EurekaServer集群机制源码解析
1、集群机制流程图
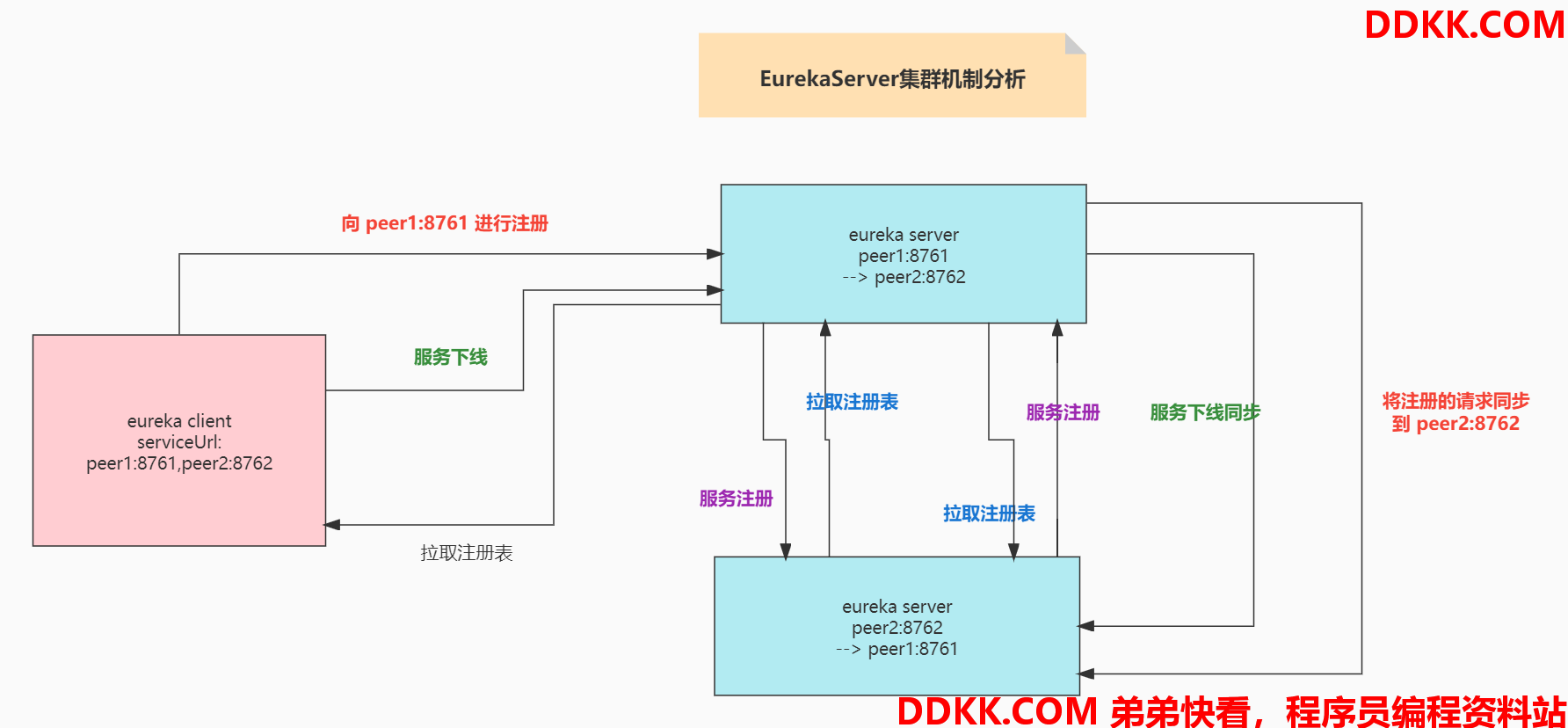
1、集群机制源码解析
1.1 集群信息初始化
eureka core的BootStrap里面,有一块代码,是PeerEurekaNodes的代码,其实是在处理eureka server集群信息的初始化,会执行PeerEurekaNodes.start()方法
解析配置文件中的其他eureka server的url地址,基于url地址构造一个一个的PeerEurekaNode,一个PeerEurekaNode就代表了一个eureka server。启动一个后台的线程,默认是每隔10分钟,会运行一个任务,就是基于配置文件中的url来刷新eureka server列表。
1.1.1 com.netflix.eureka.cluster.PeerEurekaNodes#start
public void start() {
// 1、初始化线程池
taskExecutor = Executors.newSingleThreadScheduledExecutor(
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r, "Eureka-PeerNodesUpdater");
thread.setDaemon(true);
return thread;
}
}
);
try {
// 2、更新 eureka 节点信息
/**
* 2.1 解析 urls
* 2.2 然后根据 url 去构造 PeerEurekaNode(其实就是一个 Eureka Server)
*/
updatePeerEurekaNodes(resolvePeerUrls());
// 3、构建 eureka 节点信息的定时任务
Runnable peersUpdateTask = new Runnable() {
@Override
public void run() {
try {
updatePeerEurekaNodes(resolvePeerUrls());
} catch (Throwable e) {
logger.error("Cannot update the replica Nodes", e);
}
}
};
taskExecutor.scheduleWithFixedDelay(
peersUpdateTask,
// 间隔为 10 分钟
serverConfig.getPeerEurekaNodesUpdateIntervalMs(),
serverConfig.getPeerEurekaNodesUpdateIntervalMs(),
TimeUnit.MILLISECONDS
);
} catch (Exception e) {
throw new IllegalStateException(e);
}
for (PeerEurekaNode node : peerEurekaNodes) {
logger.info("Replica node URL: " + node.getServiceUrl());
}
}
1.1.2 com.netflix.eureka.cluster.PeerEurekaNodes#updatePeerEurekaNodes
protected void updatePeerEurekaNodes(List<String> newPeerUrls) {
if (newPeerUrls.isEmpty()) {
logger.warn("The replica size seems to be empty. Check the route 53 DNS Registry");
return;
}
Set<String> toShutdown = new HashSet<>(peerEurekaNodeUrls);
toShutdown.removeAll(newPeerUrls);
Set<String> toAdd = new HashSet<>(newPeerUrls);
toAdd.removeAll(peerEurekaNodeUrls);
if (toShutdown.isEmpty() && toAdd.isEmpty()) {
// No change
return;
}
// 1、移除不可用的
// Remove peers no long available
List<PeerEurekaNode> newNodeList = new ArrayList<>(peerEurekaNodes);
if (!toShutdown.isEmpty()) {
logger.info("Removing no longer available peer nodes {}", toShutdown);
