本章介绍init()第五个步骤,初始化调度器的trigger线程池,以及trigger一个任务的详细流程。
一、 快慢线程池
定义
- JobTriggerPoolHelper.toStart();
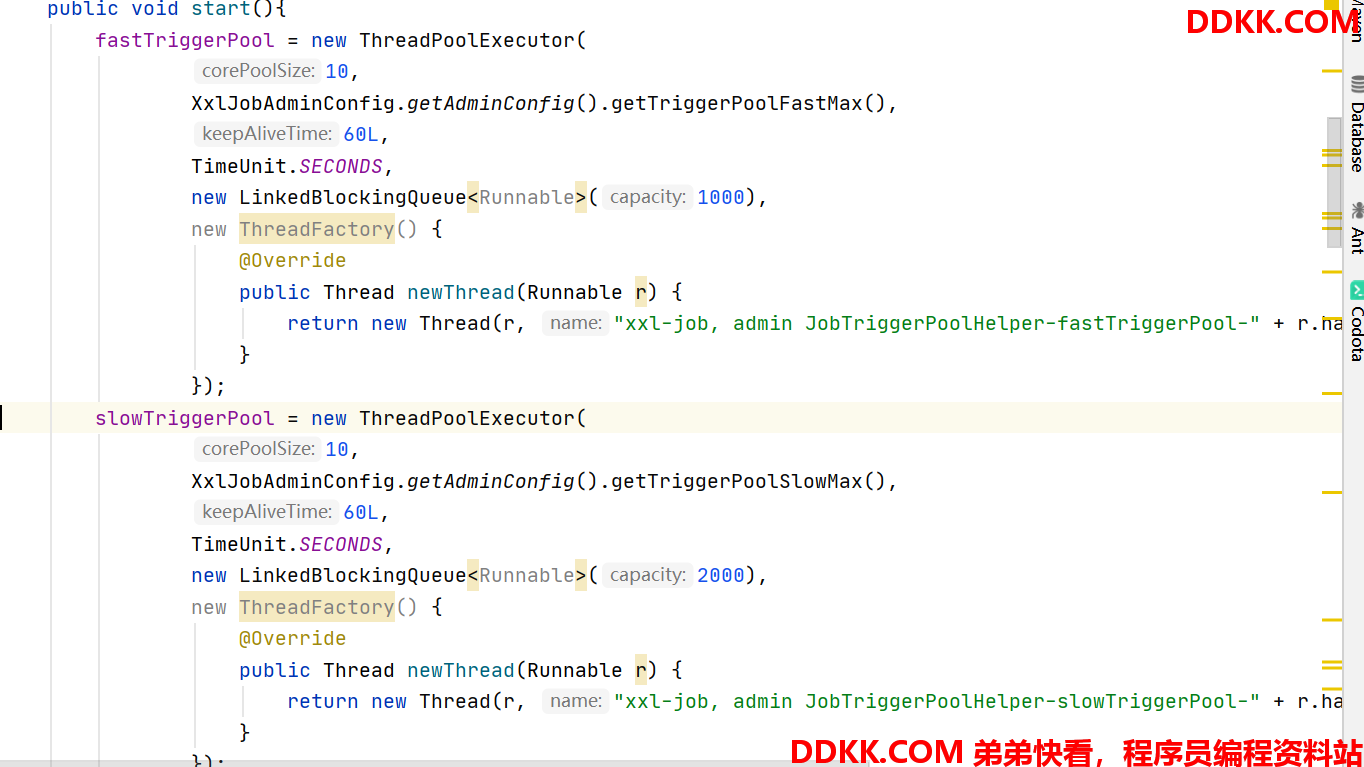
调度器启动时,初始化了两个线程池,除了慢线程池的队列大一些以及最大线程数由用户自定义以外,其他配置都一致。
两者的区别在于:快线程池用于处理时间短的任务,慢线程池用于处理时间长的任务,这一点在addTrigger方法中可以得到验证。
慢任务处理
- addTrigger()
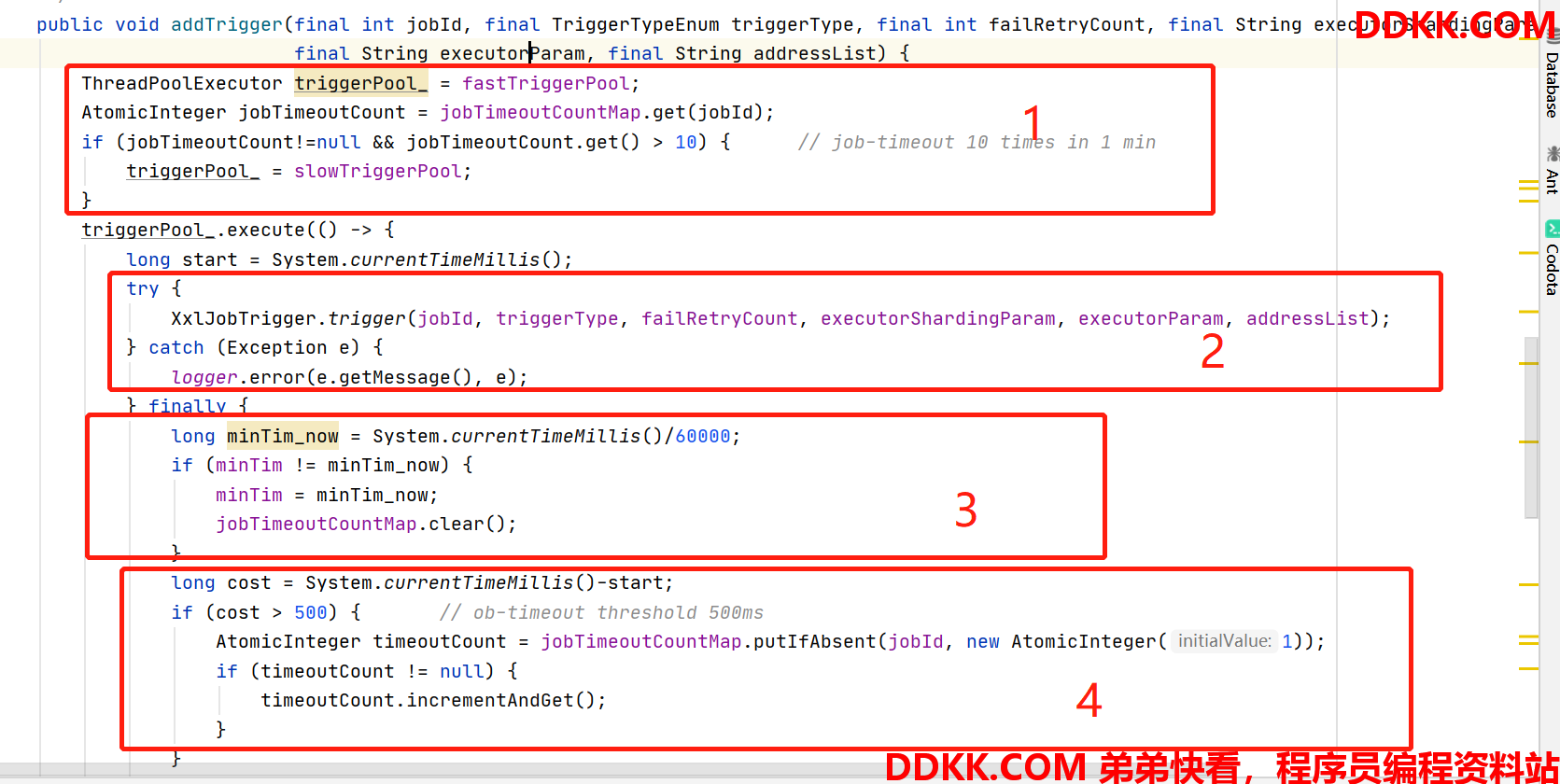
1、 通过jobTimeoutCountMap判断当前任务是否是曾超过10次的慢任务,慢任务由慢线程池运行jobTimeoutCountMap存储了jobId曾经的执行耗时;
2、 trigger主逻辑;
