一、Zipkin概述
sleuth分布式请求链路跟踪,可以得知微服务之间的调用链路,由于监控信息只能输出到控制台不方便查看,因此我们需要一个图形化的工具zipkin。zipkin是twitter开源的分布式跟踪系统,主要用来收集系统的实时数据,从而追踪系统的调用问题。
官网:https://zipkin.io/
完整的调用链路(sleuth结合zipkin 底层监控):
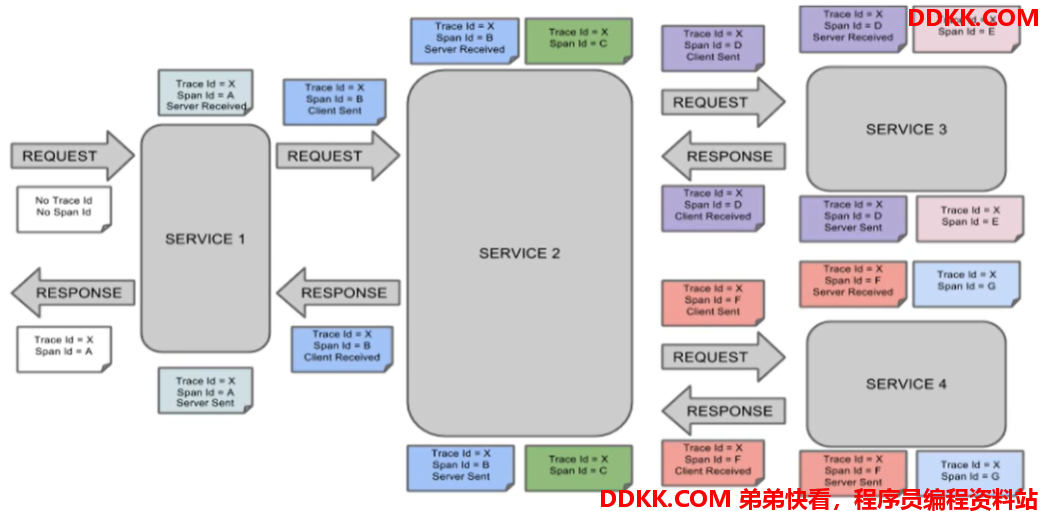
上图解释:
1、 一条链路通过TraceId唯一标识,Span标识发起的请求信息,各span通过parentid关联起来;
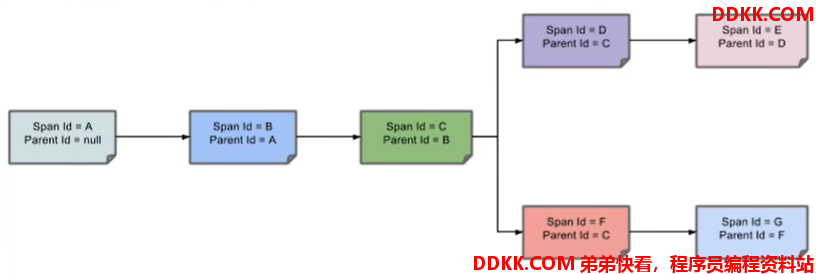
2、 整个链路的依赖关系如下:

二、Docker安装Zipkin
1、 拉取最新镜像;
docker pull openzipkin/zipkin
2、 运行镜像;
普通运行
`docker run -d -p 9411:9411 --name zipkin openzipkin/zipkin`
docker-compose 运行,新建docker-compose.yml,加入以下内容
version: '2'
services:
