executor 包结构
- keygen —— 主键生成,包含三种生成策略 Jdbc3KeyGenerator、NoKeyGenerator、SelectKeyGenerator
- loader —— 实现懒加载,底层是通过代理类实现的懒加载,MyBatis 中生成代理类的框架有两套 cglib 和 javassist。
- parameter —— 参数处理,设置 PreparedStatement 和 CallableStatement 中参数。
- result —— 结果处理,将单个的结果封装到 List、Map、Cursor 中,分别对应 DefaultResultHandler、DefaultMapResultHandler 和 DefaultCursor。
- resultset —— 结果集处理, 处理结果映射中的嵌套映射等逻辑、根据映射关系,生成结果对象、根据数据库查询记录对结果对象的属性进行赋值。
- statement —— 不同语句声明处理
- Executor —— 执行器相关内容
在上篇文章中,我们已经学习了 MyBaits 的主键生成和自动回填、懒加载、预处理语句占位符填充。分别对应了 keygen、loader、parameter 子包。
结果处理
结果处理,即将结果封装为指定类型或者封装到容器中,例如:Map、List、Cursor,不同的类型对应着不同的结果处理器。
Map
将结果封装到 Map 集合中,value 是结果对象,那么 key 是什么呢?实际上 Map 的 key 是由用户来定义的。通过在方法上指定 @MapKey 注解,然后填写想要作为 key 的字段名称,这个字段名称是 value 对象中的。
例如: SQL语句的查询结果如下:
id name age
1 张三 20
2 李四 21
3 王五 22
4 马六 23
方法声明如下:
@MapKey("id")
Map<Long, User> list();
最终得到的结果如下:
users
1 -> {
"id":1,"name":"张三","age":20}
2 -> {
"id":2,"name":"李四","age":21}
3 -> {
"id":3,"name":"王五","age":22}
4 -> {
"id":4,"name":"马六","age":23}
注:由于是 Map ,所以 MapKey 一定要选用唯一的字段,要不然会发生覆盖,导致结果的丢失。
源码解析
public class DefaultMapResultHandler<K, V> implements ResultHandler<V> {
// Map 形式的映射结果
private final Map<K, V> mappedResults;
// Map 的键,由用户指定,是结果对象中的某个属性
private final String mapKey;
// 对象工厂
private final ObjectFactory objectFactory;
// 对象包装工厂
private final ObjectWrapperFactory objectWrapperFactory;
// 反射工厂
private final ReflectorFactory reflectorFactory;
@Override
public void handleResult(ResultContext<? extends V> context) {
// 从上下文中得到一条结果(记录)
final V value = context.getResultObject();
final MetaObject mo = MetaObject.forObject(value, objectFactory, objectWrapperFactory, reflectorFactory);
// 得到 key 的值
final K key = (K) mo.getValue(mapKey);
// 添加到 Map 集合中
mappedResults.put(key, value);
}
public Map<K, V> getMappedResults() {
return mappedResults;
}
}
ResultContext:结果上下文,可以从中获取到一个结果对象,是结果集处理器和结果处理器之间数据传递到桥梁。
List
将对象封装到 List 集合中特别的简单,只需要 add 就好了。
源码解析
public class DefaultResultHandler implements ResultHandler<Object> {
private final List<Object> list;
// constructor
@Override
public void handleResult(ResultContext<?> context) {
list.add(context.getResultObject());
}
public List<Object> getResultList() {