3、 结合minTim变量的初始化来看,这里的目的是一小时一次,清空jobTimeoutCountMap为了避免慢任务这辈子都翻不了身![ ][nbsp2];
4、 计算耗时,并将大于500ms的存储到jobTimeoutCountMap中如果该job已存在,则value+1,这里体现了value的含义,记录慢执行的次数;
到此方法结束,接下来我们继续深入trigger。
二、 负载算法
群起而攻之——分片广播
- 先介绍一下分片广播的算法实现:
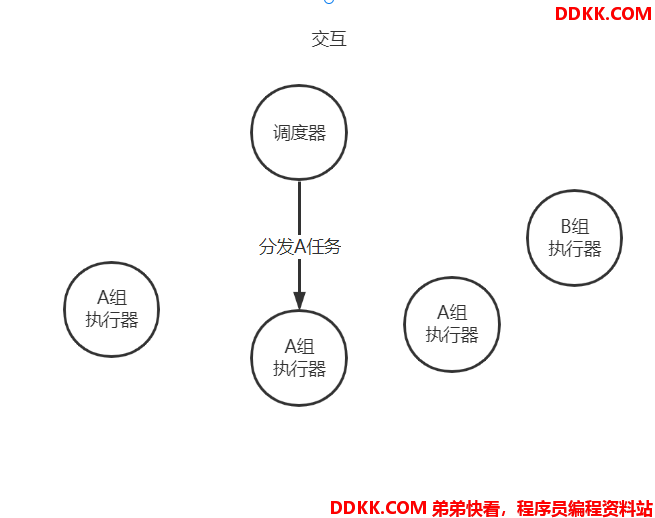
如下图,对于一个具体的任务A来说,一般的负载算法都是在众多A任务所属执行器中,通过某种负载算法选择一个进行执行。
但是这一类算法对于大数据量的任务不友好,一个任务只会触发一个执行器,如果我们我们的任务过大可能会导致这个执行器溢出/时间过长等问题,此时我们就需要分片广播了。