# The zipkin process services the UI, and also exposes a POST endpoint that
# instrumentation can send trace data to. Scribe is disabled by default.
zipkin:
image: openzipkin/zipkin
container_name: zipkin
environment:
- STORAGE_TYPE=mysql
# Point the zipkin at the storage backend
- MYSQL_DB=zipkin
- MYSQL_USER=root
- MYSQL_PASS=123456
- MYSQL_HOST=192.168.1.8
- MYSQL_TCP_PORT=3306
# Uncomment to enable scribe
# - SCRIBE_ENABLED=true
# Uncomment to enable self-tracing
# - SELF_TRACING_ENABLED=true
# Uncomment to enable debug logging
# - JAVA_OPTS=-Dlogging.level.zipkin=DEBUG -Dlogging.level.zipkin2=DEBUG
ports:
# Port used for the Zipkin UI and HTTP Api
- 9411:9411
# Uncomment if you set SCRIBE_ENABLED=true
# - 9410:9410
#networks:
# - default
# - my_net创建网路 docker network create my_net 删除网络 docker network rm my_net
#networks:
#my_net:
#external: true
守护进程启动: cd 到docker-compose.yml目录下,docker-compose up -d
停止:docker-compose stop
mysql脚本下载地址
https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql/src/main/resources/mysql.sql
三、SpringCloud整合Zipkin
支付服务和订单服务引入以下pom依赖和yml配置。
1、 引入pom依赖;
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
<version>2.2.8.RELEASE</version>
</dependency>
由于spring-cloud-starter-zipkin同时包含了sleuth,因此可以省略spring-cloud-starter-sleuth的引用。
1、 添加zipkin相关配置;
#服务追踪
zipkin:
base-url: http://ip:9411/ zipkin服务器的地址
discovery-client-enabled: false 关闭服务发现,否则spring cloud会把zipkin的url当作服务名称
sender:
type: web设苦使用http的方式传输数据
sleuth:
traceId128: true