return list;
}
}
Cursor
相较于Map 或 List 集合,Cursor 是特殊,并且它的处理过程也是非常复杂的。在开启了 Cursor 的情况下,查询结果可以一条一条的获取,而不需要一次将所有的结果获取完放在内存中,在数据量特别大的情况下 Cursor 可以防止堆内存溢出。
Cursor 源码分析
成员变量
// 默认的结果集处理器
private final DefaultResultSetHandler resultSetHandler;
// 结果集映射,信息源自 Mapper 映射文件中 <ResultMap> 节点
private final ResultMap resultMap;
// ResultSet 包装类
private final ResultSetWrapper rsw;
// 结果的起止信息
private final RowBounds rowBounds;
// ResultHandler 的子类,起到暂存结果的作用
protected final ObjectWrapperResultHandler<T> objectWrapperResultHandler = new ObjectWrapperResultHandler<>();
// 游标的内部迭代器
private final CursorIterator cursorIterator = new CursorIterator();
// 迭代器获取标志位,限制迭代器只能被获取一次
private boolean iteratorRetrieved;
// 当前游标状态
private CursorStatus status = CursorStatus.CREATED;
// 记录已经映射的行
private int indexWithRowBound = -1;
流程分析
其中主动关键流程的成员变量为 DefaultResultSetHandler、ResultSetWrapper、ObjectWrapperResultHandler、CursorIterator,在协同下实现记录一条一条从数据库中获取。简化后的流程如下:
ActorCursorCursorIteratorDefaultResultSetHandlerResultSetWrapperTypeHandlerObjectWrapperResultHandler.iterator()返回 CursorIterator.hasNext().next().handleRowValuesForSimpleResultMap()从结果集中取出一条记录将其转为目标对象存入到 ObjectWrapperResultHandler 中.getTypeHandler()返回对应的类型处理器.getResult()得到结果对象.handleResult() 将结果对象存储到 ObjectWrapperResultHandler 中一个结果对象ActorCursorCursorIteratorDefaultResultSetHandlerResultSetWrapperTypeHandlerObjectWrapperResultHandler
由于是最简流程,实际上在 DefaultResultSetHandler 中还处理了很多内容。列出来的只是一部分,还有一些没有列出来的并不是特别重要,或者过程比较复杂不建议小伙伴初次看源码的时候学习。
- 多结果集处理: handleResultSets
- 自动映射:applyAutomaticMappings
- discriminator 处理:resolveDiscriminatedResultMap
- 决定是否需要生成懒加载代理类:createResultObject
如何实现一次只取一条记录
要知道Cursor 的优势在于一次只从数据库中获取一条记录的信息,而如果是将所有的记录一次性都取出来并保存在内存中,只是对使用者来说一次只给你一条记录的话,那么 Cursor 便没有任何优势。
将结果封装为 Map 或 List 集合,是将所有的数据都取出来,而封装为 Cursor 的时候每次调用只取一条。在想要复用原有代码的情况下实现这个效果应该是较麻烦的,但是 MyBatis 巧妙的运用了 ResultContext 这一角色。
之前提到过 ResultContext 在 ResultSet 和 ResultHandler 之间传递数据,正常情况下这个上下文可以完成所有的数据的传递,但是在封装为 Cursor 后,从 ResultContext 中获取完数据就会手动的将这个上下文"销毁",当上下文被销毁了就代表这次和数据库的交互就终止了。
当重新调用 next 方法时,就有会重新创建一个新的上下文,当然这个上下文也只会使用一次,然后立马就会被"销毁"掉。
结果上下文
在之前我多次提到了 ResultContext 这一角色,它负责在结果集和结果处理器之间做数据的传递,在框架中这是一个非常常见的传递数据的方法。
有的小伙伴可能会好奇,为什么不直接将结果传过去,非要将结果设置到上下文,然后再将上下文传递过去呢?
最简单的理解就是,可能不只需要结果可能还需要一些额外的信息,然后这些信息可能是不固定的,在不同的情况下额外信息会增加或减少,如果直接传递这些内容的话,可能就需要很多的重载方法,而如果封装到上下文中,那么方法永远只有一个,并且请求参数的数量不会变动。
MyBatis 就巧妙的运用这个上下文实现了 Cursor 一次只会从数据库中取一条记录。
public class DefaultResultContext<T> implements ResultContext<T> {
// 结果对象
private T resultObject;
// 结果计数(表明这是第几个结果对象)
private int resultCount;
// 上下文是否被"销毁"标识
private boolean stopped;
public DefaultResultContext() {
resultObject = null;
resultCount = 0;
stopped = false;
}
// 获取结果对象
@Override
public T getResultObject() {
return resultObject;
}
@Override
public boolean isStopped() {
return stopped;
}
// 填入下一个要传递的结果对象
public void nextResultObject(T resultObject) {
resultCount++;
this.resultObject = resultObject;
}
// 销毁上下文
@Override
public void stop() {
this.stopped = true;
}
}
结果集处理
由于结果集中的判断逻辑和分支很多,并且它要完成的功能同样也很多。所以我只会挑选其中比较关键的几段代码进行分析。
- 多结果集处理: handleResultSets
- 自动映射:applyAutomaticMappings
- discriminator 处理:resolveDiscriminatedResultMap
- 生成懒加载代理类:createResultObject
多结果集处理
由于查询结果可能存在多个结果集,所以 MyBatis 需要处理有多个结果集的情况。
public List<Object> handleResultSets(Statement stmt) throws SQLException {
// 存储结果处理的列表
final List<Object> multipleResults = new ArrayList<>();
// 记录结果集的数量
int resultSetCount = 0;
ResultSetWrapper rsw = getFirstResultSet(stmt);
// 得到所有的结果集映射列表
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) {
// 存在未处理的结果集,也存在未映射的
// 得到待映射待 resultMap
ResultMap resultMap = resultMaps.get(resultSetCount);
// 处理结果集!!!!
handleResultSet(rsw, resultMap, multipleResults, null);
// 将指向下一个 resultSet
rsw = getNextResultSet(stmt);
// 在处理下个结果集之前先清理
cleanUpAfterHandlingResultSet();
// 结果集数量++
resultSetCount++;
}
// 得到多个结果集的名称
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {
// 如果存在多结果集
while (rsw != null && resultSetCount < resultSets.length) {
// 还有未处理的 ResultSet 并且存在未映射的 resultSet
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
// 如果存在 parentMapping
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
// 处理结果集
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);// 指向下一个 ResultSet
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
// 如果只有一个结果集,则需要将这个结果集提取出来
/*
multipleResults 格式
RootList
* List1
* Object
* Object
* List2
* Object
...
如果 RootList 的 size = 1 的话,则需要将那个 List 提取出来,返回
List1
* Object
* Object
如果 RootList 的 size > 1 的话,就直接返回,不做任何操作
总结:如果是单结果集 ? 返回结果列表 : 返回结果集列表;
*/
return collapseSingleResultList(multipleResults);
}
自动映射
在开启了自动映射的情况下,只要属性的命名和列名称完全一致或者符合驼峰式命名的话,就可以自动映射不用显示的声明 <resultMap>,会简单很多。
开启自动映射的条件:
1、 AutoMappingBehavior是PARTIAL或者FULL默认为PARTIAL;
额外配置
1、 启用驼峰式映射:mapUnderscoreToCamelCase=true;
// 应用自动映射
private boolean applyAutomaticMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, String columnPrefix) throws SQLException {
// 由于是自动映射,所以也要构建出对应的映射
List<UnMappedColumnAutoMapping> autoMapping = createAutomaticMappings(rsw, resultMap, metaObject, columnPrefix);
// 只要自动映射了一个不为 null 得知,就为 true
boolean foundValues = false;
if (!autoMapping.isEmpty()) {
// 如果有需要自动映射的列
for (UnMappedColumnAutoMapping mapping : autoMapping) {
final Object value = mapping.typeHandler.getResult(rsw.getResultSet(), mapping.column);
if (value != null) {
foundValues = true;
}
if (value != null || (configuration.isCallSettersOnNulls() && !mapping.primitive)) {
// 在为 null 的情况下是否需要设置值
metaObject.setValue(mapping.property, value);
}
}
}
return foundValues;
}
// 构建映射
private List<UnMappedColumnAutoMapping> createAutomaticMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, String columnPrefix) throws SQLException {
final String mapKey = resultMap.getId() + ":" + columnPrefix;
// 先尝试从缓存取
List<UnMappedColumnAutoMapping> autoMapping = autoMappingsCache.get(mapKey);
if (autoMapping == null) {
// 如果是第一次的话,则要进行解析
autoMapping = new ArrayList<>();
// 得到没有设置映射的列名称
final List<String> unmappedColumnNames = rsw.getUnmappedColumnNames(resultMap, columnPrefix);
for (String columnName : unmappedColumnNames) {
String propertyName = columnName;// 假定列名称和属性名称是相同的
if (columnPrefix != null && !columnPrefix.isEmpty()) {
// 如果指定了前缀
if (columnName.toUpperCase(Locale.ENGLISH).startsWith(columnPrefix)) {
// 如果存在前缀则需要去掉前缀
propertyName = columnName.substring(columnPrefix.length());
} else {
// 忽略没有以前缀开头的列名
continue;
}
}
// 得到列名称对应的属性名称,这里会应用驼峰式命名
// 如果用完整列名找不到,就将完整列名转换为驼峰式的再找列名
final String property = metaObject.findProperty(propertyName, configuration.isMapUnderscoreToCamelCase());
if (property != null && metaObject.hasSetter(property)) {
// 找到了属性名称并且属性有 set 方法
if (resultMap.getMappedProperties().contains(property)) {
// 如果结果集已经为这个属性添加了映射,那么也需要忽略,防止覆盖
continue;
}
// 得到属性类型
final Class<?> propertyType = metaObject.getSetterType(property);
if (typeHandlerRegistry.hasTypeHandler(propertyType, rsw.getJdbcType(columnName))) {
// 如果有对应的类型处理器
final TypeHandler<?> typeHandler = rsw.getTypeHandler(propertyType, columnName);
// 添加到自动映射列表中
autoMapping.add(new UnMappedColumnAutoMapping(columnName, property, typeHandler, propertyType.isPrimitive()));
} else {
// 如果自动映射失败了,需要采取的动作,默认的是无动作
configuration.getAutoMappingUnknownColumnBehavior()
.doAction(mappedStatement, columnName, property, propertyType);
}
} else {
// 如果自动映射失败了,需要采取的动作,默认的是无动作
configuration.getAutoMappingUnknownColumnBehavior()
.doAction(mappedStatement, columnName, (property != null) ? property : propertyName, null);
}
}
// 添加到缓存中
autoMappingsCache.put(mapKey, autoMapping);
}
return autoMapping;
}
鉴别器处理
有时候我们需要根据返回值的不同,选择不同的返回值类型。而鉴别器的作用就是如此,通过鉴别器找到对应的 <resultMap>。本身是一个 <resultMap> 然后根据鉴别器会得到最终对象的 <resultMap>。
public ResultMap resolveDiscriminatedResultMap(ResultSet rs, ResultMap resultMap, String columnPrefix) throws SQLException {
// 已经处理过的鉴别器
Set<String> pastDiscriminators = new HashSet<>();
Discriminator discriminator = resultMap.getDiscriminator();
while (discriminator != null) {
// 如果存在辨别器
// 通过 column 找到 value
final Object value = getDiscriminatorValue(rs, discriminator, columnPrefix);
// 通过 value 找到对应的 resultMapId
final String discriminatedMapId = discriminator.getMapIdFor(String.valueOf(value));
if (configuration.hasResultMap(discriminatedMapId)) {
resultMap = configuration.getResultMap(discriminatedMapId);
// 继续分析下一层,因为当前的 ResultMap 也可能有鉴别器
Discriminator lastDiscriminator = discriminator;
discriminator = resultMap.getDiscriminator();
// 如果辨别器出现了环
if (discriminator == lastDiscriminator || !pastDiscriminators.add(discriminatedMapId)) {
break;
}
} else {
break;
}
}
return resultMap;
}
生成懒加载代理类
懒加载代理类也在这个类中生成,它还决定了是否生成懒加载代理类。
private Object createResultObject(ResultSetWrapper rsw, ResultMap resultMap, ResultLoaderMap lazyLoader, String columnPrefix) throws SQLException {
this.useConstructorMappings = false; final List<Class<?>> constructorArgTypes = new ArrayList<>();
final List<Object> constructorArgs = new ArrayList<>();
Object resultObject = createResultObject(rsw, resultMap, constructorArgTypes, constructorArgs, columnPrefix);
if (resultObject != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
final List<ResultMapping> propertyMappings = resultMap.getPropertyResultMappings();
for (ResultMapping propertyMapping : propertyMappings) {
if (propertyMapping.getNestedQueryId() != null && propertyMapping.isLazy()) {
// 如果存在嵌套查询并且开启了懒加载,则生成代理对象
resultObject = configuration.getProxyFactory().createProxy(resultObject, lazyLoader, configuration, objectFactory, constructorArgTypes, constructorArgs);
break;
}
}
}
this.useConstructorMappings = resultObject != null && !constructorArgTypes.isEmpty(); // set current mapping result
return resultObject;
}
小结:当然在 DefaultResultSetHandler 中完成的工作远不止这些,但是由于很多东西并不常见或者说解析起来难度较大,所以就不在这里讲解了。
结果集包装类
由于在ResultSet 的中还封装了很多其他信息,所以为了方便后面的使用,需要预先从 ResultSet 中将这些信息提取出来,并且以一定的格式存放好。
成员变量
public class ResultSetWrapper {
// 被修饰的 resultSet 对象
private final ResultSet resultSet;
// 类型处理器注册表
private final TypeHandlerRegistry typeHandlerRegistry;
// resultSet 中各个列对应的列名列表
private final List<String> columnNames = new ArrayList<>();
// resultSet 中各个列对应的 Java 类型名称列表
private final List<String> classNames = new ArrayList<>();
// resultSet 中各个列对应的 JDBC 类型列表
private final List<JdbcType> jdbcTypes = new ArrayList<>();
// 类型与类型处理器的映射表。结构为:Map<列名, Map<Java类型, 类型处理器>>
private final Map<String, Map<Class<?>, TypeHandler<?>>> typeHandlerMap = new HashMap<>();
// 记录了所有的有映射关系的列。结构为:Map<resultMap 的 id,List<对象映射的列名>>
private final Map<String, List<String>> mappedColumnNamesMap = new HashMap<>();
// 记录了所有的无映射关系的列。结构为:Map<resultMap 的 id,List<对象映射的列名>>
private final Map<String, List<String>> unMappedColumnNamesMap = new HashMap<>();
public ResultSetWrapper(ResultSet rs, Configuration configuration) throws SQLException {
super();
this.typeHandlerRegistry = configuration.getTypeHandlerRegistry();
this.resultSet = rs;
final ResultSetMetaData metaData = rs.getMetaData();
final int columnCount = metaData.getColumnCount();
for (int i = 1; i <= columnCount; i++) {
// 得到列名称,在这里有用到了 columnLabel 其实就是 AS 后面设置的名称
// 如果没有设置 AS,那么 columnLabel 和 columnName 是一样的
columnNames.add(configuration.isUseColumnLabel() ? metaData.getColumnLabel(i) : metaData.getColumnName(i));
// 得到列名对应的 JDBC 类型
