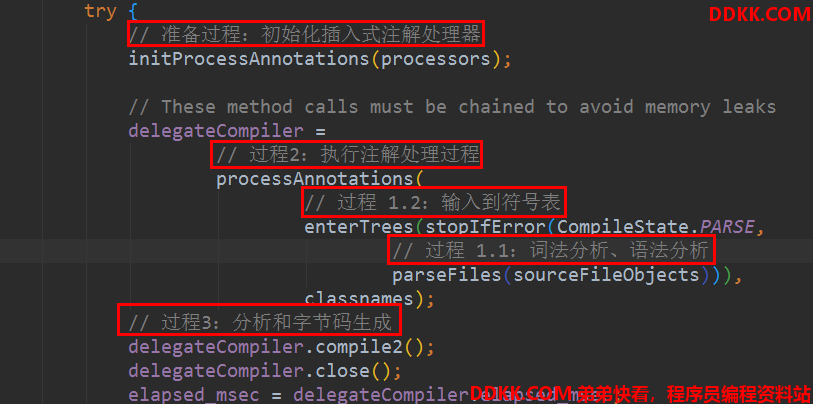
从Sun Javac 的代码来看,编译过程大致可以分为三个步骤:
- 解析和填充符号表过程
- 插入式注解处理器的注解处理过程
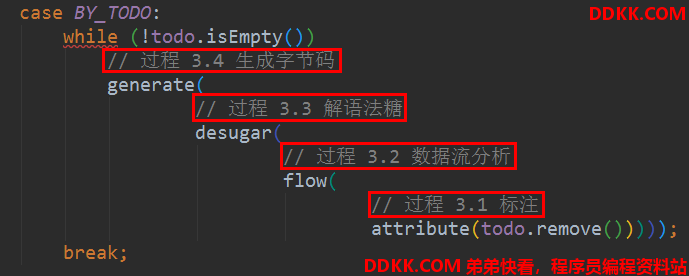
- 分析和字节码生成过程
这三个步骤所做的工作内容大致如下:
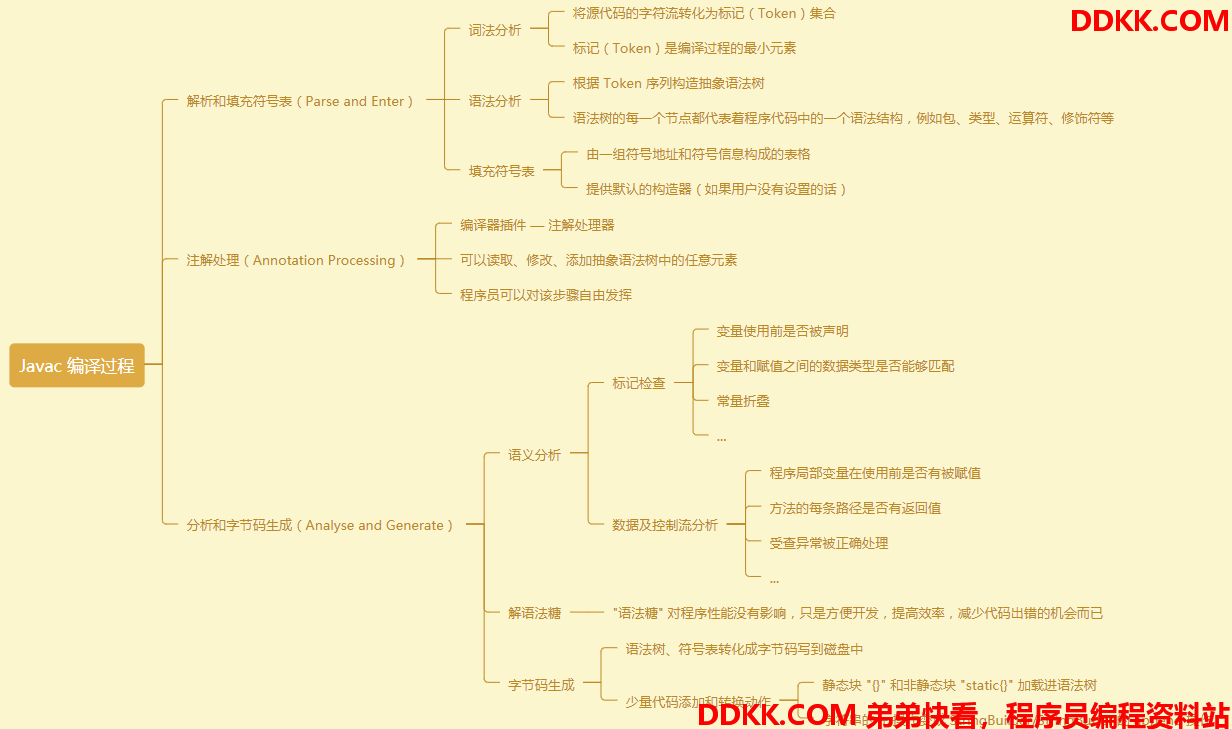
这三个步骤之间的关系和交互顺序如下图所示,可以看到如果注解处理器在处理注解期间对语法树进行了修改,编译器将回到解析和填充符号表的过程进行重新处理,直到注解处理器没有再对语法树进行修改为止。

Javac 编译的入口是 com.sun.tools.javac.main.JavaCompiler 类,上述三个步骤的代码都集中在这个类的 compile() 和 compile2() 中: