parsing 包,从字面上来看就是它的作用就是 解析,在 Mybatis 中需要解析的内容我们第一个能想到的应该就是它的配置文件和映射文件。
XML 文件
可扩展标记语言(Extensible Markup Language,XML) 是一种标记语言。所谓的标记是指计算机所能理解的信息符号,通过标记可以实现软件开发者与计算机之间的信息沟通。常见的 HTML便是一种标记语言,不过 HTML语言中的标签(如“<h1> </h1>”“<img\>”等)都是固定的,是不可扩展的。XML则可以由开发人员自由扩展定义。
XML 文档是由各个节点组成的,主要有:元素节点、属性节点、文本节点、文档节点等。
类 UML 图
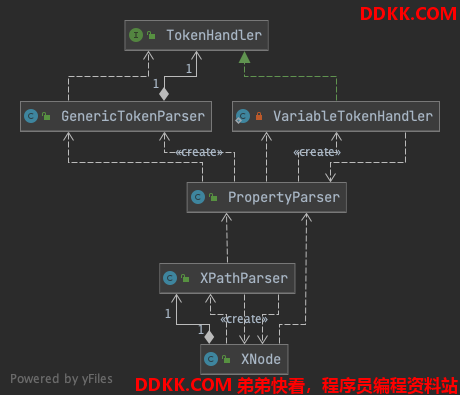
有的读者可能看这个 UML 看的不是很明白,所以在这里简单的讲解一下。XPathParser 是 XPath 工具的一个包装类,负责解析生成 XNode (Node 的包装类)。而解析 Node 节点中的属性时,又因为存在占位符,所以就有了 PropertyParser、GenericTokenParser、TokenHandler 的协作,将属性中的占位符替换为指定的值。XML 实例如下:
<configuration>
<properties>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</properties>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://127.0.0.1:3306/test1"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
</configuration>
将${xxx} 解析为实际的参数就是 PropertyParser 的作用
XNode
我们可以认为 XML 文档就是由各个节点组成的,所以 Mybatis 中的 XML 文档也就是由节点组成了,而这个节点的抽象就是 XNode。
XNode成员变量如下:
public class XNode {
// org.w3c.dom.Node 表示是 XML 中的一个节点
private final Node node;
// 节点名,可以从 org.w3c.dom.Node 中获取
private final String name;
// 节点体,可以从 org.w3c.dom.Node 中获取
private final String body;
// 节点属性,可以从 org.w3c.dom.Node 中获取
private final Properties attributes;
// Mybatis 配置文件中的 properties 节点的信息
private final Properties variables;
// XML 解析器 XPathParser
private final XPathParser xpathParser;
}
我们可以看到在 XNode 的成员变量中居然还有 XPathParser,即解析生成这个节点的解析器。我们可以认为 XNode 拥有自解析能力,举个通俗的例子来说, XPathParser 在解析完成之后会将解析器传递给解析成功的节点,然后这个节点就能继续解析自己的子节点了,而不需要再去创建一个新的解析器了。
为什么XPathParser 在解析的时候不是递归的解析,而是只解析上层的呢?这主要是对性能上的考虑,毕竟使用这个工具类的人不一定真的想要将一个节点的所有子节点的内容都想要搞清楚。
以后在遇到类似的场景时,大家也可以这么去考虑。争取写出高质量的代码,这也就是为什么希望大家要多看源码。
XPathParser
XPathParser 是用来解析 XML 文档,并生成 XNode。
XPathParser成员变量如下:
public class XPathParser {
// 代表要解析的 XML 文档
private final Document document;
// 是否开启验证
private boolean validation;
// 通过 EntityResolver 可以声明寻找 DTD 文件的方法,例如通过本地寻找,而不是只能通过网络下载 DTD 文件
private EntityResolver entityResolver;
// Mybatis 配置文件中的 properties 节点的信息
private Properties variables;
// javax.xml.xpath.XPath 工具
private XPath xpath;
}
evalXXX
在XPathParser 中,有很多 evalXXX 方法,这些方法其实就是 XPath 的路径表达式。
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
| … | … |
详细的表达式就不在这里列出来了,大家可以去 W3C官网 查看。
传入路径表达式到 evalXXX 语句中,就能得到我们想要的结果了。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-th0tFWxk-1621347283820)(media/16149280481108/XPathParser.png)]
所有的evalXXX 实际上调用的都是 evaluate(String, Object, QName) 方法。所以只需要重点关注这个方法就好了。
private Object evaluate(String expression, Object root, QName returnType) {
try {
// 实际上是调用 XPath 解析
return xpath.evaluate(expression, root, returnType);
} catch (Exception e) {
throw new BuilderException("Error evaluating XPath. Cause: " + e, e);
}
}
PropertyParser
在前面已经提到了,这是用来解析属性值中的占位符。在讲解 XPathParser 的时候,其实我故意漏说了一个比较重要的 evalXXX 方法,虽然所有的 evalXXX 在调用 evaluate() 方法后基本上都只是做了类型转换的事情,但是 evalString(...) 方法还做了另一件事情。
即,通过 PropertyParser 解析属性值中的占位符。
public class XPathParser {
public String evalString(Object root, String expression) {
String result = (String) evaluate(expression, root, XPathConstants.STRING);
// 解析属性值中的占位符,将占位符替换为实际的值后并返回
result = PropertyParser.parse(result, variables);
return result;
}
}
public class PropertyParser {
// ...
public static String parse(String string, Properties variables) {
// 通过 VariableTokenHandler 解析占位符中的值,即将 ${username} 中的 username 替换为实际的值
VariableTokenHandler handler = new VariableTokenHandler(variables);
// 通过 GenericTokenParser 定位占位符,在这里将 '${' 开头 '}' 结尾的都认为是占位符,然后传入对应的 handler。
GenericTokenParser parser = new GenericTokenParser("${", "}", handler);
return parser.parse(string);
}
// ...
