一、必要的前言
这一篇我们讲述一下查询中的多对一与一对多查询,SpringDataJpa中的使用方法非常简单,只需要一个注解即可使用,相信大家很轻易的就能理解。
本片教程继续使用上一篇中写好的小Dome
二、创建一个角色类
import java.io.Serializable;
import java.util.HashSet;
import java.util.Set;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.OneToMany;
import javax.persistence.Table;
import com.fasterxml.jackson.annotation.JsonIgnore;
import javax.persistence.JoinColumn;
/**
* @author DDKK.COM 弟弟快看,程序员编程资料站
* @Date:2022/2/1
* @Description:cn.ddkk.springdatajpa.pojo
* @Version:1.0
*/
/**
* 角色类
*
* @author a2417
*
*/
@Entity
@Table(name="t_role")
public class Role implements Serializable {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
@Column(name="roleId")
private Integer roleId;
@Column(name="roleName")
private String roleName;
public Integer getRoleId() {
return roleId;
}
public void setRoleId(Integer roleId) {
this.roleId = roleId;
}
public String getRoleName() {
return roleName;
}
public void setRoleName(String roleName) {
this.roleName = roleName;
}
}
这跟我们创建Users(用户)类时没有什么区别,为了方便演示我们只写两个字段即可,一个是主键,一个是角色名称。
用户与角色是权限模型中最重要的三环之二。这两个恰好处于多对一与一对多。我们假设一个用户只能对应一个角色,一个角色可以被很多个对象所使用。
三、多对一
1.修改Users类
import javax.persistence.*;
/**
* 用户类。用于与数据users表映射
* @Date:2022/1/28
* @Description:cn.ddkk.springdatajpa.pojo
* @Version:1.0
*/
@Entity
@Table(name="t_users")
public class Users {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
@Column(name="userId")
private int userId;
@Column(name="userName")
private String userName;
@Column(name="userPwd")
private String userPwd;
@ManyToOne(cascade=CascadeType.PERSIST)
private Role role;