既然一个执行器不足以处理这个大任务,那我们是不是可以将这个任务拆分,分给其他执行器执行呢?只要任务满足拆分条件,当然是可以的。
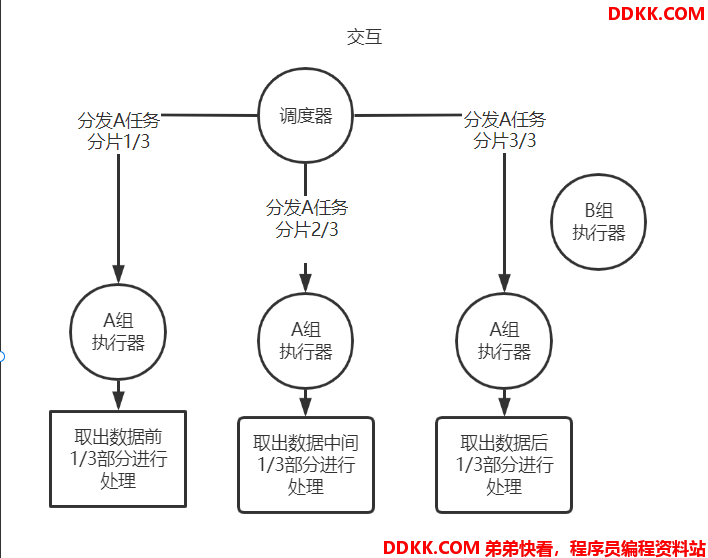
这就是分片广播算法,接下来我们看一下源码实现。
- trigger()
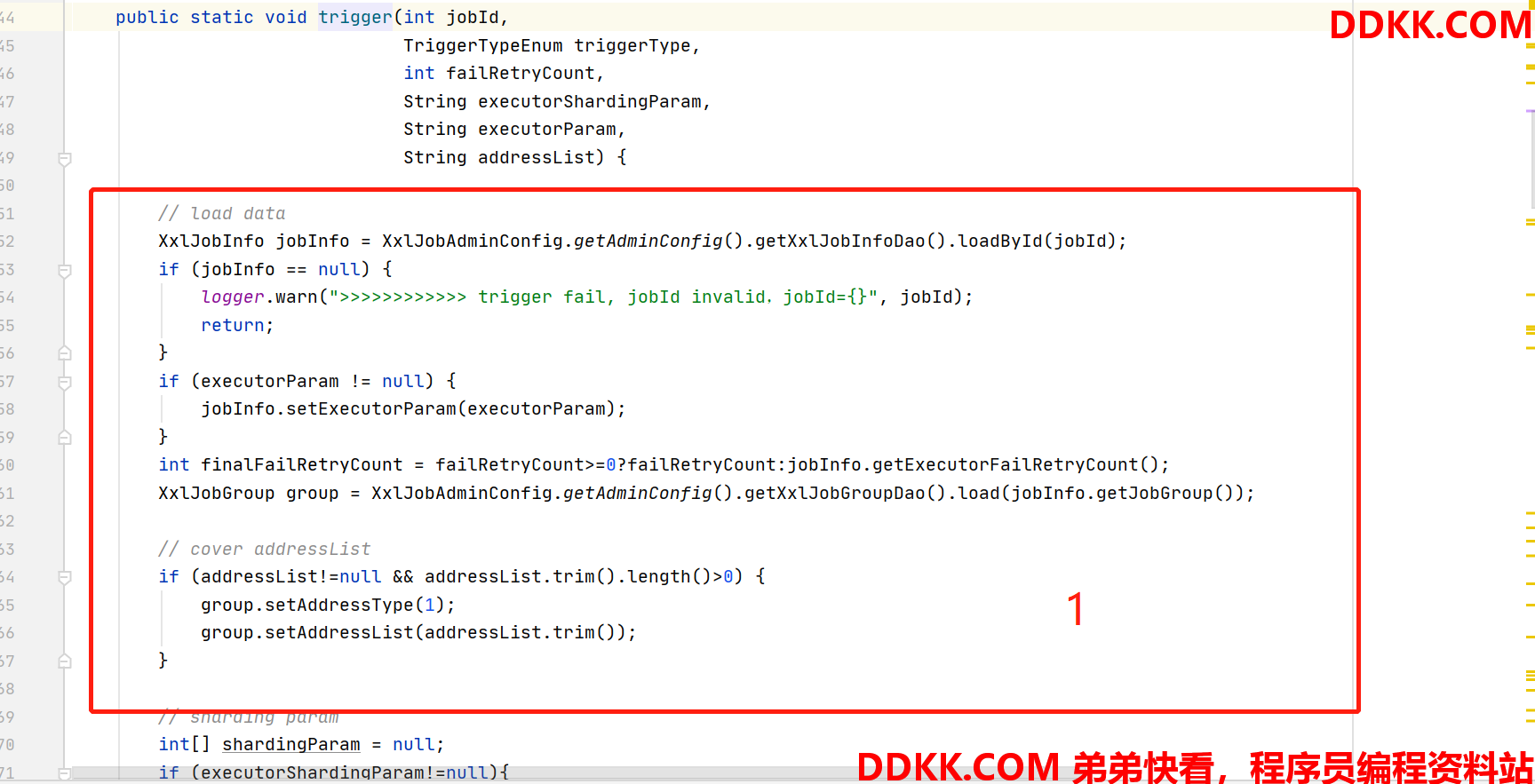
1、 加载job详情,同时如果存在外部传入的执行参数和执行地址,则使用,这里的外部场景即上图在页面手动执行;
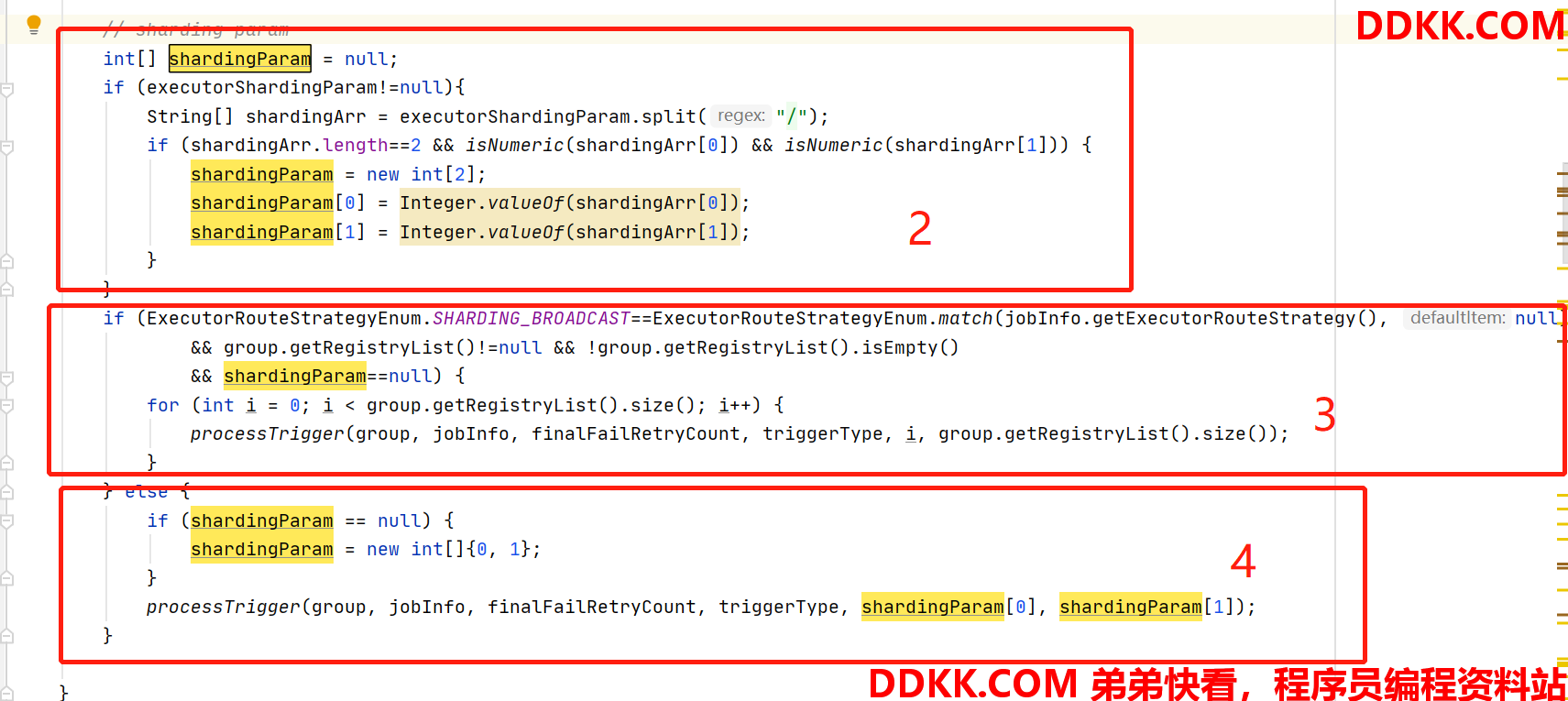
2、 这里开始时负载算法为分片广播才会用到的分片参数处理,举例:分片参数格式为1/3,1代表index,3代表total;
3、 判断负载算法为分片广播,并且shardingParam不为null,则进行任务处理;
4、 否则将shardingParam赋默认值,进行任务处理,这里的processTrigger不只分片广播,也包含了其他负载处理逻辑;