}
如何定位占位符
解析和占位符替换的过程中,定位占位符是第一件事情,因为必须要找到占位符再说去替换它。在 Mybatis 中定中就定义了一个通用符号解析器 GenericTokenParser。它的作用就是找到定义的占位符,然后将占位符中的内容交给 TokenHandler 去处理。
成员变量
// 起始符号
private final String openToken;
// 结束符号
private final String closeToken;
// 处理器,占位符的内容会交给它进行处理
private final TokenHandler handler;
具体的处理过程如下代码所示,其实就是找到 openToken 然后找到 closeToken,再将它们之间的内容交给 TokeHandler 处理,然后就将下标移动到 closeToken 的下一个位置,继续查找直到没有需要处理的占位符。
public String parse(String text) {
if (text == null || text.isEmpty()) {
return "";
}
// 预先查找起始符号
int start = text.indexOf(openToken);
// 如果没有找到则直接返回原文本
if (start == -1) {
return text;
}
char[] src = text.toCharArray();
int offset = 0;
final StringBuilder builder = new StringBuilder();
StringBuilder expression = null;
do {
if (start > 0 && src[start - 1] == '\\') {
// 起始符号被转义了,删除反斜杠然后然后开始下标向后移动
builder.append(src, offset, start - offset - 1).append(openToken);
offset = start + openToken.length();
} else {
if (expression == null) {
expression = new StringBuilder();
} else {
expression.setLength(0);
}
// 先拼接 "${" 之前内容
builder.append(src, offset, start - offset);
// 将下标偏移到 "${" 紧接的字符的下标
offset = start + openToken.length();
// 找到了起始符号,现在需要从 offset 开始找到结束符号
int end = text.indexOf(closeToken, offset);
// 如果找到了结束符号
while (end > -1) {
// 如果找到的结束符号修饰了转义符号,则找下一个结束符号
if (end > offset && src[end - 1] == '\\') {
expression.append(src, offset, end - offset - 1).append(closeToken);
offset = end + closeToken.length();
end = text.indexOf(closeToken, offset);
} else {
// 找到了正确的结束符号,推出循环
expression.append(src, offset, end - offset);
break;
}
}
if (end == -1) {
// 没有找到结束符号,直接把剩下的内容拷贝到结果中
builder.append(src, start, src.length - start);
offset = src.length;
} else {
// 开始符号有对应的结束符号,则把它们中的内容交给处理器处理
builder.append(handler.handleToken(expression.toString()));
offset = end + closeToken.length();
}
}
start = text.indexOf(openToken, offset);
} while (start > -1);
if (offset < src.length) {
builder.append(src, offset, src.length - offset);
}
return builder.toString();
}
TokenHandler 和 VariableTokenHandler
TokenHandler
TokenHandler 是 Token 处理器接口,它只声明了一个方法。
public interface TokenHandler {
/**
* 处理 Token
* @param content 要处理的内容
* @return 处理结果
*/
String handleToken(String content);
}
VariableTokenHandler
VariableTokenHandler 是 TokenHandler,是用于处理 token 为变量的处理器,将变量替换为实际的值。
/** 是否启用默认值的默认值 */
private static final String ENABLE_DEFAULT_VALUE = "false";
/** 默认值的分隔符 */
private static final String DEFAULT_VALUE_SEPARATOR = ":";
private static class VariableTokenHandler implements TokenHandler {
/** 存储变量名称->实际值的映射集合 */
private final Properties variables;
/** 是否启用默认值 */
private final boolean enableDefaultValue;
/** 默认值的分隔符,如分隔符为 ':',则可以书写为 ${username:root},默认值就是 root */
private final String defaultValueSeparator;
private VariableTokenHandler(Properties variables) {
this.variables = variables;
this.enableDefaultValue = Boolean.parseBoolean(getPropertyValue(
"org.apache.ibatis.parsing.PropertyParser.enable-default-value", ENABLE_DEFAULT_VALUE));
this.defaultValueSeparator = getPropertyValue(
"org.apache.ibatis.parsing.PropertyParser.default-value-separator", DEFAULT_VALUE_SEPARATOR);
}
private String getPropertyValue(String key, String defaultValue) {
return (variables == null) ? defaultValue : variables.getProperty(key, defaultValue);
}
@Override
public String handleToken(String content) {
if (variables != null) {
String key = content;
if (enableDefaultValue) {
final int separatorIndex = content.indexOf(defaultValueSeparator);
String defaultValue = null;
if (separatorIndex >= 0) {
key = content.substring(0, separatorIndex);
defaultValue = content.substring(separatorIndex + defaultValueSeparator.length());
}
if (defaultValue != null) {
return variables.getProperty(key, defaultValue);
}
}
if (variables.containsKey(key)) {
return variables.getProperty(key);
}
}
return "${" + content + "}";
}
}
注:为了方便大家的理解,所以将一些全局变量都直接替换为了实际的值。