public Role getRole() {
return role;
}
public void setRole(Role role) {
this.role = role;
}
public int getUserId() {
return userId;
}
public void setUserId(int userId) {
this.userId = userId;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getUserPwd() {
return userPwd;
}
public void setUserPwd(String userPwd) {
this.userPwd = userPwd;
}
@Override
public String toString() {
return "Users{" +
"userId=" + userId +
", userName='" + userName + '\'' +
", userPwd='" + userPwd + '\'' +
'}';
}
}
1、 新增一个Role对象属性用于存放对应的唯一一个角色,该变量无需使用@Column(name="")注解声明;;
2、@ManyToOne(cascade=CascadeType.PERSIST)顾名思义用于多对一关系模型时的注解,该注解只需要加在对应属性上即可;
3、@ManyToOne注解中cascade参数是给予他各种联级操作的权限,像这里我们需要查询时将Role对象直接查出并注入尽量,便需要保存操作,以下是我给大家从网络上找到的一些参数的解释:;
- CascadeType.PERSIST:级联持久化(保存)操作(持久保存拥有方实体时,也会持久保存该实体的所有相关数据。)
- CascadeType.REMOVE :级联删除操作。删除当前实体时,与它有映射关系的实体也会跟着被删除。
- CascadeType.MERGE:级联更新(合并)操作。当Student中的数据改变,会相应地更新Course中的数据。
- CascadeType.DETACH:级联脱管/游离操作。如果你要删除一个实体,但是它有外键无法删除,你就需要这个级联权限了。它会撤销所有相关的外键关联。
- CascadeType.REFRESH:级联刷新操作
- CascadeType.ALL:拥有以上所有级联操作权限。
说了这么多,大家应该能明白了吧,如果不明白,就接着往下看看效果在回顾这里,或许你就会明白过来了。
2.启动项目,修改数据库
启动项目,项目启动完成后查看一下数据库。
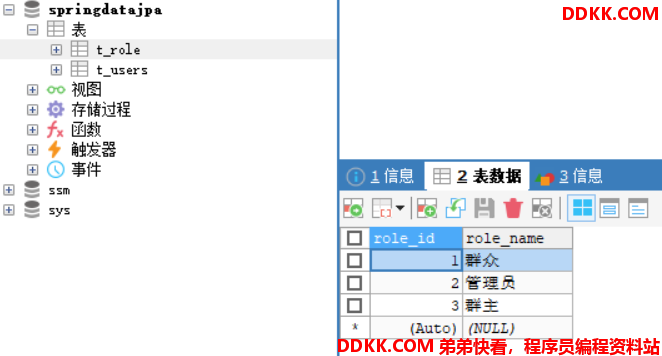
这时数据中应该有两个表,一个是之前的表t_users,另一个是JPA为我们刚刚生成的t_role。
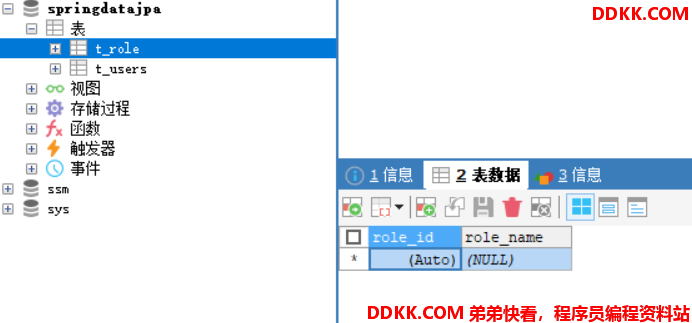
这里可以看到,JPA为我们自动生成了一个role_role_id
的列,这里就是存放角色表中的主键的,即roleId。
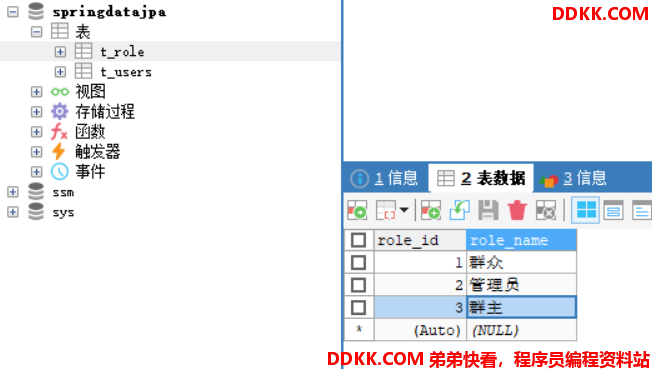
这里我们需要先准备一些数据,好给大家演示。
3.向t_role表中加入三个角色:群众,管理员,群主
4.修改启动类中我们之前创建的修改,加入一个Role对象,Role对象数据需要与数据库中的数据保持一致。
@SpringBootApplication
@RestController
public class SpringdatajpaApplication {
