一、必要的前言
在上一篇中,我们主要讲了一下JpaRepository的继承关系与JpaSpecificationExecutor接口并行使用的原因,接下来,我们还是按照之前的节奏,学习一下查询中最复杂的按条件分页排序查询
本片教程继续使用03-查询——自定义简单SQL中写好的小Dome
二、修改数据库
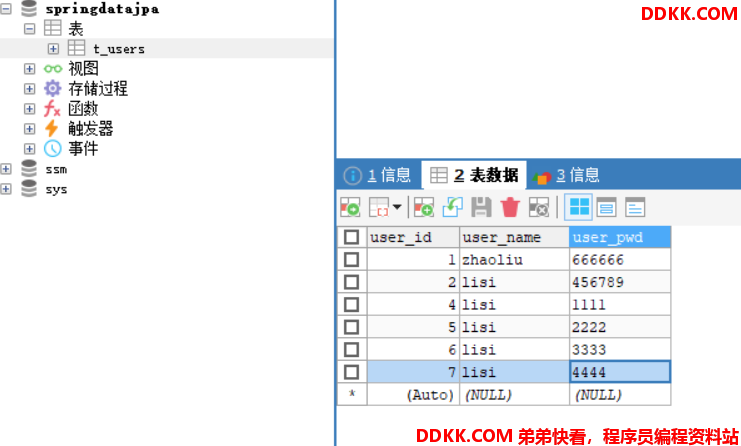
这里我们把数据库中多加几个用户名为lisi的数据,我们就用这个作为条件了。
这里我说一下咱们这个dome的基本需求吧:倒叙查询出用户名为lisi的数据且分页。 不说怕大家不好理解
三、修改SelectController
import cn.ddkk.springdatajpa.dao.UsersJpaDao;
import cn.ddkk.springdatajpa.pojo.Users;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
import org.springframework.data.jpa.domain.Specification;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import javax.persistence.criteria.CriteriaBuilder;
import javax.persistence.criteria.CriteriaQuery;
import javax.persistence.criteria.Predicate;
import javax.persistence.criteria.Root;
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
/**
* 各种查询
* @author DDKK.COM 弟弟快看,程序员编程资料站
* @Date:2022/1/30
* @Description:cn.ddkk.springdatajpa.controller
* @Version:1.0
*/
@RestController
@RequestMapping("/select")
public class SelectController {
@Autowired
private UsersJpaDao usersJpaDao;
/**
* 主键查询
* @return
*/
@GetMapping("/selectUserId")
public Users selectUserId(@RequestParam("userId")Integer userId){
Optional<Users> users=this.usersJpaDao.findById(userId);
return users.get();
}
/**
* 自定义sql查询
* 通过账号密码查询
* @return
*/
@GetMapping("/selectUserNameAndUserPwd")
public Users selectUserNameAndUserPwd(@RequestParam("userName")String userName,@RequestParam("userPwd")String userPwd){
Users users=this.usersJpaDao.findByUserNameAndUserPwd(userName,userPwd);
return users;
}
/**
* 自定义sql查询
* 通过账号模糊查询
* @return
*/
@GetMapping("/selectUserNameLike")
public List<Users> selectUserNameLike(@RequestParam("userName")String userName){
List<Users> list=this.usersJpaDao.findByUserNameLike("%"+userName+"%");
return list;
}
/**
* 按条件分页排序查询
* @param userName 条件 用户名
* @param pageNum 页码
* @param pageSize 一页展示的条数
* @return
*/
@GetMapping("/selectUserList")
public Page selectUserList(@RequestParam("userName")String userName,@RequestParam("pageNum")Integer pageNum,@RequestParam("pageSize")Integer pageSize){
Specification<Users> spec=new Specification<Users>() {
/**
* 匿名内部类
* Predicate:封装了单个的查询条件
* Root<Users> root:查询对象的属性的封装
* CriteriaQuery<?> query:封装了我们要执行的查询中的各个部分的信息
* CriteriaBuilder cb:查询条件的构造器。定义不同的查询条件
*/
public Predicate toPredicate(Root<Users> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
//这里用一个list,主要是为了将不同的条件分别封装起来,最后在组合成一个,有利于管理,如果只有一个条件,不用这个也可以
List<Predicate> predicates = new ArrayList<>();
if (userName!=null) {
//这里使用CD更像是拼接的意思,and就是在SQL后面增加一个and ,其他的雷同
//查询条件例子:where name ='李健'
//参数一:查询条件的属性 参数二:条件值
predicates.add(cb.and(cb.equal(root.get("userName"),userName )));
}
return cb.and(predicates.toArray(new Predicate[predicates.size()]));
}
};
//Order 定义排序规则
//Sort对象封装了排序规则
Sort sort=new Sort(new Sort.Order(Sort.Direction.DESC,"userId"));
//Pageable 封装了分页的参数,当前页,每页显示的条数,注意:它的当前页是从0开始的。
//PageRequest(0, 2) Page:当前页 。 size:每页显示的条数
Pageable pageable=new PageRequest(pageNum-1, pageSize, sort);
//封装分页信息的返回值,看不懂可以输出一下看看或者看看源码很简单
Page<Users> page=this.usersJpaDao.findAll(spec,pageable);
return page;
}
}
这个方法看上去是不是很复杂,不用担心我每一行代码,每一条语句,每一个参数都为大家说明了,大家看注释定能理解,注意包不要导入错了哈!
