Zipkin是一个分布式跟踪系统。它有助于收集解决服务体系结构中的延迟问题所需的计时数据。功能包括此数据的收集和查找。
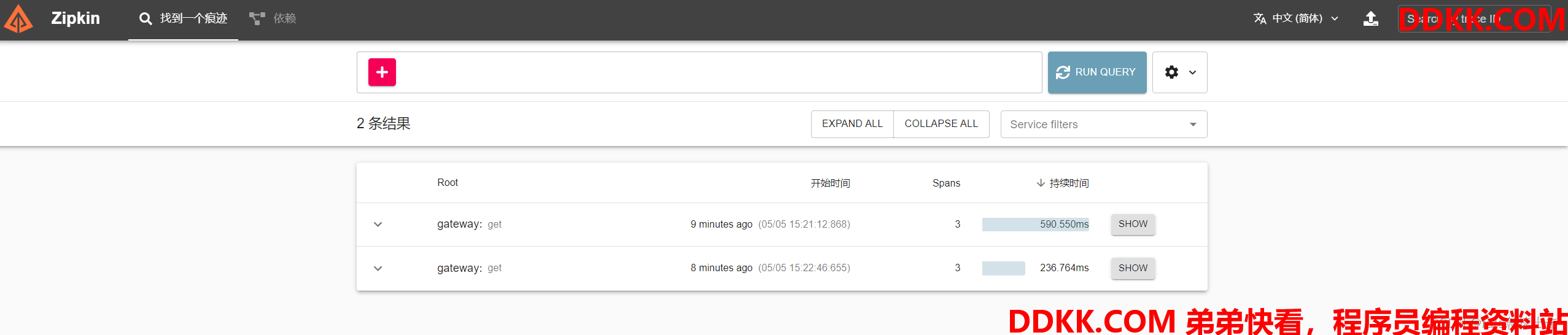
如果日志文件中有跟踪 ID,则可以直接跳转到该 ID。否则,您可以根据服务、操作名称、标签、持续时间等属性进行查询。将为您汇总一些有趣的数据,例如在服务中花费的时间百分比以及操作是否失败。
Zipkin是一个分布式跟踪系统。它有助于收集解决服务体系结构中的延迟问题所需的计时数据。功能包括此数据的收集和查找。
如果日志文件中有跟踪 ID,则可以直接跳转到该 ID。否则,您可以根据服务、操作名称、标签、持续时间等属性进行查询。将为您汇总一些有趣的数据,例如在服务中花费的时间百分比以及操作是否失败
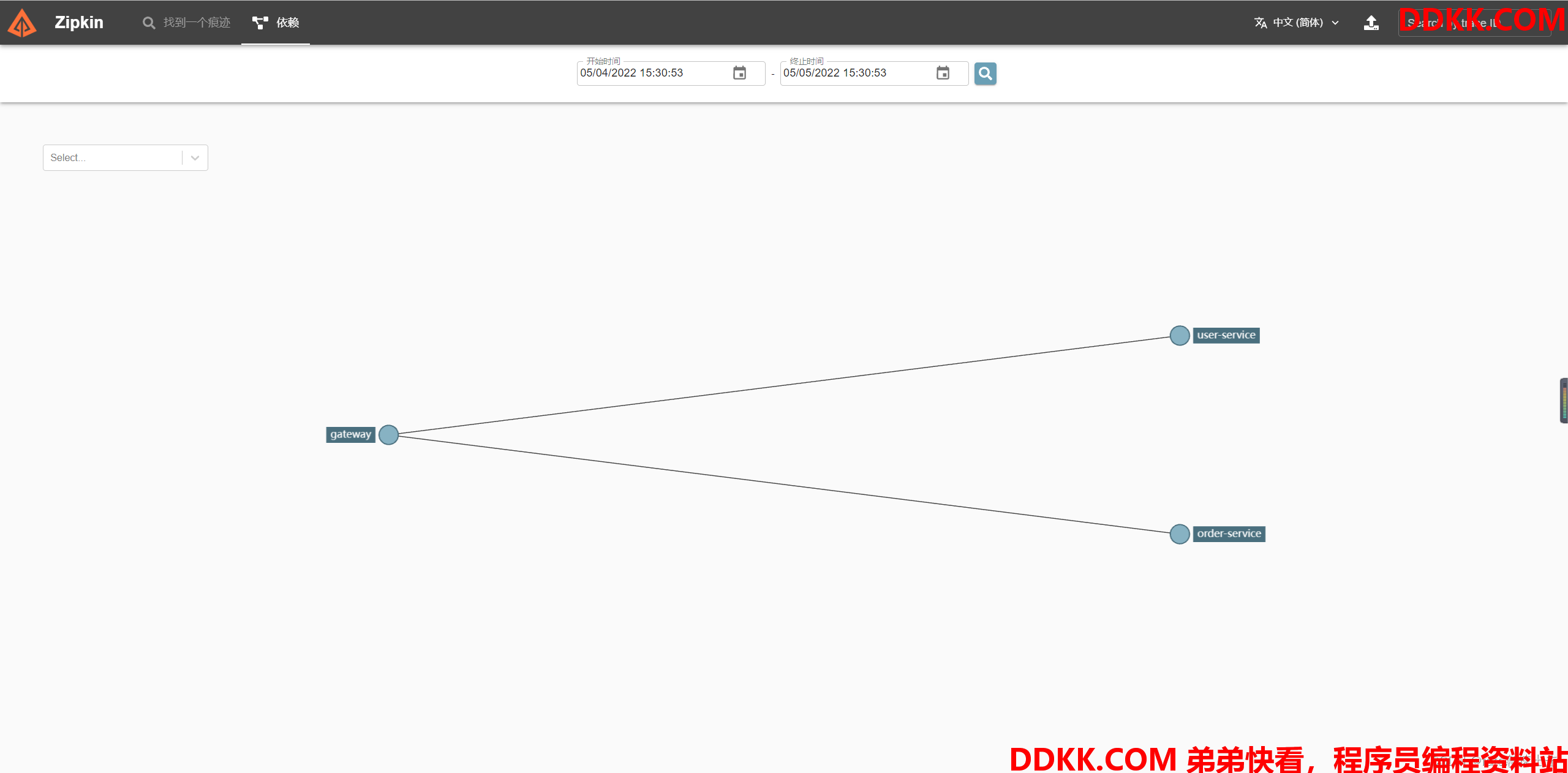
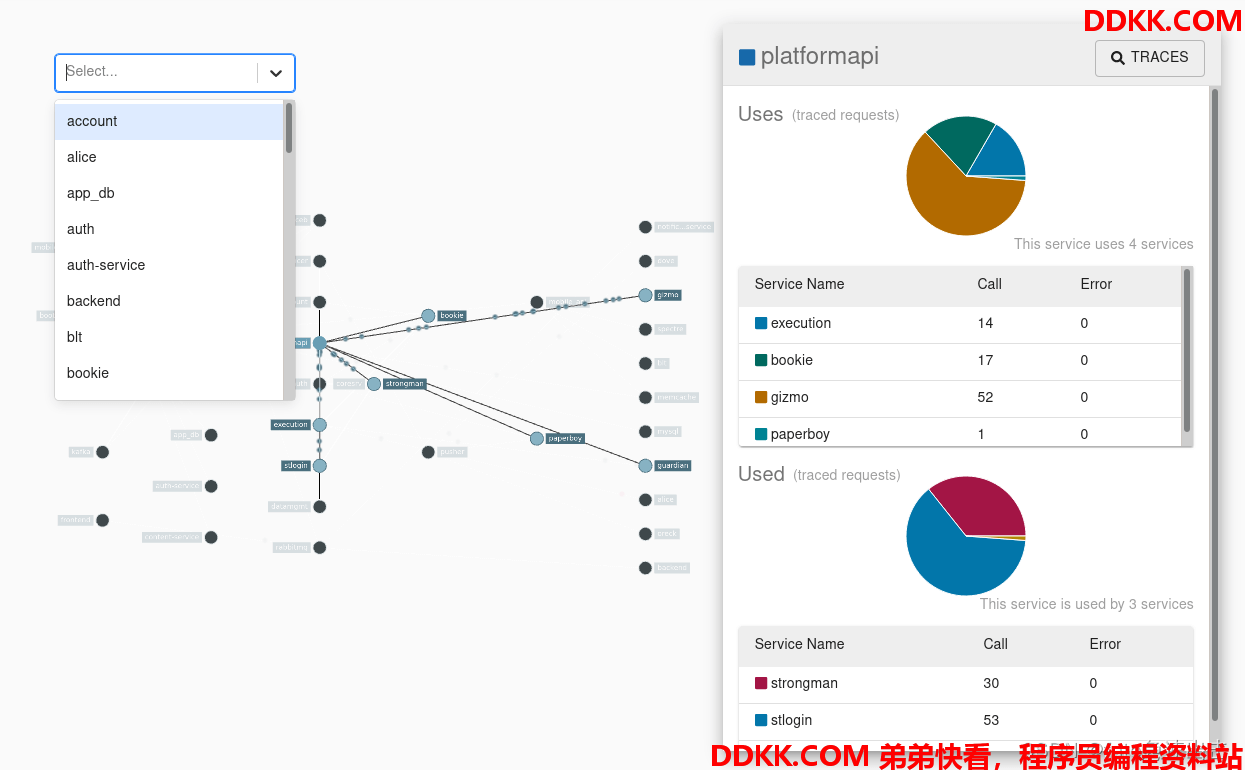
Zipkin UI 还提供了一个依赖关系图,显示通过每个应用程序跟踪的请求数。这对于识别聚合行为(包括错误路径或对已弃用服务的调用)很有帮助。
1、 zipkin下载安装
1.1、zipkin下载
1.2、zipkin建表语句
--
-- Copyright 2015-2019 The OpenZipkin Authors
--
-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except
-- in compliance with the License. You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software distributed under the License
-- is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express