@Autowired
private UsersJpaDao usersJpaDao;
public static void main(String[] args) {
SpringApplication.run(SpringdatajpaApplication.class, args);
}
/**
* 新增
* @param userName
* @param userPwd
* @return
*/
@GetMapping("/insertUser")
public Users insertUser(@RequestParam("userName")String userName,@RequestParam("userPwd")String userPwd){
Users users=new Users();
users.setUserName(userName);
users.setUserPwd(userPwd);
return this.usersJpaDao.save(users);
}
/**
* 修改
* @param userId
* @param userName
* @param userPwd
* @return
*/
@GetMapping("/updateUser")
public Users updateUser(@RequestParam("userId")Integer userId,@RequestParam("userName")String userName,@RequestParam("userPwd")String userPwd){
Users users=new Users();
users.setUserName(userName);
users.setUserPwd(userPwd);
users.setUserId(userId);
Role role=new Role();
role.setRoleId(1);
role.setRoleName("群众");
users.setRole(role);
return this.usersJpaDao.save(users);
}
/**
* 删除
* @param userId
* @return
*/
@GetMapping("/deleteUser")
public String deleteUser(@RequestParam("userId")Integer userId){
this.usersJpaDao.deleteById(userId);
return "删除成功";
}
}
5.启动项目并修改zhaoliu用户
启动项目后浏览器输入:
http://localhost:8080/updateUser?userName=zhaoliu&userPwd=666666&userId=1
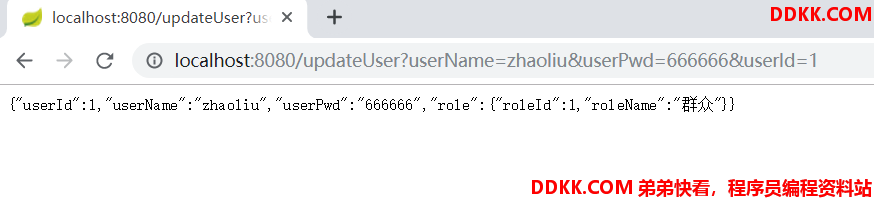
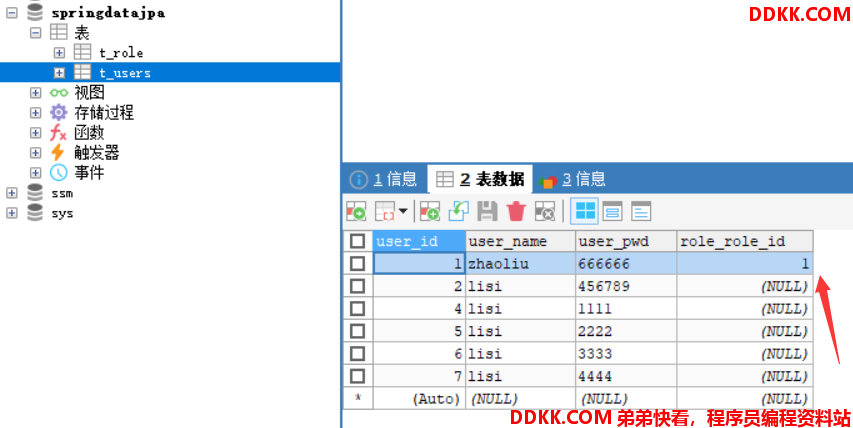
可以看到,save()方法本身具有的查询能力就已经触发了关联查询,role对象中的所有数据都已经出现,我们还可以自己查询一下试试,这里外面先简单的介绍一下数据库中发生了什么?
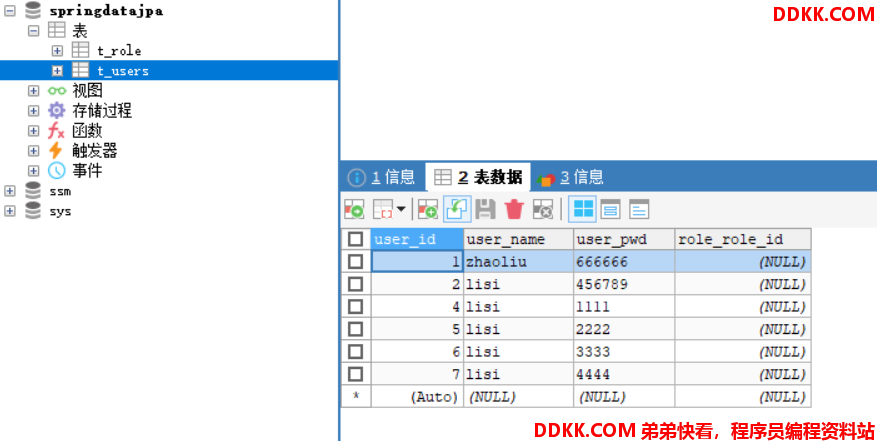
t_role表并不会有什么变化
t_users表中修改的第一条数据增加了对应t_role表中群众的主键
细心的同学可以发现,我们在代码中添加的Role对象是在t_role表中存在的数据,如果不存在呢?
这里我可以告诉你会报错,这是我自己试的,大家如果想试试就自己动手吧,把Role对象中的数据随便改改即可,我就不带着大家走弯路了。
6.我们自己查询一下试试,看看多对一关系会不会出现
浏览器输入:
http://localhost:8080/select/selectUserNameLike?userName=i

三、一对多
1.修改Role.java文件
package cn.ddkk.springdatajpa.pojo;
import java.io.Serializable;
import java.util.HashSet;
import java.util.Set;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.OneToMany;
import javax.persistence.Table;
import com.fasterxml.jackson.annotation.JsonIgnore;
import javax.persistence.JoinColumn;
/**
* @author DDKK.COM 弟弟快看,程序员编程资料站
* @Date:2022/2/1
* @Description:cn.ddkk.springdatajpa.pojo
* @Version:1.0
*/
/**
* 角色类
*
* @author a2417
*
*/
@Entity
@Table(name="t_role")
public class Role implements Serializable {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
@Column(name="roleId")
private Integer roleId;
@Column(name="roleName")
private String roleName;
@OneToMany(mappedBy="role")
private Set<Users> usersList=new HashSet<>();
public Set<Users> getUsersList() {
return usersList;
}
public void setUsersList(Set<Users> usersList) {
this.usersList = usersList;
}
public Integer getRoleId() {
return roleId;
}
public void setRoleId(Integer roleId) {
this.roleId = roleId;
}
public String getRoleName() {
return roleName;
}
public void setRoleName(String roleName) {
this.roleName = roleName;
}
}
1、 储存Users的容器应该使用Set,它具有去重的能力,也是JPA官方规定的;
2、@OneToMany(mappedBy="role")顾名思义一对多;
3、@OneToMany注解中mappedBy参数是指应该指向从表中维护与主表关系的字段定义类之间的双向关系如果类之间是单向关系,不需要提供定义对于Role类来说,mappedBy就应该指向User类中的role属性;