关于使用List容器添加查询条件Predicate这里我多说两句,这是我自己的一种设计,并不是官方用的,这里的意义在于当你需要判断的条件过多时,又不确定这些条件到底有没有真的传入值,就用这个容器装一下在拼起来,这样会让系统更有灵活性。
大家可能会觉得,比起之前的增删改查,这个查询连内部类都用上了,有点过于复杂了,其实不然。首先这个查询本身就有很多的逻辑,其次这些代码完全可以做一个封装,复用性很高,而且这里的写法就好比mybatis的动态SQL,在xml上写总不如直接写java方便吧,例如控制排序所需要的字段,完全可以做成参数,这样你前端的表格就可以实现按照任意表头进行排序的功能了。
四、测试
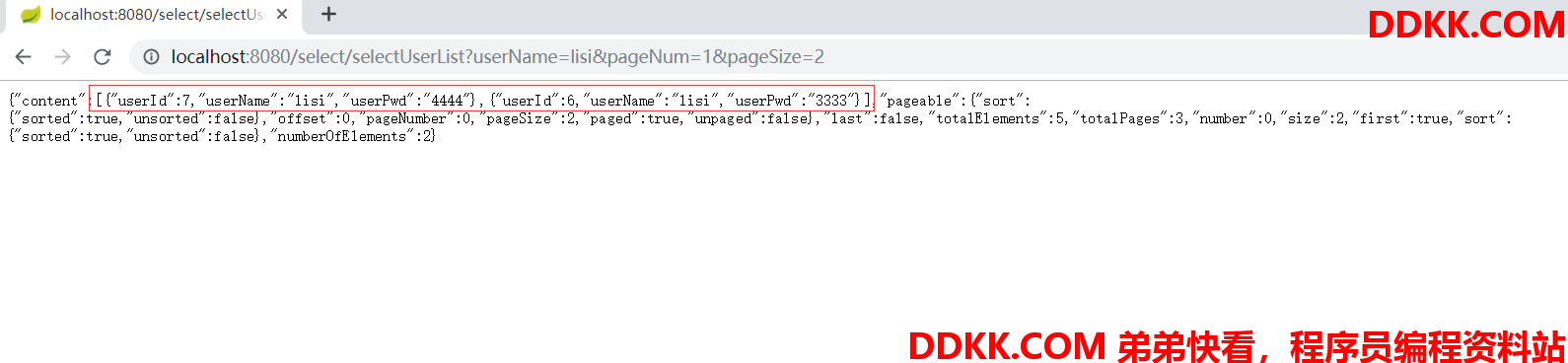
启动项目。浏览器输入:
http://localhost:8080/select/selectUserList?userName=lisi&pageNum=1&pageSize=2
我们把pageSize给个3试试
http://localhost:8080/select/selectUserList?userName=lisi&pageNum=1&pageSize=3
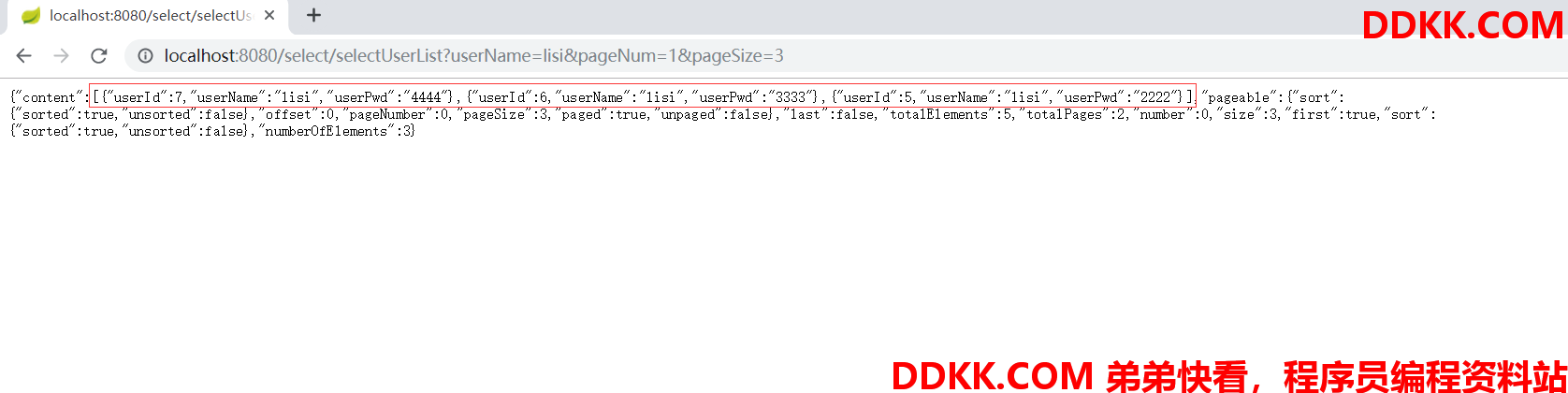
怎么样,是不是很好用。
五、小结
这里我直接给的是最全面的查询,如果你只需要其中一两张功能,比如排序和分页不需要按条件查询,那就可以把上面的内部类删了即可,全在于你个人的理解了。这里的实现方法还是蛮多的,建议大家也可以看看其他博主的博客,相信也会受益匪浅,我展示的是我平常觉得比较好用的。
到这来,基本的CURD便结束了,后面会讲到经典的一对多,多对多模型,大家提前把这块弄热乎了,免得后面跟不上。