-- or implied. See the License for the specific language governing permissions and limitations under
-- the License.
--
CREATE TABLE IF NOT EXISTS zipkin_spans (
trace_id_high BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
trace_id BIGINT NOT NULL,
id BIGINT NOT NULL,
name VARCHAR(255) NOT NULL,
remote_service_name VARCHAR(255),
parent_id BIGINT,
debug BIT(1),
start_ts BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',
duration BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query',
PRIMARY KEY (trace_id_high, trace_id, id)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_spans ADD INDEX(trace_id_high, trace_id) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(name) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(remote_service_name) COMMENT 'for getTraces and getRemoteServiceNames';
ALTER TABLE zipkin_spans ADD INDEX(start_ts) COMMENT 'for getTraces ordering and range';
CREATE TABLE IF NOT EXISTS zipkin_annotations (
trace_id_high BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
trace_id BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',
span_id BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',
a_key VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',
a_value BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',
a_type INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',
a_timestamp BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',
endpoint_ipv4 INT COMMENT 'Null when Binary/Annotation.endpoint is null',
endpoint_ipv6 BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',
endpoint_port SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',
endpoint_service_name VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_annotations ADD UNIQUE KEY(trace_id_high, trace_id, span_id, a_key, a_timestamp) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(trace_id_high, trace_id, span_id) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(trace_id_high, trace_id) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(endpoint_service_name) COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(a_type) COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(a_key) COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(trace_id, span_id, a_key) COMMENT 'for dependencies job';
CREATE TABLE IF NOT EXISTS zipkin_dependencies (
day DATE NOT NULL,
parent VARCHAR(255) NOT NULL,
child VARCHAR(255) NOT NULL,
call_count BIGINT,
error_count BIGINT,
PRIMARY KEY (day, parent, child)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
1.3、zipkin启动
java -jar zipkin-server-2.23.16-exec.jar --storage_type=mysql --MYSQL_DB=zipkin --MYSQL_USER=root --MYSQL_PASS=123456 --MYSQL_HOST=localhost --MYSQL_TCP_PORT=3306
2、zipkin整合SpringCloud
2.1、添加依赖
brave-instrumentation-dubbo 这里我用的版本是5.13.7
<!-- zipkin -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
<version>2.2.8.RELEASE</version>
</dependency>
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave-instrumentation-dubbo</artifactId>
</dependency>
2.2、修改配置文件
因为我的项目的配置中心是nacos所以我直接在nacos新建一个zipkin.yaml
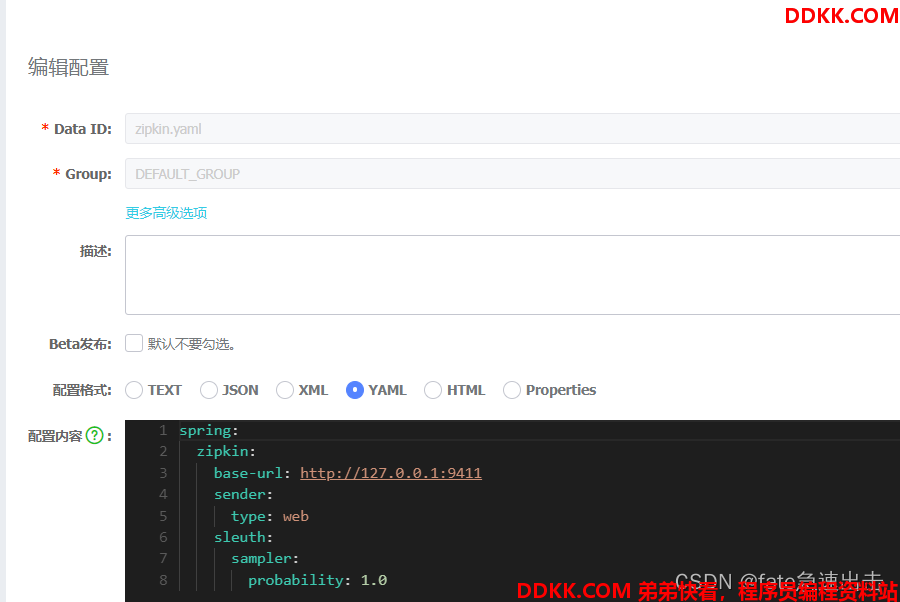
spring:
zipkin:
base-url: http://127.0.0.1:9411 zipkin server 的地址
sender:
type: web 如果ClassPath里没有kafka, active MQ, 默认是web的方式
sleuth:
sampler:
probability: 1.0 100%取样,生产环境应该低一点,用不着全部取出来
bootstrap.yml中追加
extension-configs[5]:
data-id: zipkin.yaml
group: DEFAULT_GROUP
refresh: false
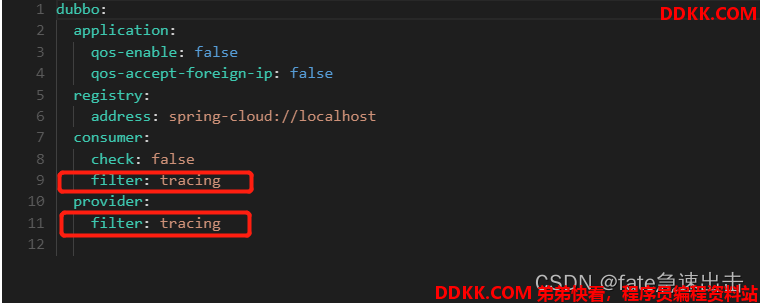
2.3、dubbo配置修改
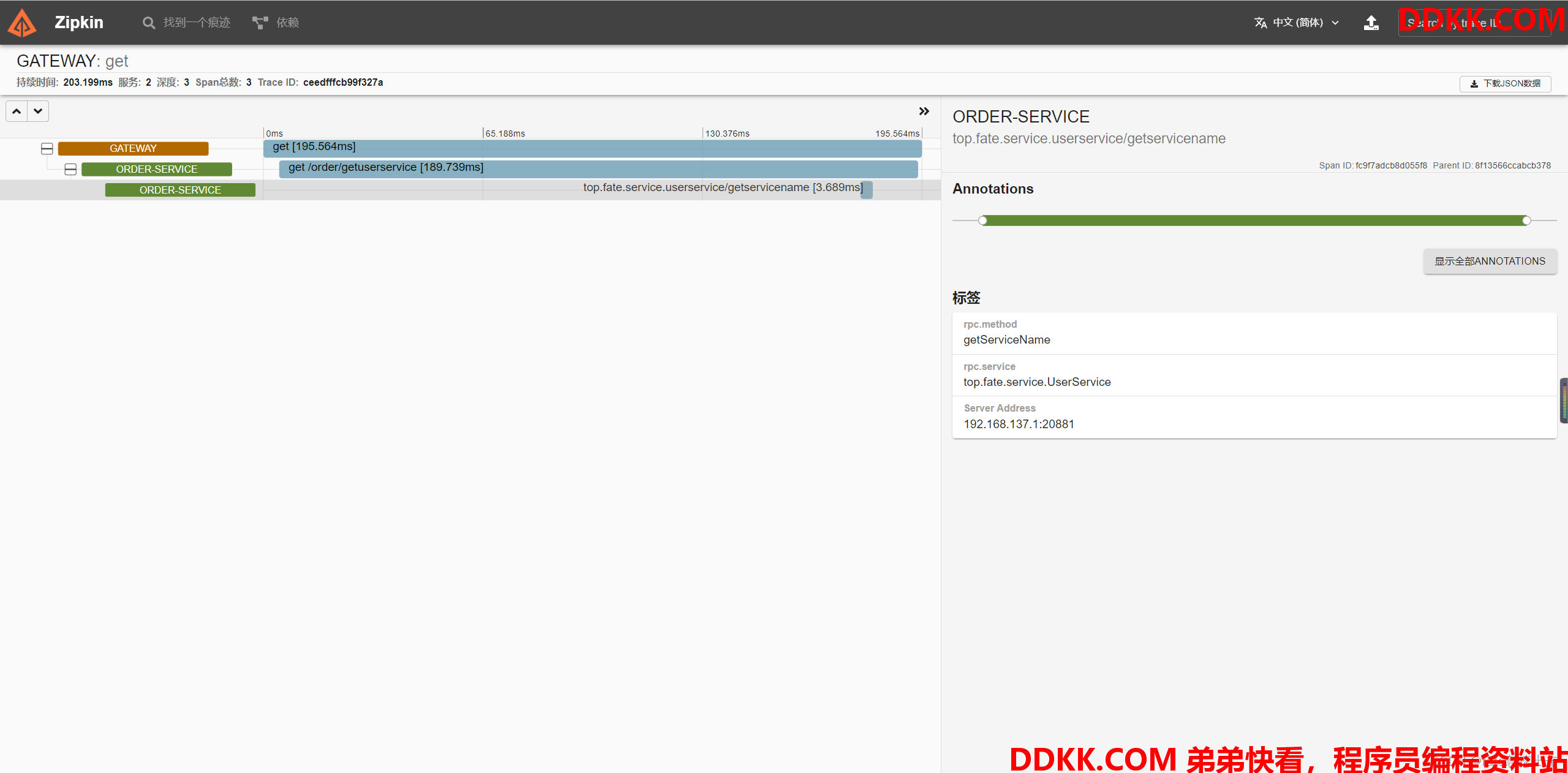
添加红色方框配置,即可在zipkin中观察到dubbo调用
启动微服务
2.4、测试
这里我通过网关分别调用一下order-service和user-service