int i = 0;
while (i < newNodeList.size()) {
PeerEurekaNode eurekaNode = newNodeList.get(i);
if (toShutdown.contains(eurekaNode.getServiceUrl())) {
newNodeList.remove(i);
eurekaNode.shutDown();
} else {
i++;
}
}
}
// 2、添加新的节点
// Add new peers
if (!toAdd.isEmpty()) {
logger.info("Adding new peer nodes {}", toAdd);
for (String peerUrl : toAdd) {
// 2.1 这里可以看到是创建新的 PeerEurekaNode
newNodeList.add(createPeerEurekaNode(peerUrl));
}
}
this.peerEurekaNodes = newNodeList;
this.peerEurekaNodeUrls = new HashSet<>(newPeerUrls);
}
protected PeerEurekaNode createPeerEurekaNode(String peerEurekaNodeUrl) {
// 1、创建一个 HttpReplicationClient
HttpReplicationClient replicationClient = JerseyReplicationClient.createReplicationClient(serverConfig, serverCodecs, peerEurekaNodeUrl);
String targetHost = hostFromUrl(peerEurekaNodeUrl);
if (targetHost == null) {
targetHost = "host";
}
// 2、基于 registry、targetHost、peerEurekaNodeUrl、replicationClient、serverConfig 来实例化 PeerEurekaNode。
return new PeerEurekaNode(registry, targetHost, peerEurekaNodeUrl, replicationClient, serverConfig);
}
// 看一下 PeerEurekaNode 的构造器
PeerEurekaNode(PeerAwareInstanceRegistry registry, String targetHost, String serviceUrl,
HttpReplicationClient replicationClient, EurekaServerConfig config,
int batchSize, long maxBatchingDelayMs,
long retrySleepTimeMs, long serverUnavailableSleepTimeMs) {
// 1、基本的赋值
/** registry -> 注册表、
* targetHost -> 目标主机、
* replicationClient -> jerserclient用于处理请求
* serviceUrl -> 服务的 url
* config -> 服务端的配置
* maxProcessingDelayMs -> 复制延迟时间
* batcherName
*/
this.registry = registry;
this.targetHost = targetHost;
this.replicationClient = replicationClient;
this.serviceUrl = serviceUrl;
this.config = config;
this.maxProcessingDelayMs = config.getMaxTimeForReplication();
String batcherName = getBatcherName();
// 2、这个就是 replication 复制的具体的任务执行者,通过他去调度任务
ReplicationTaskProcessor taskProcessor = new ReplicationTaskProcessor(targetHost, replicationClient);
// 3、创建 batchingDispatcher、nonBatchingDispatcher(批量处理、非批量处理的任务分发组件)
this.batchingDispatcher = TaskDispatchers.createBatchingTaskDispatcher(
