1 文件存储
1.1 文件存储机制
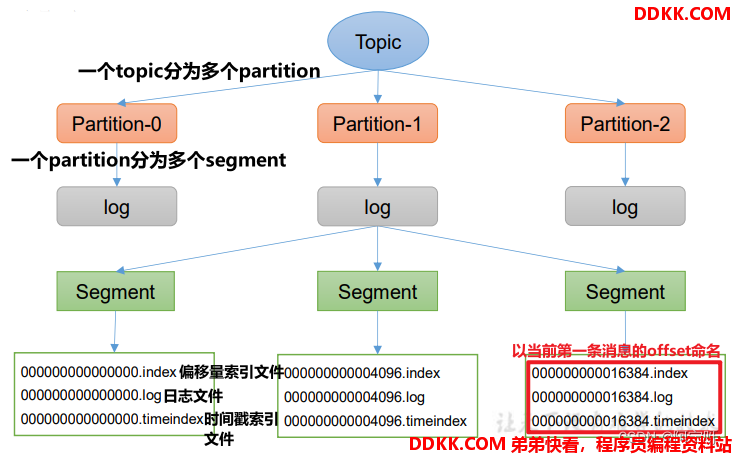
Topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的是Producer生产的数据。
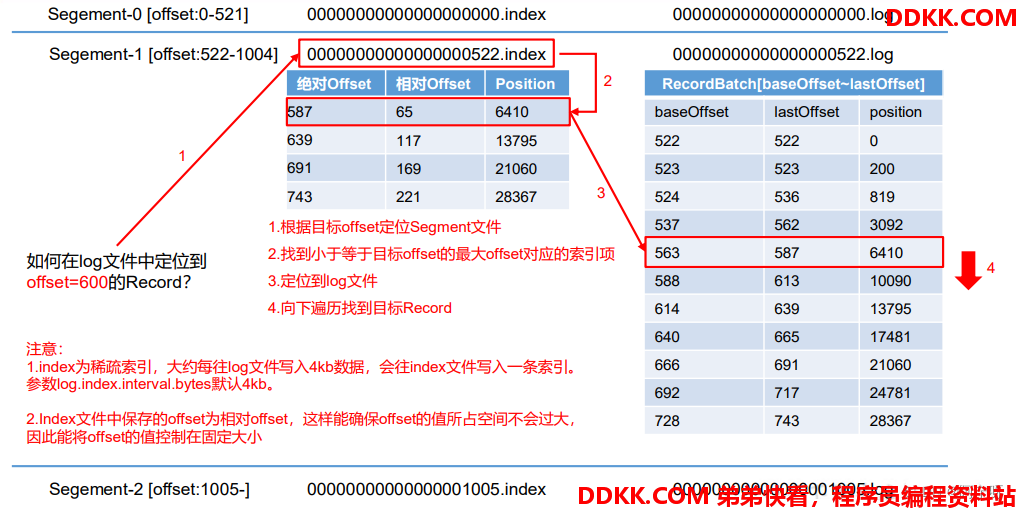
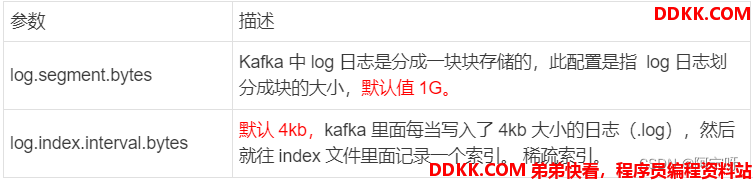
Producer生产的数据会被不断追加到该log文件末端,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment。
每个segment包括:“.index”文件、“.log”文件和.timeindex等文件。这些文件位于一个文件夹下。
文件夹的命名规则为:topic名称+分区序号,例如:first-0。
topic数据存储位置:
1、 启动生产者并发送消息。
bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092,hadoop103:9092 --topic first
> hello
2、 查看hadoop102的/opt/module/kafka/datas/first-0路径上的文件。

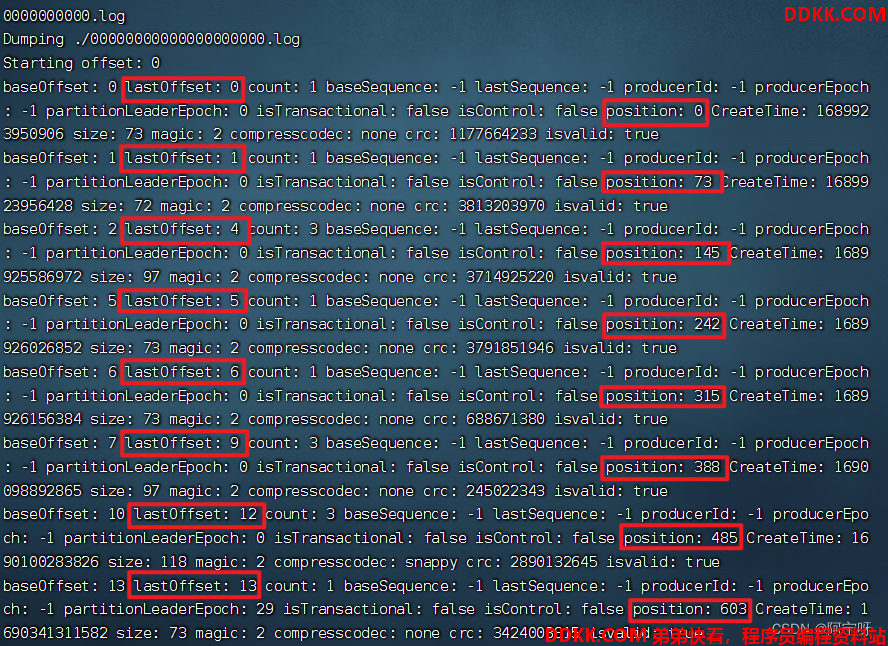
3、 通过工具查看 index 和 log 信息。
kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.index

日志参数配置:
1.2 文件清理策略
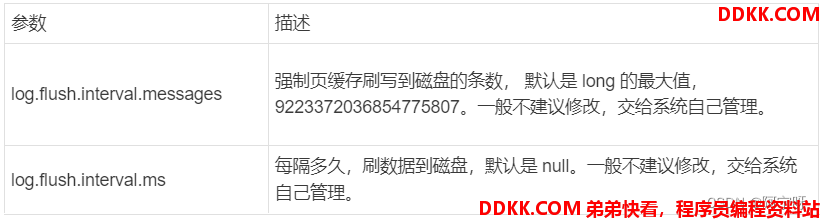
Kafka 中默认的日志保存时间为 7 天,通过调整如下参数修改保存时间:
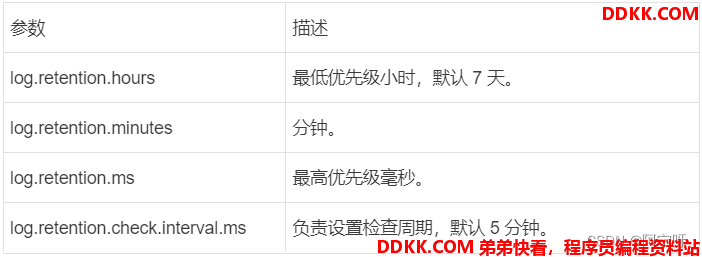
日志超时时,Kafka 中提供的日志清理策略有 delete 和 compact 两种。
1、 delete 日志删除:将过期数据删除。

(i)基于时间:默认打开。以 segment 中所有记录中的最大时间戳作为该文件时间戳。
(ii)基于大小:默认关闭。超过设置的所有日志总大小,删除最早的 segment。 log.retention.bytes,默认等于-1,表示无穷大。
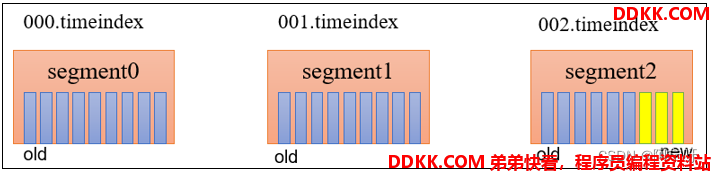
因为以 segment 中所有记录中的最大时间戳作为该文件时间戳。所以对于002.timeindex文件,一个 segment 中有一部分数据过期,一部分没有过期,此时文件的命名为未过期的数据的时间戳,该时间未过期,所以保留该文件。
2、 compact 日志压缩:对于相同key的不同value值,只保留最后一个版本。

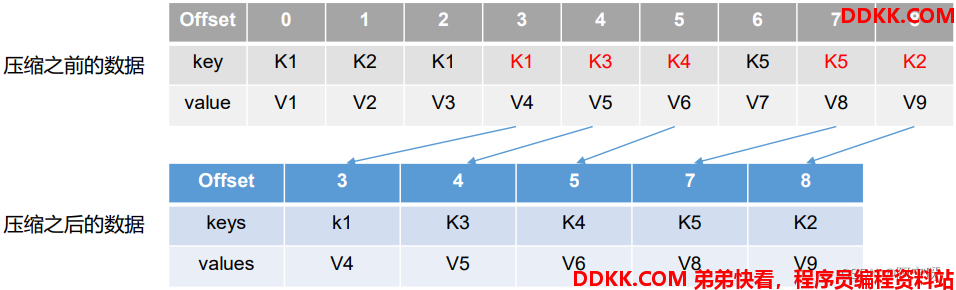