sampler:
probability: 1.0抽样采集率为100%,默认为0.1 ,即10%
propagation-keys: user_name
1、 业务类Controller添加方法;
- 支付服务8001业务类Controller添加以下方法:
@GetMapping("/payment/zipkin")
public String paymentZipkin() {
return "hi ,i'am paymentzipkin server fall back,welcome to here, O(∩_∩)O哈哈~";
}
- 订单服务80的Controller中添加以下方法:
@GetMapping("zipkin")
public String paymentZipkin() {
String result = restTemplate.getForObject(PAYMENT_URL + "/payment/zipkin", String.class);
return result;
}
1、 测试;
依次启动注册中心eureka7001,支付服务8001,订单服务80。
使用postman发送多次请求:http://localhost:89/consumer/payment/zipkin;
访问http://your_host:9411/zipkin/
注意:若使用云服务器记得关闭防火墙和设置安全组。
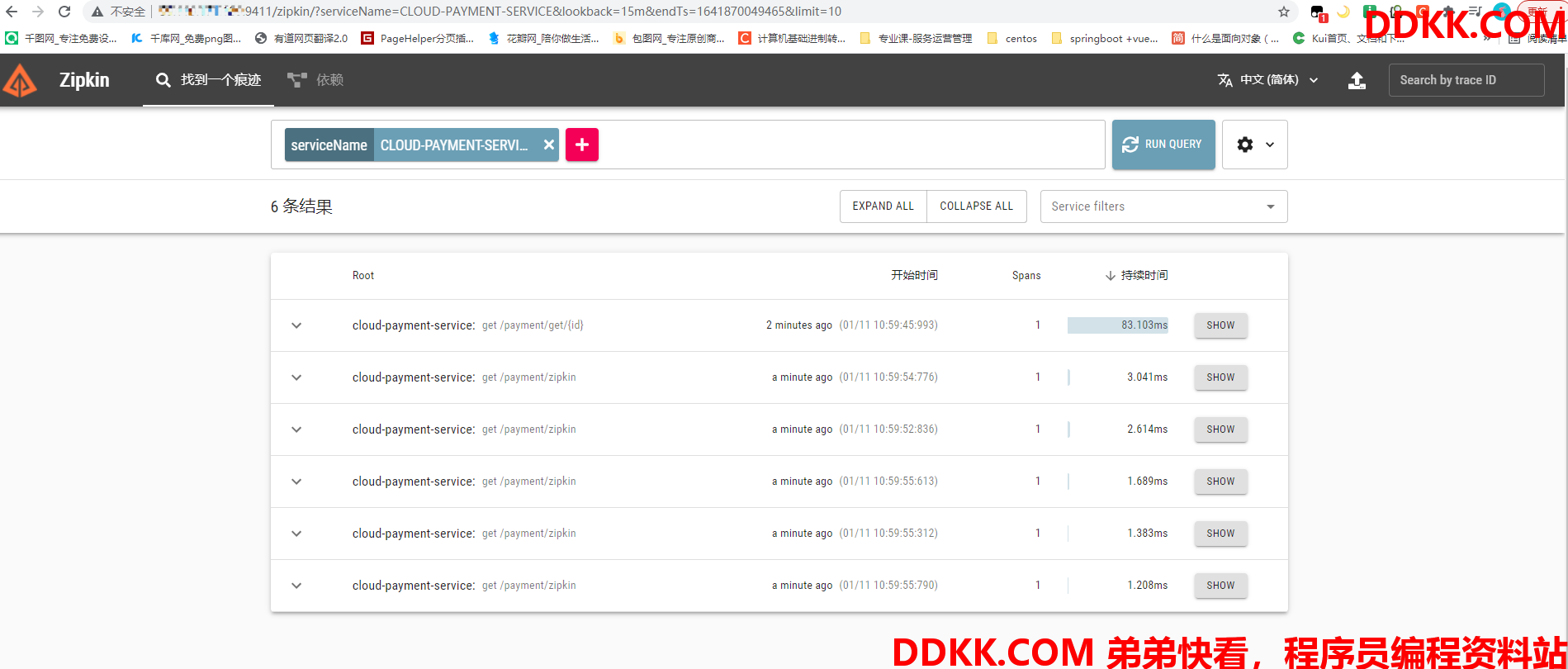
服务调用链路追踪信息统计:
四、Zipkin数据持久化
Zipkin存储原则:默认将监控数据存储在内存中,如果Zipkin挂了或者重启,监控数据就会消失。所以要适应生产的需要,就要实现监控数据的持久化。而想要实现实现持久化,自然就是要将数据存储到数据库。
Zipkin支持将数据存储到:
- 内存(默认,不适用于生产)
- MySQL(当数据量大时,查询较慢,不建议使用)
- ElasticSearch(建议使用)
- Cassandra(Twitter官方使用,国内使用的公司较少,相关文档较少)
Zipkin数据持久化官网文档:https://github.com/openzipkin/zipkin#storage-component
ElasticSearch作为Zipkin存储数据库的官方文档如下:
- elsticsearch-storage: https://github.com/openzipkin/zipkin/tree/master/zipkin-server#elasticsearch-storage
- zipkin-storage/elasticsearch:https://github.com/openzipkin/zipkin/tree/master/zipkin-storage/elasticsearch
通过docker安装:
docker run --env STORAGE_TYPE=elasticsearch --env ES_HOSTS=192.168.56.10:9200
openzipkin/zipkin-dependencies
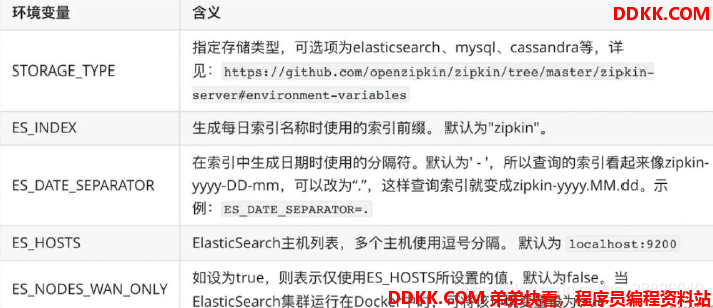
ElasticSearch环境变量:
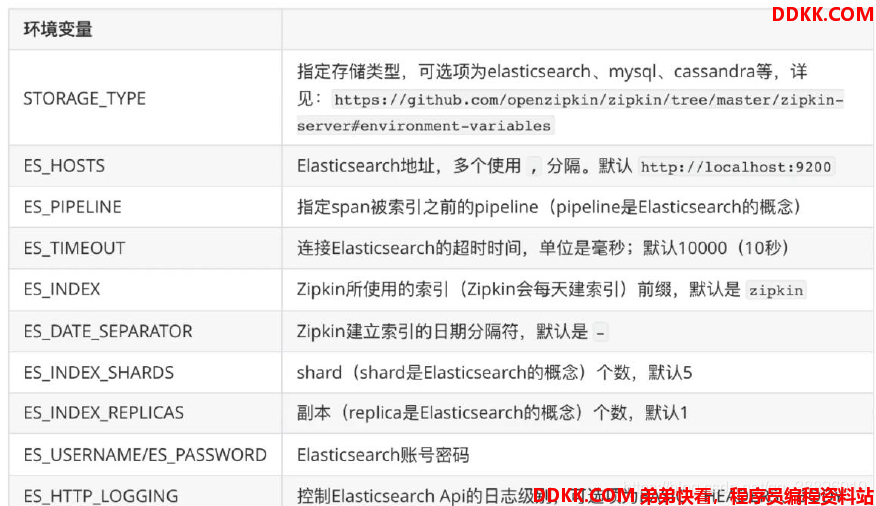
Zipkin支持的ElasticSearch环境变量: