1 节点服役和退役
1.1 服役新节点
新节点准备:
1、 关闭hadoop104,并右键执行克隆操作。
2、 开启hadoop105,并修改 IP 地址为105。
vim /etc/sysconfig/network-scripts/ifcfg/ens33
3、 在 hadoop105 上,修改主机名称为hadoop105。
vim /etc/hostname
4、 重新启动hadoop104、hadoop105。
5、 修改haodoop105 中 kafka 的 broker.id 为 3。
6、 删除hadoop105 中 kafka 下的 datas 和 logs。
7、 启动hadoop102、hadoop103、hadoop104 上的 kafka 集群。
zk.sh start
kf.sh start
8、 单独启动hadoop105 中的 kafka。
bin/kafka-server-start.sh -daemon ./config/server.properties
执行负载均衡操作:
1、 创建一个要均衡的主题。
vim topics-to-move.json
{
"topics": [
{
"topic": "first"}
],
"version": 1
}
2、 生成一个负载均衡的计划。
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2,3" --generate
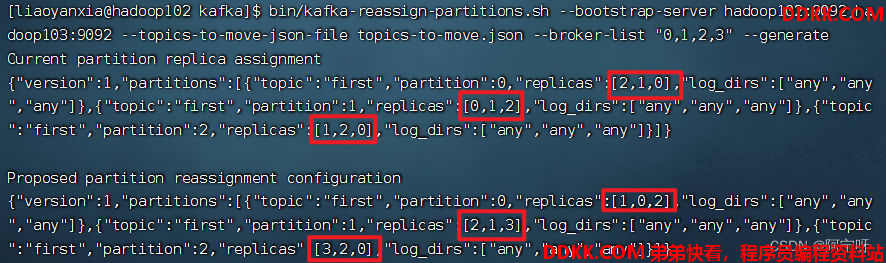
3、 创建副本存储计划(所有副本存储在 broker0、broker1、broker2、broker3 中)。
vim increase-replication-factor.json
输入以下内容:

4、 执行副本存储计划。
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --reassignment-json-file increase-replication-factor.json --execute
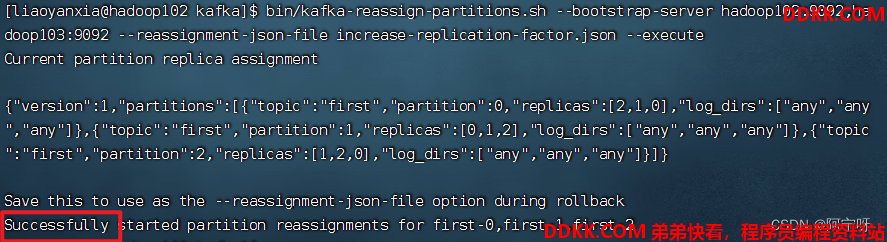
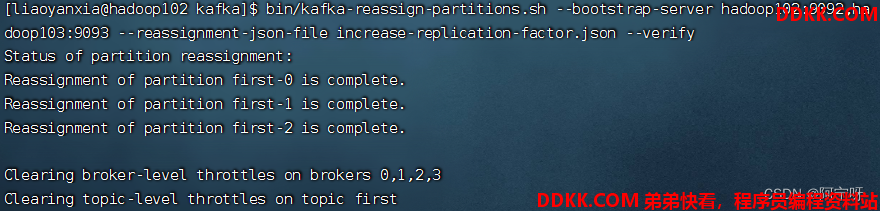
5、 验证副本存储计划。
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --reassignment-json-file increase-replication-factor.json --verify

1.2 退役旧节点
执行负载均衡操作:先按照退役一台节点,生成执行计划,然后按照服役时操作流程执行负载均衡。
1、 创建一个要均衡的主题。
vim topics-to-move.json
{
"topics": [
{
"topic": "first"}
],
"version": 1
}
2、 创建执行计划。
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2" --generate
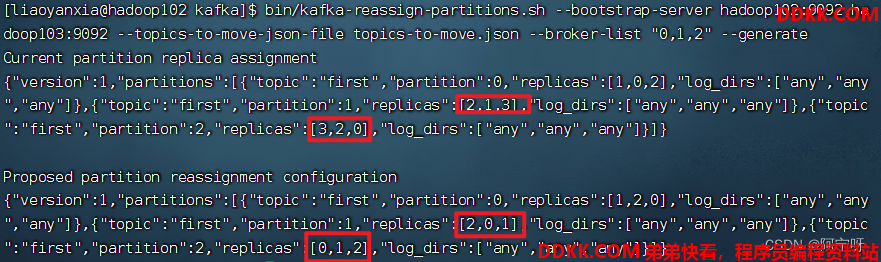
3、 创建副本存储计划(所有副本存储在 broker0、broker1、broker2 中)。
vim increase-replication-factor.json
输入以下内容:

4、 执行副本存储计划。
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --reassignment-json-file increase-replication-factor.json --verify
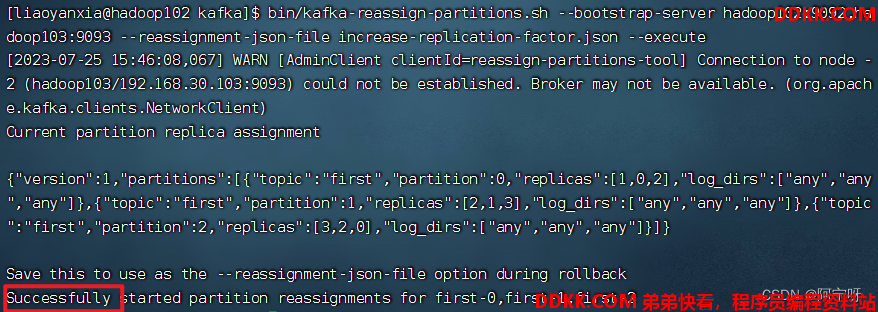
5、 验证副本存储计划。
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --reassignment-json-file increase-replication-factor.json --verify
执行停止命令:
[lyx@hadoop105 kafka]$ bin/kafka-server-stop.sh
2 手动调整分区副本存储
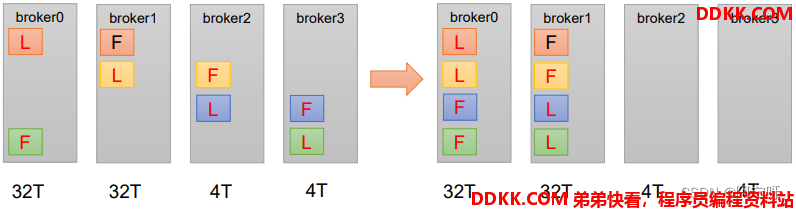
在生产环境中,每台服务器的配置和性能不一致,但是Kafka只会根据自己的代码规则创建对应的分区副本,就会导致个别服务器存储压力较大。所有需要手动调整分区副本的存储。
需求:
创建一个新的topic,4个分区,两个副本,名称为third。将该topic的所有副本都存储到broker0和broker1两台服务器上。
步骤:
1、 创建一个新的topic,为third。
bin/kafka-topics.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --create --partitions 4 --replication-factor 2 --topic third
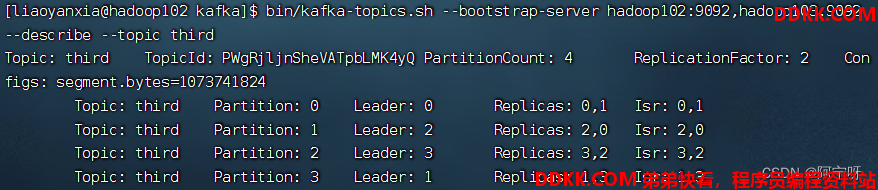
2、 查看分区副本存储情况。
bin/kafka-topics.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --describe --topic third
3、 创建副本存储计划(所有副本都指定存储在broker0、broker1)。
vim increase-replication-factor.json
#输入以下内容
{
"version":1,
"partitions":[{
"topic":"third","partition":0,"replicas":[0,1]},
{
"topic":"third","partition":1,"replicas":[0,1]},
{
"topic":"third","partition":2,"replicas":[1,0]},
{
"topic":"third","partition":3,"replicas":[1,0]}]
}
4、 执行副本存储计划。
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --reassignment-json-file increase-replication-factor.json --execute
5、 验证副本存储计划。
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --reassignment-json-file increase-replication-factor.json --verify
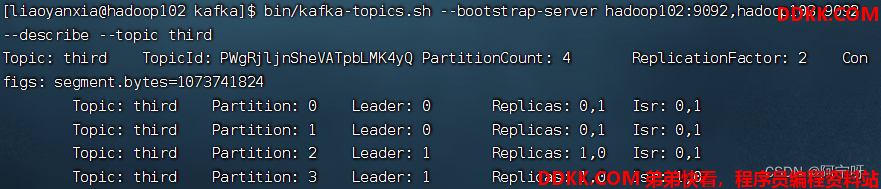
6、 查看分区副本存储情况。
bin/kafka-topics.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --describe --topic third
3 Leader Partition负载平衡
正常情况下,Kafka本身会自动把Leader Partition均匀分散在各个机器上,来保证每台机器的读写吞吐量都是均匀的。但是如果某些broker宕机,会导致Leader Partition过于集中在其他少部分几台broker上,这会导致少数几台broker的读写请求压力过高,其他宕机的 broker重启之后都是follower partition,读写请求很低,造成集群负载不均衡。
解决方法:
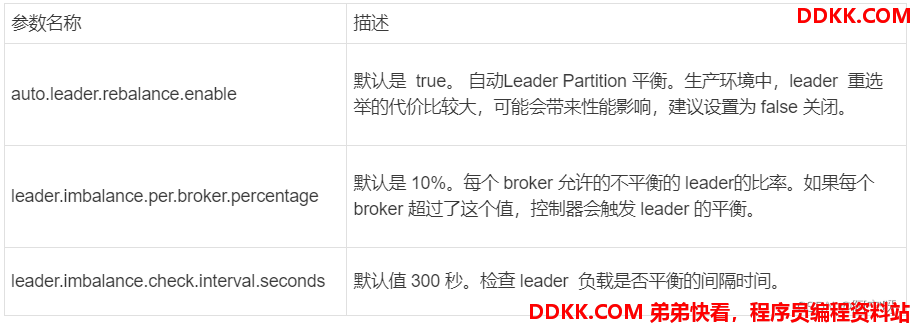
例如:

对于broker0节点,分区2的AR优先副本是0节点,但0节点不是Leader节点,所以不平衡数+1,AR副本总数为4,所以broker0节点不平衡率为1/4>10%,需要平衡。
对于broker2节点,分区3的AR优先副本是2节点,但2节点不是Leader节点,所以不平衡数+1,AR副本总数为4,所以broker2节点不平衡率为1/4>10%,需要平衡。
对于broker3节点,分区0的AR优先副本是3节点,但3节点不是Leader节点,所以不平衡数+1,AR副本总数为4,所以broker3节点不平衡率为1/4>10%,需要平衡。
对于broker1节点,分区1的AR优先副本是1节点,且1节点是Leader节点,所以不平衡数为0,broker1节点不平衡率为0,不需要平衡。
PS:不要频繁触发负载平衡操作,因为会浪费大量进程资源。
4 增加副本因子
在生产环境当中,由于某个主题的重要等级需要提升,我们考虑增加副本。副本数的增加需要先制定计划,然后根据计划执行。
1、 创建topic
bin/kafka-topics.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --create --partitions 3 --replication-factor 1 --topic fourth

2、 手动增加副本存储,创建副本存储计划(所有副本都指定存储在 broker0、broker1、broker2 中)。
vim increase-replication-factor.json
#输入以下内容
{
"version":1,
"partitions":[{
"topic":"fourth","partition":0,"replicas":[0,1,2]},
{
"topic":"fourth","partition":1,"replicas":[0,1,2]},
{
"topic":"fourth","partition":2,"replicas":[0,1,2]}]
}
3、 执行副本计划。
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --reassignment-json-file increase-replication-factor.json --execute