接下来,进入最终的处理逻辑,processTrigger()
其他负载算法
- processTrigger()
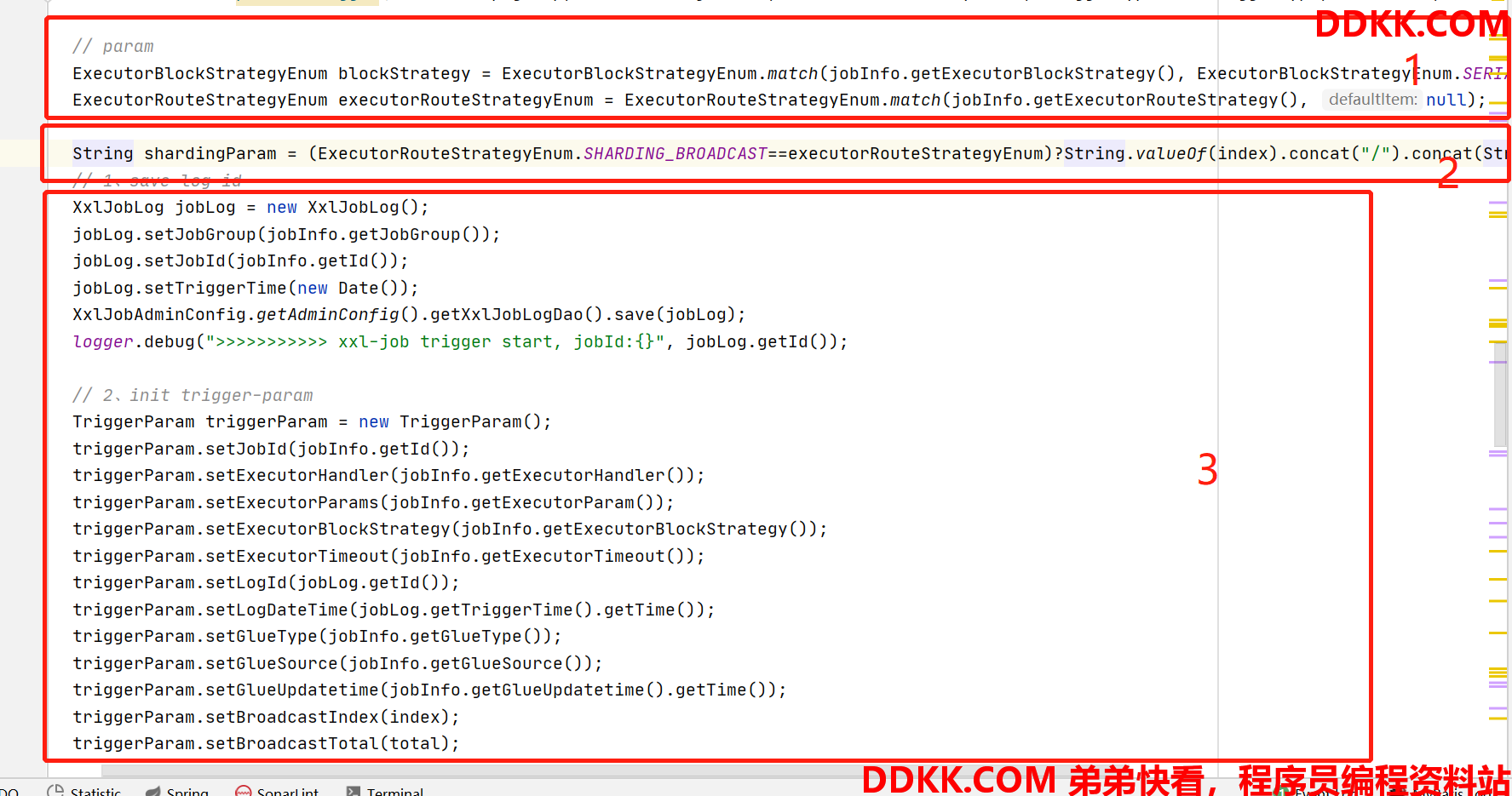
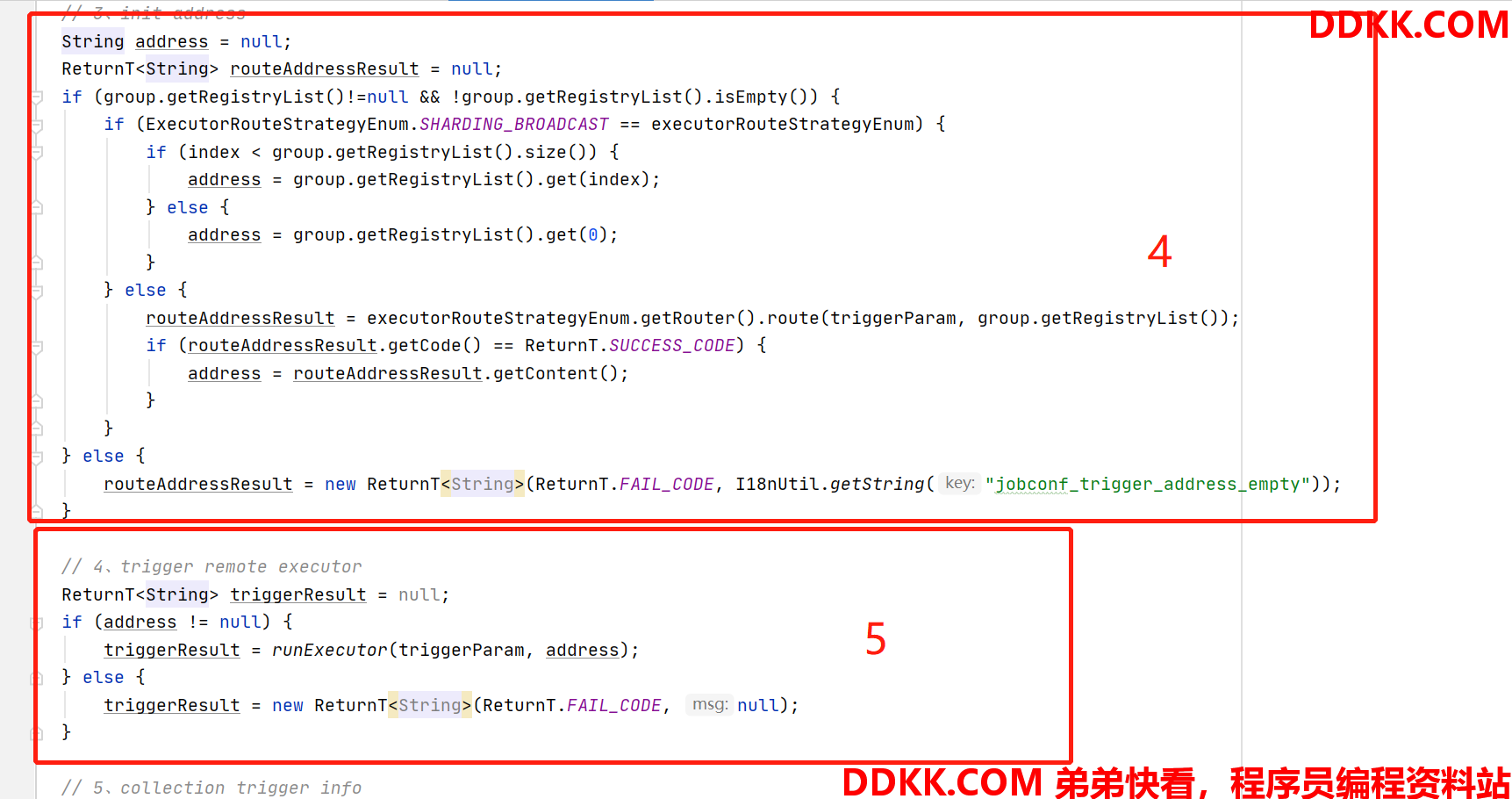

1、 获取任务阻塞处理枚举与负载策略枚举;
2、 将入参被拆分的shardingParam再组合起来,这个格式就是执行器最后会拿到的参数;
3、 保存job日志,组装该任务的执行器触发参数;
4、 这里用了一个策略模式,通过负载策略获取到实际的负载策略处理类,这里的处理类具体分析见下方;
5、 进行任务处理,请求对应执行器,并等待拿到执行结果这里使用的就是之前提到的ExecutorBiz接口的run方法;
6、 对结果进行格式化处理,更新日志;
负载算法
回到上面第四步,ExecutorRouteStrategyEnum.getRouter方法。