4、 双向关系是指两个类互为一对多多对一或者多对多关系,咱们的Users类与Role类就是这样;
5、 补充一个知识:这里有一个注解@mappedBy也是同这个属性一样的功能,但是这个注解却会多创造一张表用于维持连接,而@OneToMany注解中使用mappedBy参数却不会,所以我们用后者;
2.在dao层中添加RoleDao用于操作t_role表
package cn.ddkk.springdatajpa.dao;
import cn.ddkk.springdatajpa.pojo.Role;
import cn.ddkk.springdatajpa.pojo.Users;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
/**
* @author DDKK.COM 弟弟快看,程序员编程资料站
* @Description:cn.ddkk.springdatajpa.dao
* @Version:1.0
*/
public interface RoleJpaDao extends JpaSpecificationExecutor<Role>, JpaRepository<Role, Integer> {
}
3.在SelectController中添加按主键查询表t_role的接口
/**
* 各种查询
* @author DDKK.COM 弟弟快看,程序员编程资料站
* @Date:2022/1/30
* @Description:cn.ddkk.springdatajpa.controller
* @Version:1.0
*/
@RestController
@RequestMapping("/select")
public class SelectController {
@Autowired
private UsersJpaDao usersJpaDao;
@Autowired
private RoleJpaDao roleJpaDao;
/**
* 主键查询
* @return
*/
@GetMapping("/selectUserId")
public Users selectUserId(@RequestParam("userId")Integer userId){
Optional<Users> users=this.usersJpaDao.findById(userId);
return users.get();
}
/**
* 自定义sql查询
* 通过账号密码查询
* @return
*/
@GetMapping("/selectUserNameAndUserPwd")
public Users selectUserNameAndUserPwd(@RequestParam("userName")String userName,@RequestParam("userPwd")String userPwd){
Users users=this.usersJpaDao.findByUserNameAndUserPwd(userName,userPwd);
return users;
}
/**
* 自定义sql查询
* 通过账号模糊查询
* @return
*/
@GetMapping("/selectUserNameLike")
public List<Users> selectUserNameLike(@RequestParam("userName")String userName){