压缩后的offset可能是不连续的,比如上图中没有6,当从这些offset消费消息时,将会拿到比这个offset大的offset对应的消息,实际上会拿到offset为7的消息,并从这个位置开始消费。
这种策略只适合特殊场景,比如消息的key是用户ID,value是用户的资料,通过这种压缩策略,整个消息集里就保存了所有用户最新的资料。例如一个人的19岁数据可以覆盖18岁数据。
2 高效读写数据
1、 Kafka 本身是分布式集群,可以采用分区技术,并行度高.
2、 读数据采用稀疏索引,可以快速定位要消费的数据。
3、顺序写磁盘。
Kafka 的 producer 生产数据,要写入到 log 文件中,写的过程是一直追加到文件末端,为顺序写。
顺序写能够减少大量的磁头寻址时间。
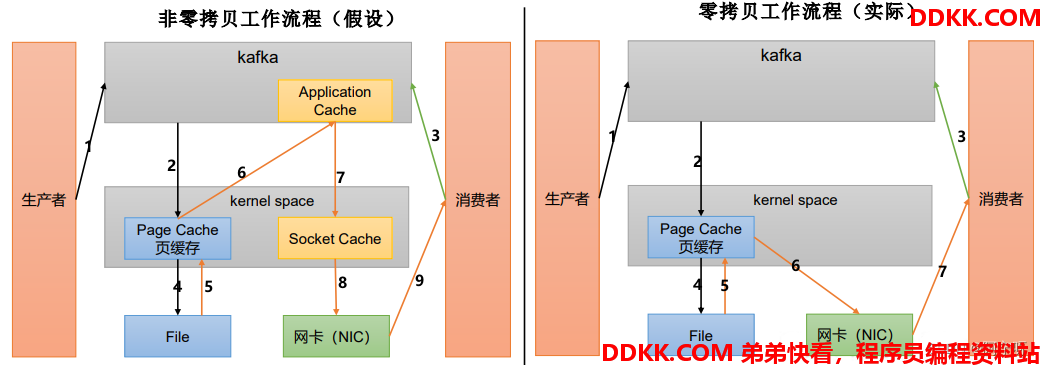
4、页缓存 + 零拷贝技术。
零拷贝:Kafka的数据加工处理操作交由Kafka生产者和Kafka消费者处理。Kafka Broker应用层不关心存储的数据,所以就不用走应用层,传输效率高。
PageCache页缓存: Kafka重度依赖底层操作系统提供的PageCache功能。当上层有写操作时, 操作系统只是将数据写入 PageCache。当读操作发生时,先从PageCache中查找,如果找不到,再去磁盘中读取。实际上PageCache是把尽可能多的空闲内存都当做了磁盘缓存来使用。