见下图,这个枚举类,实际上还保存了不同负载策略对应的处理类实例。
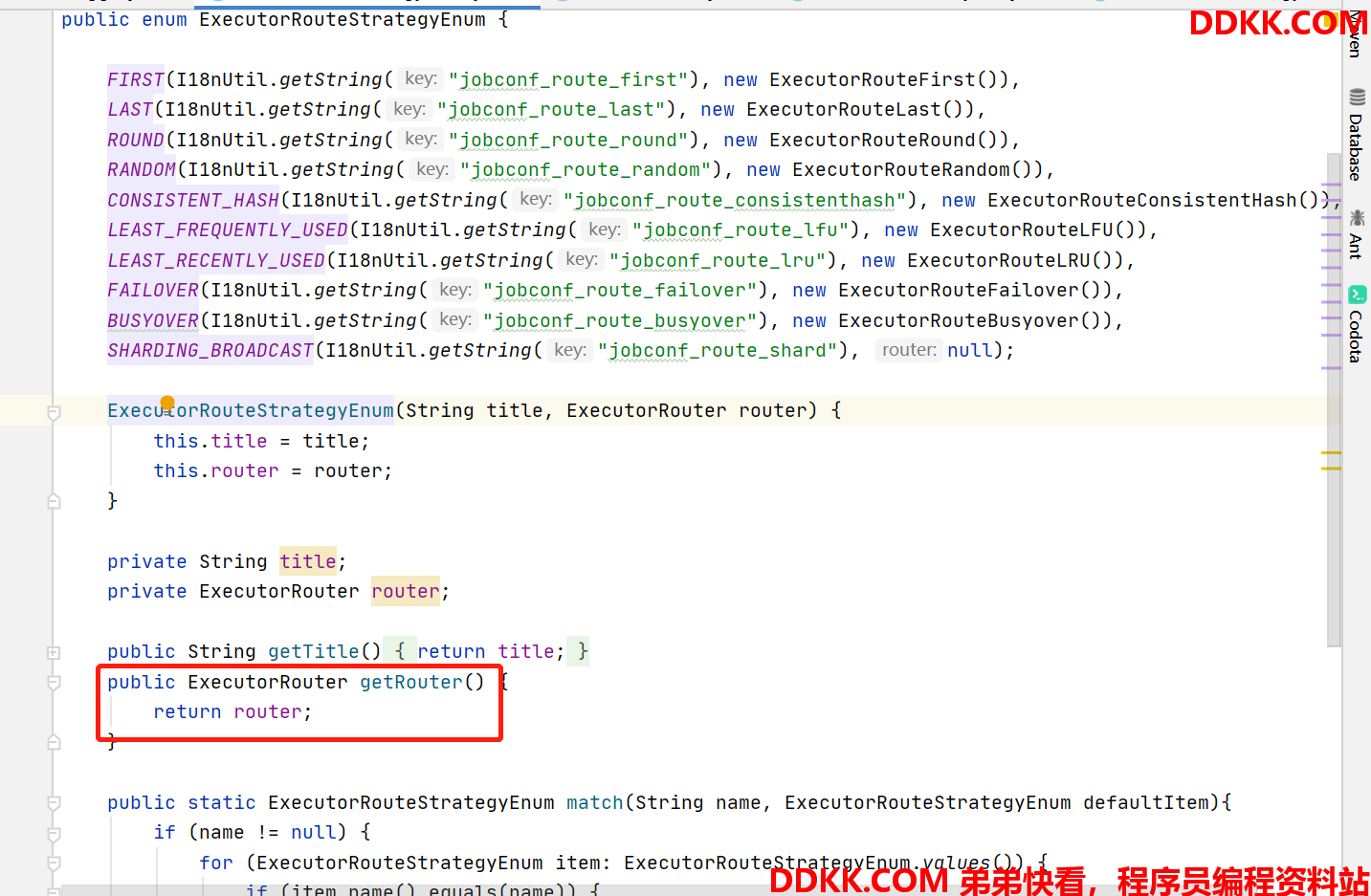
这些实例,从上到下与页面一一对应
前四个没什么好说的,字面意思。
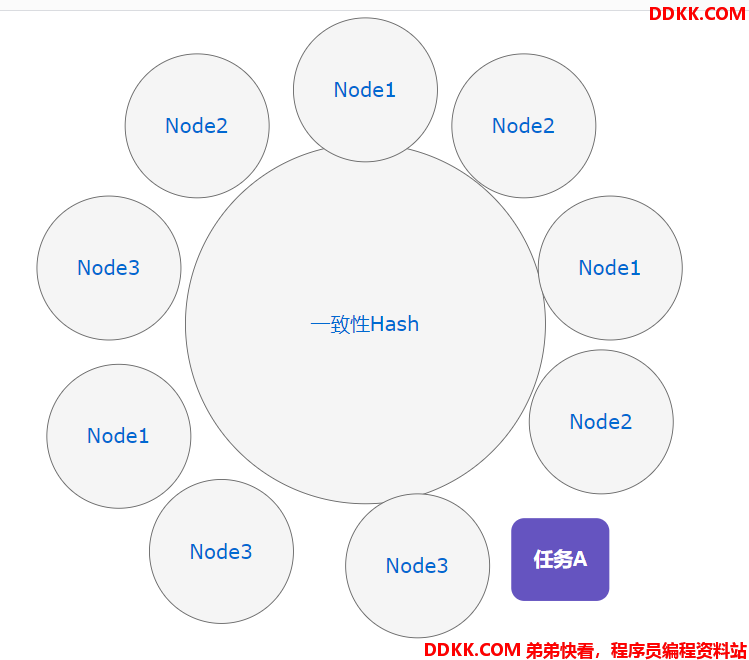
一致性Hash算法
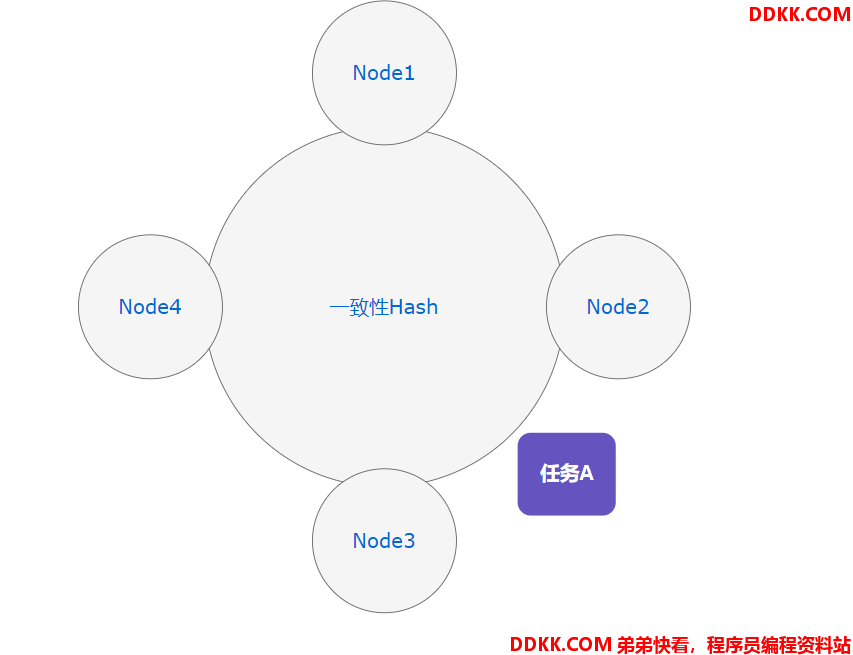
如图所示,一致性Hash算法的目的在于构建一个被节点均等分的圆环,当一个任务到来,落在区间的某一个点上时,向上取节点为执行节点,如图中,Node3将成为任务A的执行节点。
优势:一致性Hash算法的优势在于节点的动态增减对任务的影响小,如图,如果将节点Node3断开,那么此时的任务A将被Node4执行。
缺点:负载的均衡性不好保障,100任务到来,我们如何能够保证100个任务能够均匀的散落这四个区间上?有同学可能会说给任务按照节点数量取模,那这样不就又回到类似轮询的负载策略了吗?