List<Users> list=this.usersJpaDao.findByUserNameLike("%"+userName+"%");
return list;
}
/**
* 按条件分页排序查询
* @param userName 条件 用户名
* @param pageNum 页码
* @param pageSize 一页展示的条数
* @return
*/
@GetMapping("/selectUserList")
public Page selectUserList(@RequestParam("userName")String userName,@RequestParam("pageNum")Integer pageNum,@RequestParam("pageSize")Integer pageSize){
Specification<Users> spec=new Specification<Users>() {
/**
* 匿名内部类
* Predicate:封装了单个的查询条件
* Root<Users> root:查询对象的属性的封装
* CriteriaQuery<?> query:封装了我们要执行的查询中的各个部分的信息
* CriteriaBuilder cb:查询条件的构造器。定义不同的查询条件
*/
public Predicate toPredicate(Root<Users> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
//这里用一个list,主要是为了将不同的条件分别封装起来,最后在组合成一个,有利于管理,如果只有一个条件,不用这个也可以
List<Predicate> predicates = new ArrayList<>();
if (userName!=null) {
//这里使用CD更像是拼接的意思,and就是在SQL后面增加一个and ,其他的雷同
//查询条件例子:where name ='李健'
//参数一:查询条件的属性 参数二:条件值
predicates.add(cb.and(cb.equal(root.get("userName"),userName )));
}
return cb.and(predicates.toArray(new Predicate[predicates.size()]));
}
};
//Order 定义排序规则
//Sort对象封装了排序规则
Sort sort=new Sort(new Sort.Order(Sort.Direction.DESC,"userId"));
//Pageable 封装了分页的参数,当前页,每页显示的条数,注意:它的当前页是从0开始的。
//PageRequest(0, 2) Page:当前页 。 size:每页显示的条数
Pageable pageable=new PageRequest(pageNum-1, pageSize, sort);
Page<Users> page=this.usersJpaDao.findAll(spec,pageable);
return page;
}
/**
* 主键查询Role
* @return
*/
@GetMapping("/selectRoleId")
public Role selectRoleId(@RequestParam("roleId")Integer roleId){
Optional<Role> role=this.roleJpaDao.findById(roleId);
return role.get();
}
}
4.测试
启动项目,测试
注意问题就要来了
浏览器输入:
http://localhost:8080/select/selectRoleId?roleId=1
浏览器打印
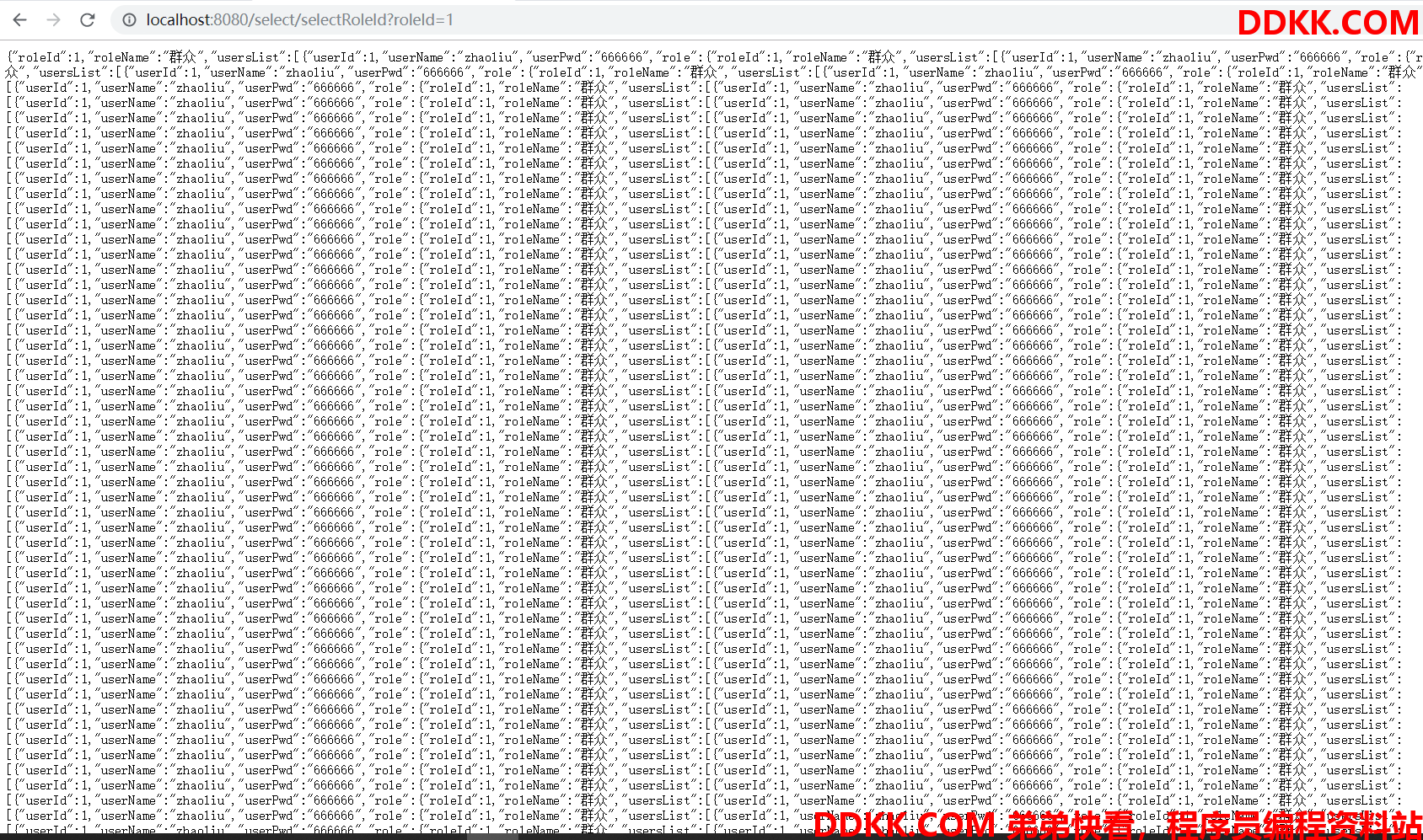
控制台中也有个报错提醒。
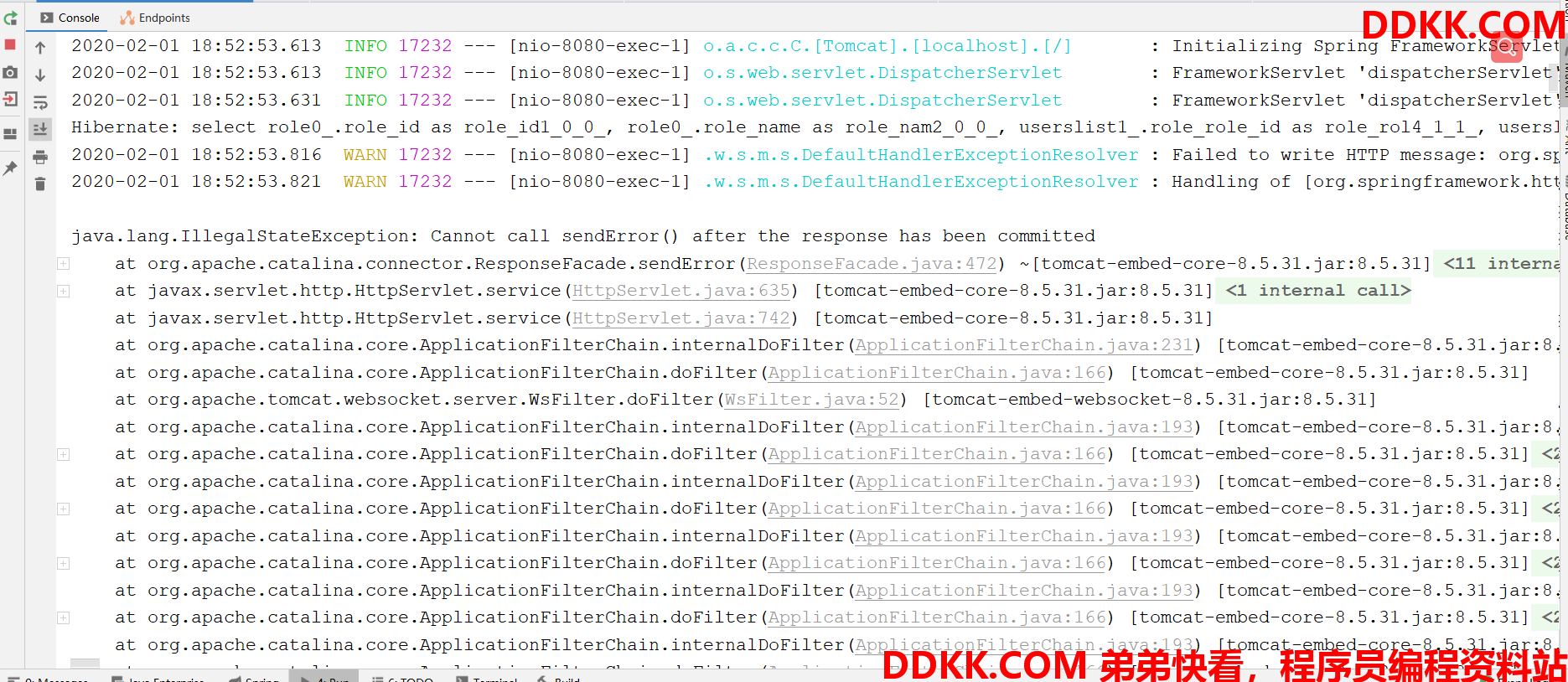
这是为什么呢?这是因为我们上面提到的双向关联,何为双向关联,曰:你中有我,我中有你。Role类中有很多个Users对象,其中每一个Users对象中又都对应一个Role对象,这个Role对象中还对应许多Users对象、、、、、、
所以我们需要怎么解决这个Bug呢?
这一切都要源于双向绑定序列化时的问题,解决办法有很多,这里我推荐一个我最喜欢的
5.修改Role类
/**
* @author DDKK.COM 弟弟快看,程序员编程资料站
* @Date:2022/2/1
* @Description:cn.ddkk.springdatajpa.pojo
* @Version:1.0
*/
/**
* 角色类
*
* @author a2417
*
*/
@Entity
@Table(name="t_role")
public class Role implements Serializable {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
@Column(name="roleId")
private Integer roleId;
@Column(name="roleName")
private String roleName;
@JsonIgnoreProperties("role")
@OneToMany(mappedBy="role")
private Set<Users> usersList=new HashSet<>();
public Set<Users> getUsersList() {
return usersList;
}
public void setUsersList(Set<Users> usersList) {
this.usersList = usersList;
}
public Integer getRoleId() {
return roleId;
}
public void setRoleId(Integer roleId) {
this.roleId = roleId;
}
public String getRoleName() {
return roleName;
}
public void setRoleName(String roleName) {
this.roleName = roleName;
}
}
@JsonIgnoreProperties("role")注解的意思是将下面这个对象中的role字段忽略序列化
6.刷新浏览器

四、小结
今天这篇文章内容有些多,也有些复杂,希望大家好好消化,其实从这里可以看出jpa的强大了,比如我们新增字段,使用Mybaits时需要大量修改xml文件,需要自己去数据库创建字段,现在一个注解完成,还能实现很多其他功能。
今天写这篇文章的时候中途出去了一次,不知道有没有什么纰漏,粗略的浏览的一下应该没有多大问题,如有问题请大家帮忙反馈一下,谢谢大家。