jdbcTypes.add(JdbcType.forCode(metaData.getColumnType(i)));
// 得到对应 class 类的完全限定名称
classNames.add(metaData.getColumnClassName(i));
}
}
}
语句处理器
在JDBC 定义了三种不同的语句 STATEMENT、PREPARED、CALLABLE。在 MyBatis 则对应这三种不同的语句有不同的创建、初始化和操作方式。
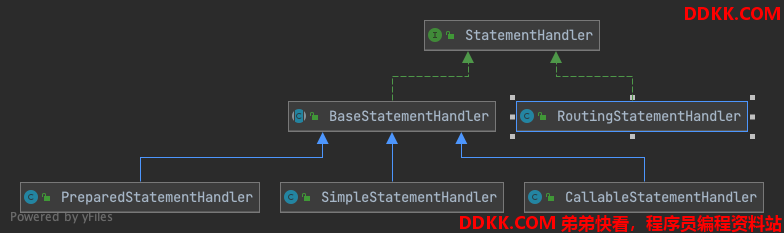
StatementHandler
它是所有语句处理器需要实现的接口,其中语句的创建、SQL 语句的执行、SQL 语句中占位符的填充等。
public interface StatementHandler {
/**
* 做准备工作
* 1. 生成对应的 Statement
* 2. 初始化相关参数
*/
Statement prepare(Connection connection, Integer transactionTimeout)
throws SQLException;
// 参数化处理,例如占位符的填充
void parameterize(Statement statement)
throws SQLException;
// 将 sql 语句添加到表达式中
void batch(Statement statement)
throws SQLException;
// 执行更新方法
int update(Statement statement)
throws SQLException;
// 执行查询方法,返回一个列表
<E> List<E> query(Statement statement, ResultHandler resultHandler)
throws SQLException;
// 执行查询方法,返回一个 Cursor
<E> Cursor<E> queryCursor(Statement statement)
throws SQLException;
// 得到 boundSql
BoundSql getBoundSql();
// 得到参数处理器
ParameterHandler getParameterHandler();
}
BaseStatementHandler
这个类是所有语句处理器的基类,它实现了 StatementHandler 接口,实现其中的部分公共方法。
public abstract class BaseStatementHandler implements StatementHandler {
// MyBatis 全局配置信息
protected final Configuration configuration;
// 对象工厂
protected final ObjectFactory objectFactory;
// 类型处理器注册表
protected final TypeHandlerRegistry typeHandlerRegistry;
// 结果集处理器
protected final ResultSetHandler resultSetHandler;
// 参数处理器
protected final ParameterHandler parameterHandler;
// 执行器
protected final Executor executor;
// 表达式映射
protected final MappedStatement mappedStatement;
// 行绑定
protected final RowBounds rowBounds;
protected BoundSql boundSql;
// 预处理方法
@Override
public Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException {
Statement statement = null;
try {
// 实例化语句
statement = instantiateStatement(connection);
// 设置语句的超时时间
setStatementTimeout(statement, transactionTimeout);
// 设置批量返回结果行数的建议值
setFetchSize(statement);
return statement;
} catch (SQLException e) {
closeStatement(statement);
throw e;
} catch (Exception e) {
closeStatement(statement);
throw new ExecutorException("");
}
// 实例化语句(定义的抽象方法,由子类来实现)
protected abstract Statement instantiateStatement(Connection connection) throws SQLException;
}
RoutingStatementHandler
语言处理器路由,由于有多个语句处理器,要实现根据不同的语句类型选择不同的语句处理器进行处理。最简单的方式就是在业务代码里面判断,然而 MyBatis 采用了一种更为优雅的方式,即通过路由来选择具体的语句处理器。
而且RoutingStatementHandler 也是一个语句处理器,所以对外部来说是一个通用的语句处理器,具体选择哪个就由内部来决定,使代码看上去更加优美。
外部调用的所有方法都是交由它内部生成的代理类来处理的,它只是做了一个转发。这算是一种委派者模式的应用。
public class RoutingStatementHandler implements StatementHandler {
// 根据语句类型选取的代理对象
private final StatementHandler delegate;
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// 根据语句类型选择代理对象
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
@Override
public Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException {
return delegate.prepare(connection, transactionTimeout);
}
@Override
public void parameterize(Statement statement) throws SQLException {
delegate.parameterize(statement);
}
// ...
}
SimpleStatementHandler
简单语句处理器对应的就是 Statement 类型,所以处理流程相对来说是非常简单的。
public class SimpleStatementHandler extends BaseStatementHandler {
@Override
public int update(Statement statement) throws SQLException {
String sql = boundSql.getSql();
Object parameterObject = boundSql.getParameterObject();
KeyGenerator keyGenerator = mappedStatement.getKeyGenerator();
int rows;
// 根据 keyGenerator 的类型指定特定的 execute 方法
if (keyGenerator instanceof Jdbc3KeyGenerator) {
statement.execute(sql, Statement.RETURN_GENERATED_KEYS);
rows = statement.getUpdateCount();
keyGenerator.processAfter(executor, mappedStatement, statement, parameterObject);
} else if (keyGenerator instanceof SelectKeyGenerator) {
statement.execute(sql);
rows = statement.getUpdateCount();
keyGenerator.processAfter(executor, mappedStatement, statement, parameterObject);
} else {
statement.execute(sql);
rows = statement.getUpdateCount();
}
return rows;
}
@Override
public void batch(Statement statement) throws SQLException {
String sql = boundSql.getSql();
statement.addBatch(sql);
}
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
String sql = boundSql.getSql();
// 执行语句
statement.execute(sql);
// 处理结果集
return resultSetHandler.handleResultSets(statement);
}
@Override
public <E> Cursor<E> queryCursor(Statement statement) throws SQLException {
String sql = boundSql.getSql();
// 执行语句
statement.execute(sql);
// 处理结果集
return resultSetHandler.handleCursorResultSets(statement);
}
@Override
protected Statement instantiateStatement(Connection connection) throws SQLException {
if (mappedStatement.getResultSetType() == ResultSetType.DEFAULT) {
// 结果集类型为默认的情况下,直接通过连接创建表达式
return connection.createStatement();
} else {
// 非默认情况下,传递想要得到的结果集类型,并设置并发级别为只读
return connection.createStatement(mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);
}
}
@Override
public void parameterize(Statement statement) {
// 由于是 Statement 类型,所以没有占位符或输入参数需要处理
}
}
PreparedStatementHandler
预处理语句处理器,预处理语句相较于普通语句有一个占位符填充,将最开始由我们自己拼接 SQL 的方式,改为预处理语句来处理。占位符填充在 parameterize 方法中实现,而 ParameterHandler 在上面已经提到了,所以这里不做过多的描述了。
public class PreparedStatementHandler extends BaseStatementHandler {
public PreparedStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
super(executor, mappedStatement, parameter, rowBounds, resultHandler, boundSql);
}
@Override
public int update(Statement statement) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
int rows = ps.getUpdateCount();
Object parameterObject = boundSql.getParameterObject();
KeyGenerator keyGenerator = mappedStatement.getKeyGenerator();
keyGenerator.processAfter(executor, mappedStatement, ps, parameterObject);
return rows;
}
@Override
public void batch(Statement statement) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.addBatch();
}
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
return resultSetHandler.handleResultSets(ps);
}
@Override
public <E> Cursor<E> queryCursor(Statement statement) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
return resultSetHandler.handleCursorResultSets(ps);
}
@Override
protected Statement instantiateStatement(Connection connection) throws SQLException {
String sql = boundSql.getSql();
// 根据 keyGenerator 或 ResultSetType 构建 Statement
if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {
String[] keyColumnNames = mappedStatement.getKeyColumns();
if (keyColumnNames == null) {
return connection.prepareStatement(sql, PreparedStatement.RETURN_GENERATED_KEYS);
} else {
return connection.prepareStatement(sql, keyColumnNames);
}
} else if (mappedStatement.getResultSetType() == ResultSetType.DEFAULT) {
return connection.prepareStatement(sql);
} else {
return connection.prepareStatement(sql, mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);
}
}
@Override
public void parameterize(Statement statement) throws SQLException {
// 为表达式中的 '?' 占位符赋值
parameterHandler.setParameters((PreparedStatement) statement);
}
}
CallableStatementHandler
CallableStatement 是用来调用存储过程的。而存储过程的调用存在三种形式。
1、 有入参:{call过程名[(?,?,…)]};
2、 有出参:{?call过程名[(?,?,…)]};
3、 不带参数:{call过程名};
由于CallableStatement 继承了 PrepareStatement 所以在占位符填充的基础上还多了一步 OUT 参数的注册(占位符填充其实就是 IN 参数的处理)
public class CallableStatementHandler extends BaseStatementHandler {
@Override
public int update(Statement statement) throws SQLException {
CallableStatement cs = (CallableStatement) statement;
cs.execute();
int rows = cs.getUpdateCount();
Object parameterObject = boundSql.getParameterObject();
KeyGenerator keyGenerator = mappedStatement.getKeyGenerator();
keyGenerator.processAfter(executor, mappedStatement, cs, parameterObject);
resultSetHandler.handleOutputParameters(cs);
return rows;
}
@Override
public void batch(Statement statement) throws SQLException {
CallableStatement cs = (CallableStatement) statement;
cs.addBatch();
}
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
CallableStatement cs = (CallableStatement) statement;
cs.execute();
List<E> resultList = resultSetHandler.handleResultSets(cs);
resultSetHandler.handleOutputParameters(cs);
return resultList;
}
@Override
public <E> Cursor<E> queryCursor(Statement statement) throws SQLException {
CallableStatement cs = (CallableStatement) statement;
cs.execute();
Cursor<E> resultList = resultSetHandler.handleCursorResultSets(cs);
resultSetHandler.handleOutputParameters(cs);
return resultList;
}
@Override
protected Statement instantiateStatement(Connection connection) throws SQLException {
String sql = boundSql.getSql();
if (mappedStatement.getResultSetType() == ResultSetType.DEFAULT) {
return connection.prepareCall(sql);
} else {
return connection.prepareCall(sql, mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);
}
}
@Override
public void parameterize(Statement statement) throws SQLException {
// OUT 参数的注册
registerOutputParameters((CallableStatement) statement);
// IN 参数的处理
parameterHandler.setParameters((CallableStatement) statement);
}
// 输出参数的注册
private void registerOutputParameters(CallableStatement cs) throws SQLException {
// 从 BoundSql 中得到请求参数映射列表
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
for (int i = 0, n = parameterMappings.size(); i < n; i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
// 只处理 ParameterMode.OUT 和 ParameterMode.INOUT 类型的参数
if (parameterMapping.getMode() == ParameterMode.OUT || parameterMapping.getMode() == ParameterMode.INOUT) {
if (null == parameterMapping.getJdbcType()) {
// 如果没有 jdbcType 抛出异常
throw new ExecutorException("");
} else {
// 如果是 jdbcType 是数值类型并且也设置了小数点的位数,则使用特定的方法注册 OutputParameter
if (parameterMapping.getNumericScale() != null && (parameterMapping.getJdbcType() == JdbcType.NUMERIC || parameterMapping.getJdbcType() == JdbcType.DECIMAL)) {
cs.registerOutParameter(i + 1, parameterMapping.getJdbcType().TYPE_CODE, parameterMapping.getNumericScale());
} else {
if (parameterMapping.getJdbcTypeName() == null) {
cs.registerOutParameter(i + 1, parameterMapping.getJdbcType().TYPE_CODE);
} else {
cs.registerOutParameter(i + 1, parameterMapping.getJdbcType().TYPE_CODE, parameterMapping.getJdbcTypeName());
}
}
}
}
}
}
}
参考文献
1、 《通用源码阅读指导书:Mybatis源码阅读详解》——易哥;