一致性Hash的负载均衡问题还是要靠概率方法解决,如下。
带虚拟节点的一致性Hash算法
虚拟节点通过扩大节点数量来解决均衡问题。
如图所示,这是将3个节点数量扩大3倍,可以看出任务A落在某个节点的随机性将极大的增加,如果我们将节点数量无限制扩大,理论上就可以得到一个完全均衡的分布。
xxl-job正是使用这种方式来实现:
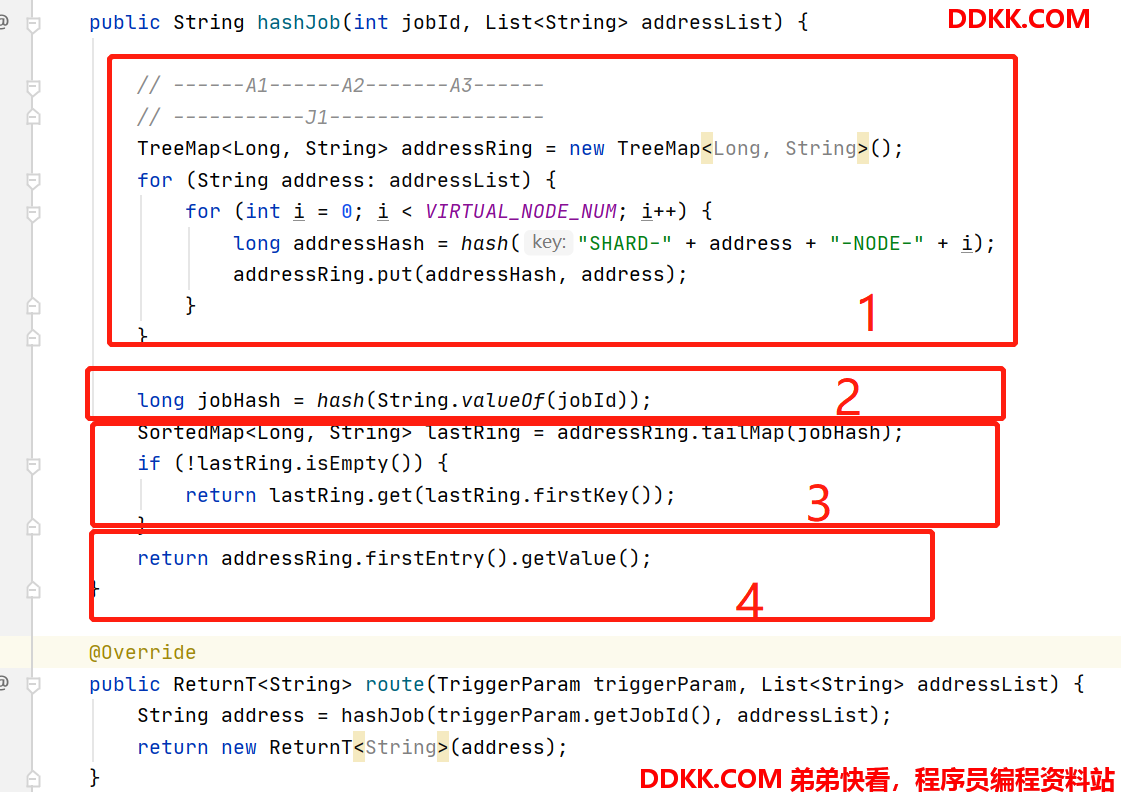
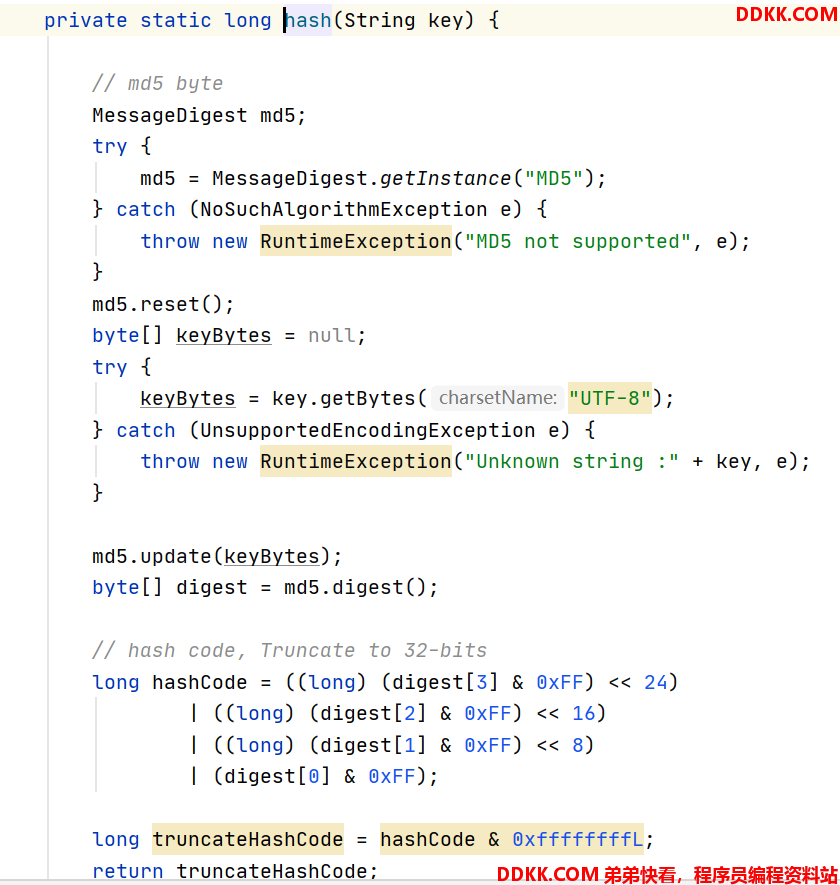
- 每个节点扩增100倍,放到环里面。这里细看hash方法,使用了md5hash,并且控制了结果值在0-2的32次方之间,也就是这个环的范围。
- jobId取hash,得到jobId在环上的位置
- tailMap方法获取的是大于等于这个key的键值对,也就是上图中任务A后面的所有地址,取这些地址中的第一个,也就是任务A向上取到的Node3。
- 如果tailMap方法没有取到值,说明当前任务在环上的位置已经接近最大范围,因为这里是一个圆,所以向上取就会继续从0开始找下一个节点,也就是整个环的第一个节点。
LRU与LFU
LRU: 最近最久未使用,这里使用了LinkedHashMap的accessOrder(访问后排序)功能实现,比较简单,不再赘述。

LFU:最近最不常使用
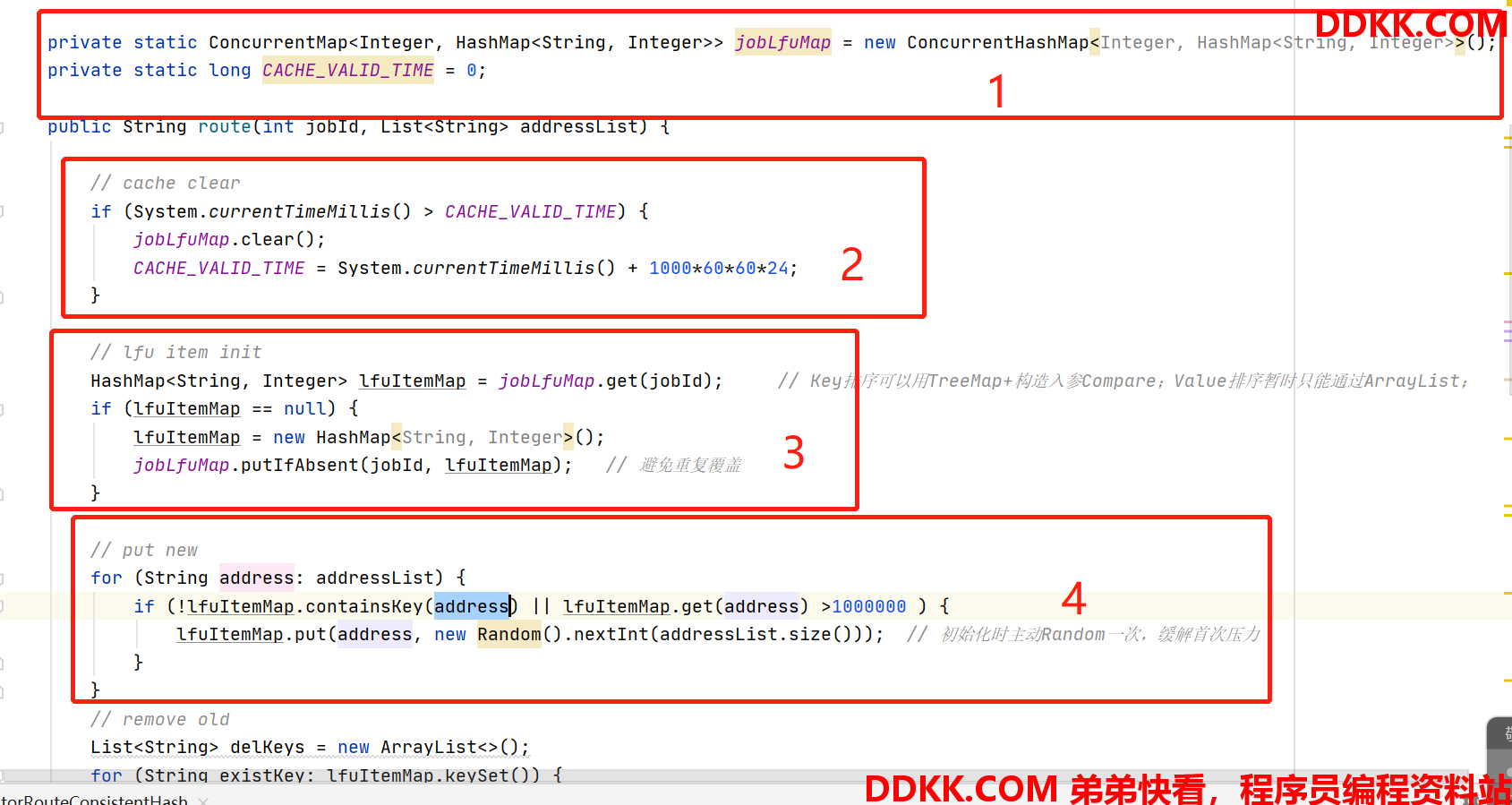
- 定义lfu缓存:
<jobId,<地址,被访问次数>>` - 每天一次,清理lfu缓存
- 初始化当前job的lfu缓存
- 增加该job可以使用的地址,这里默认value不是0而是随机数的原因,是为了防止新加入的节点接收到的请求太多。
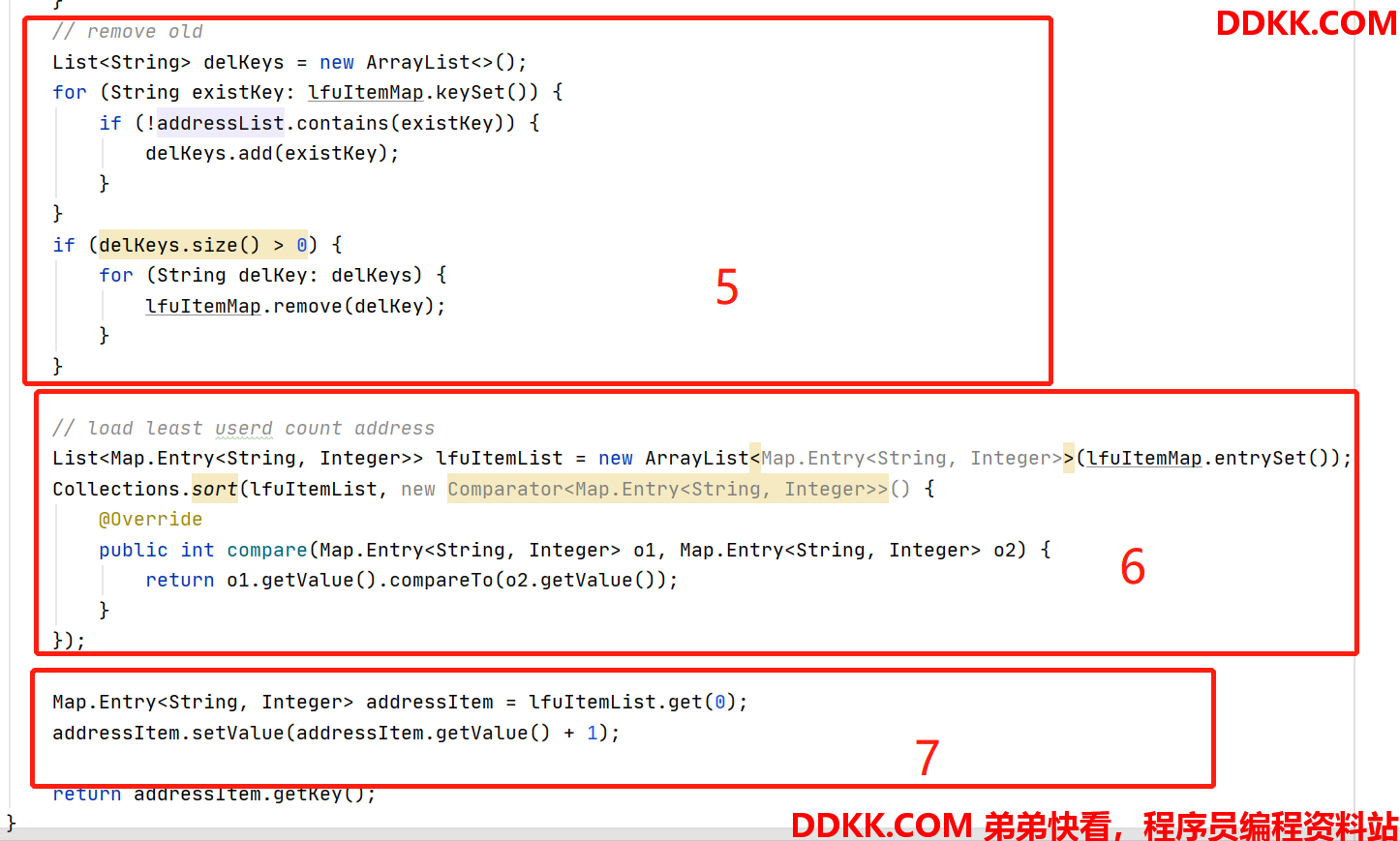
- 清理掉已经不使用的地址
- 借用arraylist的排序,找到value最小的那个地址
- 返回结果
故障转移与忙碌转移
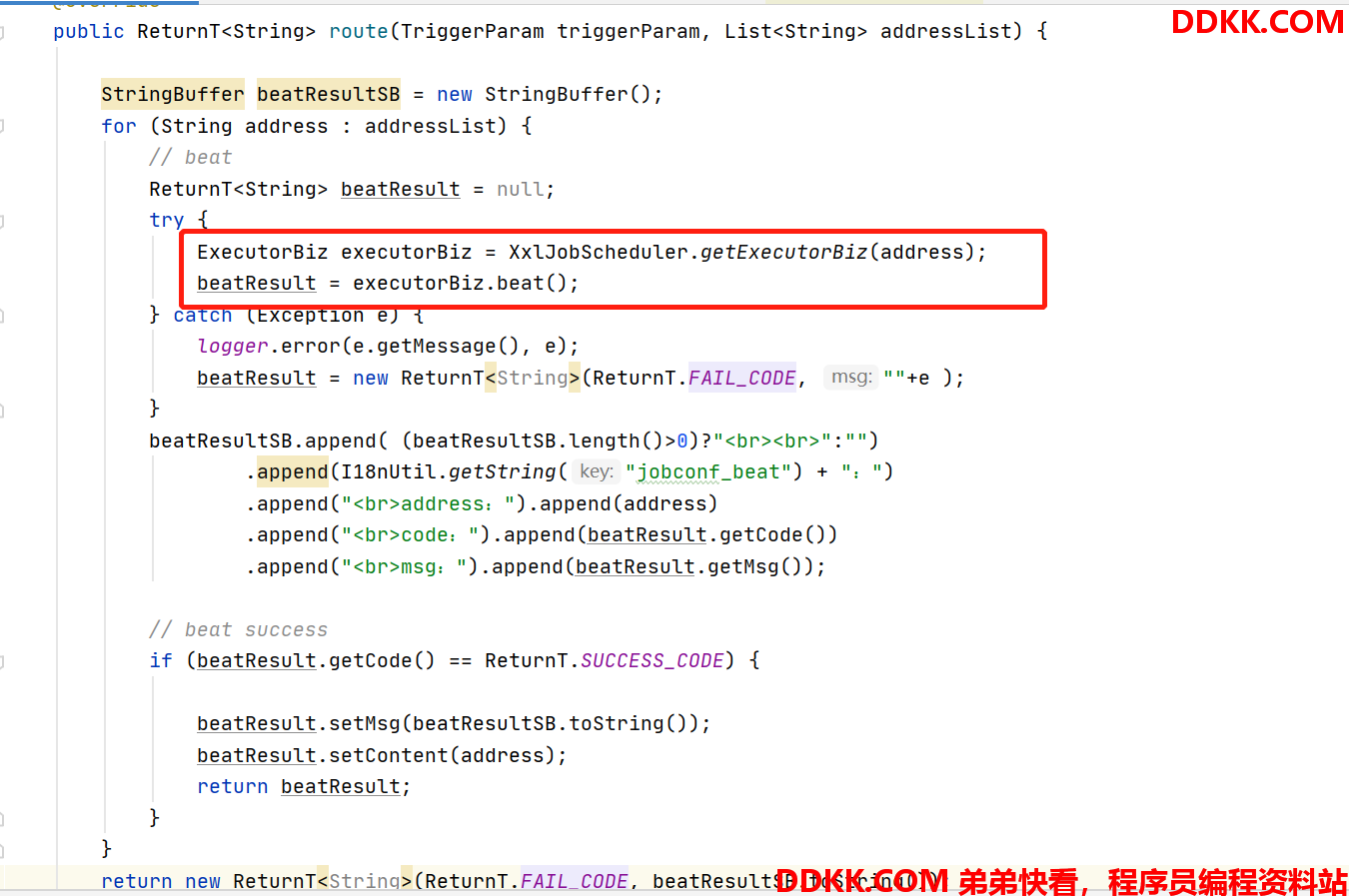
故障转移: 如果机器还活着,就用。
如图代码所示,逻辑很直接,对地址进行for循环,每一个进行心跳检测,只要有一个心跳成功就使用,显然这个逻辑会一直使用活着的第一个节点。
忙碌转移: 与故障转移唯一的区别,是不调用心跳检测接口,而是是否空闲idleBeat接口。
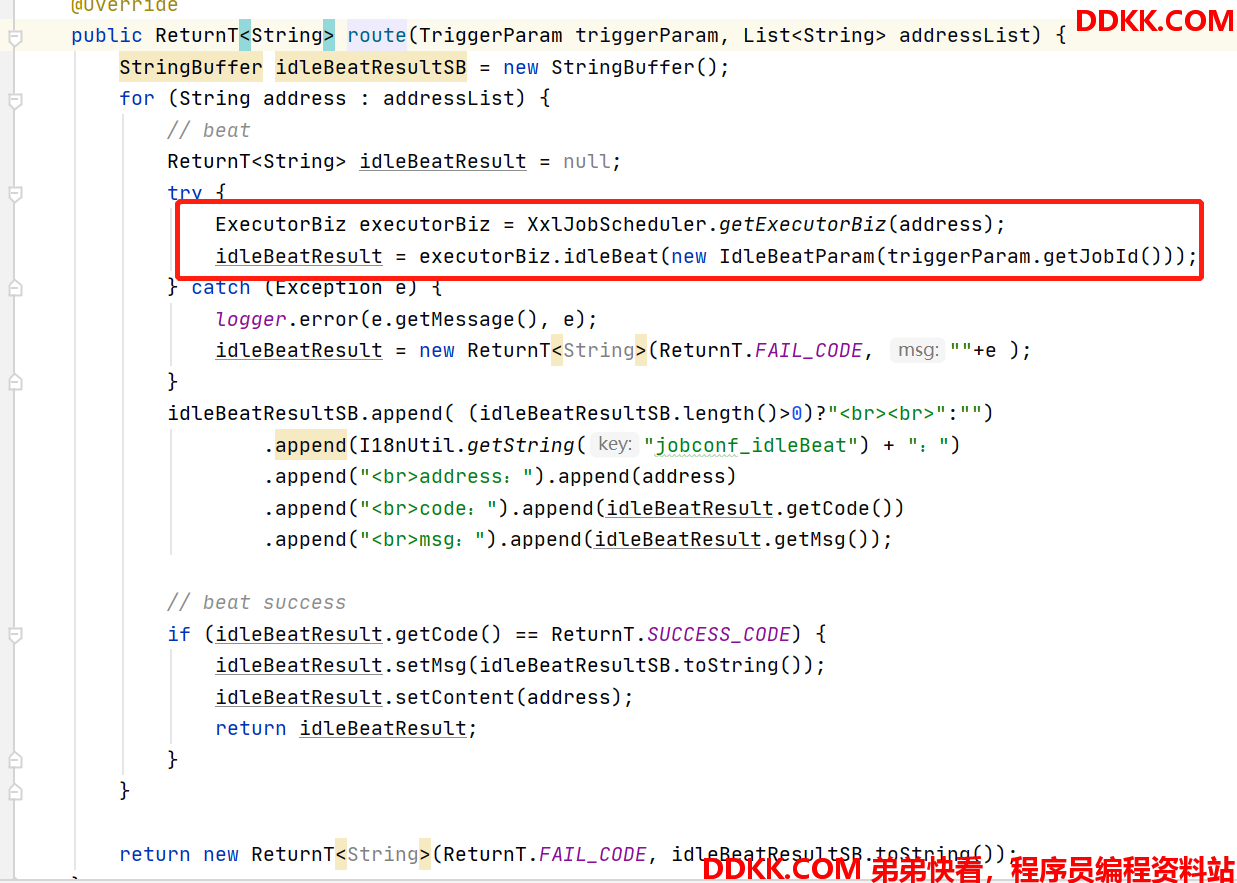
我们看一下执行器端idleBeat的实现:
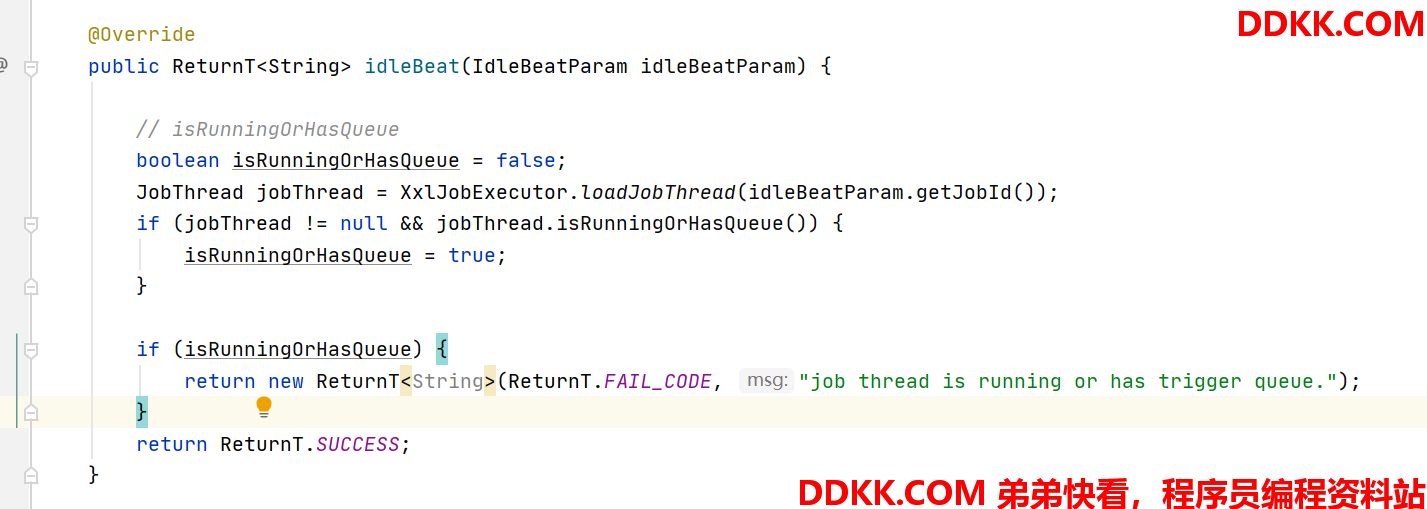
执行器端缓存了jobId与线程实例的关系,这里直接判断了对应线程实例是否在执行任务,是否还有未执行的任务,都没有才认为是空闲的。