batcherName,
config.getMaxElementsInPeerReplicationPool(),
batchSize,
config.getMaxThreadsForPeerReplication(),
maxBatchingDelayMs,
serverUnavailableSleepTimeMs,
retrySleepTimeMs,
taskProcessor
);
this.nonBatchingDispatcher = TaskDispatchers.createNonBatchingTaskDispatcher(
targetHost,
config.getMaxElementsInStatusReplicationPool(),
config.getMaxThreadsForStatusReplication(),
maxBatchingDelayMs,
serverUnavailableSleepTimeMs,
retrySleepTimeMs,
taskProcessor
);
}
1.2 集群信息拉取
registry.syncUp()
就是说,当前这个eureka server会从任何一个其他的eureka server拉取注册表过来放在自己本地,作为初始的注册表。将自己作为一个eureka client,找任意一个eureka server来拉取注册表,将拉取到的注册表放到自己本地去。
eurekaClient.getApplications();
eureka server自己本身本来就是个eureka client,在初始化的时候,就会去找任意的一个eureka server拉取注册表到自己本地来,把这个注册表放到自己身上来,作为自己这个eureka server的注册表
1.2.1 com.netflix.eureka.registry.PeerAwareInstanceRegistryImpl#syncUp
/**
* 从对等的 Eureka 节点填充注册表信息。 如果通信失败,此操作将故障转移到其他节点,直到列表用完为止
*/
@Override
public int syncUp() {
// Copy entire entry from neighboring DS node
int count = 0;
// 1、默认配置是 5(getRegistrySyncRetries)
for (int i = 0; ((i < serverConfig.getRegistrySyncRetries()) && (count == 0)); i++) {
if (i > 0) {
try {
Thread.sleep(serverConfig.getRegistrySyncRetryWaitMs());
} catch (InterruptedException e) {
logger.warn("Interrupted during registry transfer..");
break;
}
}
Applications apps = eurekaClient.getApplications();
for (Application app : apps.getRegisteredApplications()) {
for (InstanceInfo instance : app.getInstances()) {
try {
// 2、不使用 Amazon 都返回 true.(Everything non-amazon is registrable.)
if (isRegisterable(instance)) {
// 3、然后就是调用 com.netflix.eureka.registry.AbstractInstanceRegistry#register 这个之前已经分析过了就不说了。
// 只不过这里 isReplication 参数为 true.就是标识此次是复制
register(instance, instance.getLeaseInfo().getDurationInSecs(), true);
count++;
}
} catch (Throwable t) {
logger.error("During DS init copy", t);
}
}
}
}
return count;
}
1.3 注册、下线、故障、心跳
1、 如何从一台eureka server同步到另外一台eureka server上去的
2、ApplicationResource的addInstance()方法,负责注册,先在自己本地完成一个注册,接着会replicateToPeers()方法,这个方法就会将这次注册请求,同步到其他所有的eureka server上去.
3、如果是某台eureka client来找eureka server进行注册,isReplication是false,此时会给其他所有的你配置的eureka server都同步这个注册请求,此时一定会基于jersey,调用其他所有的eureka server的restful接口,去执行这个服务实例的注册的请求
4、eureka-core-jersey2的工程,ReplicationHttpClient,此时同步注册请求给其他eureka server的时候,一定会将isReplication设置为true,这个东西可以确保说什么呢,其他eureka server接到这个同步的请求,仅仅在自己本地执行,不会再次向其他的eureka server去进行注册
2、集群运行项目
2.1 EurekaServer 项目
2.1.1 pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.bamboo</groupId>
<artifactId>eureka-server</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>eureka-server</name>
<url>http://maven.apache.org</url>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.5.13.RELEASE</version>
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Edgware.SR3</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka-server</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>
2.1.2 java 代码
@SpringBootApplication
@EnableEurekaServer
public class EurekaServer {
public static void main(String[] args) {
SpringApplication.run(EurekaServer.class, args);
}
}
2.1.3 配置文件
- peer1 配置
server:
port: 8761
eureka:
instance:
hostname: peer1
client:
serviceUrl:
defaultZone: http://peer2:8762/eureka/
- peer2 配置:
server:
port: 8762
eureka:
instance:
hostname: peer2
client:
serviceUrl:
defaultZone: http://peer1:8761/eureka/
启动的时候可以在 idea 中 copy 一个运行实例,然后在 vm options 中输入运行参数,默认会覆盖 yaml 中的配置
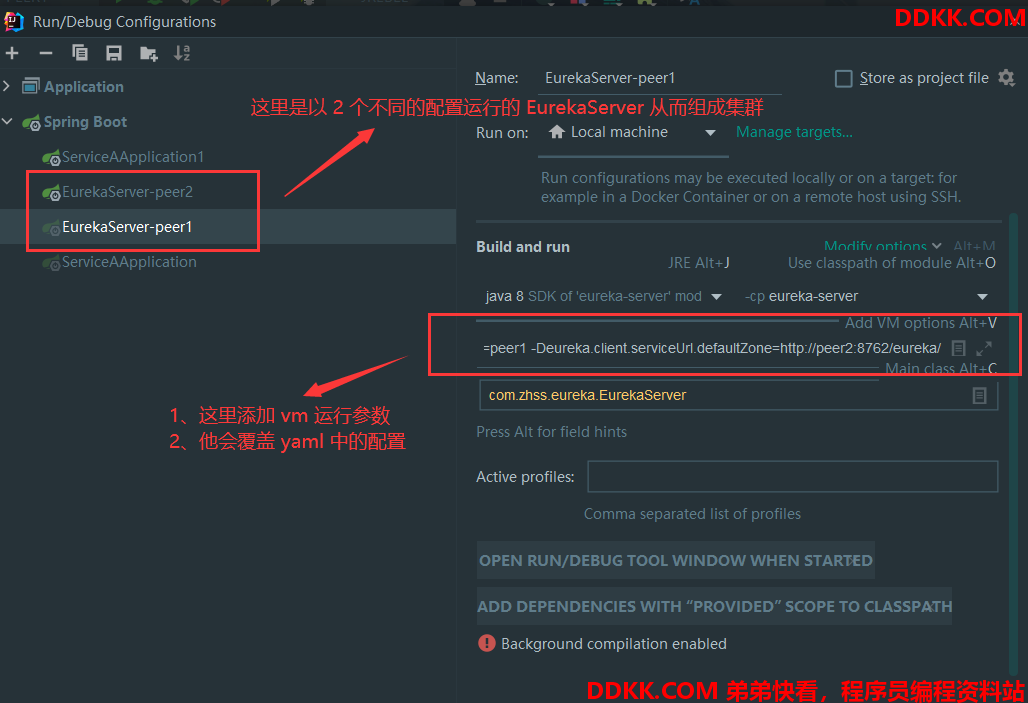
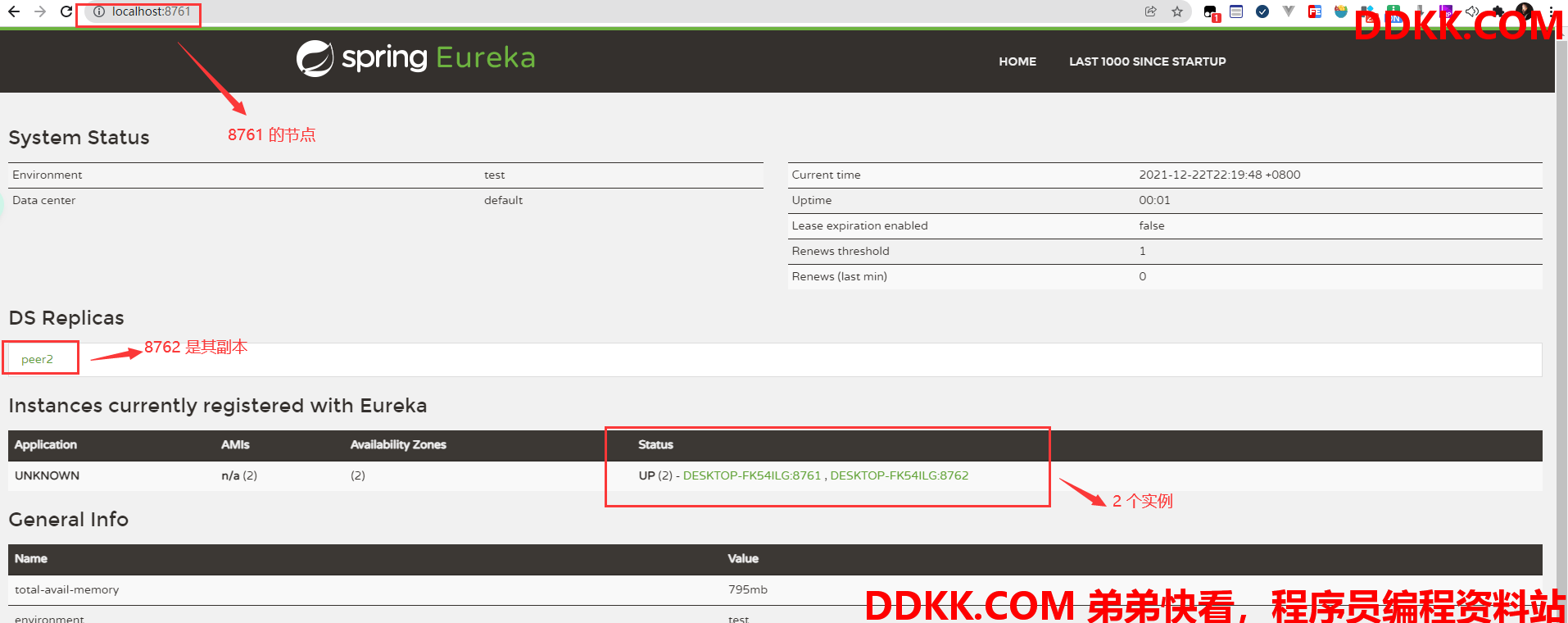
启动之后的状态如下图所示:
peer1:(8761 节点)
peer2:(8762 节点)
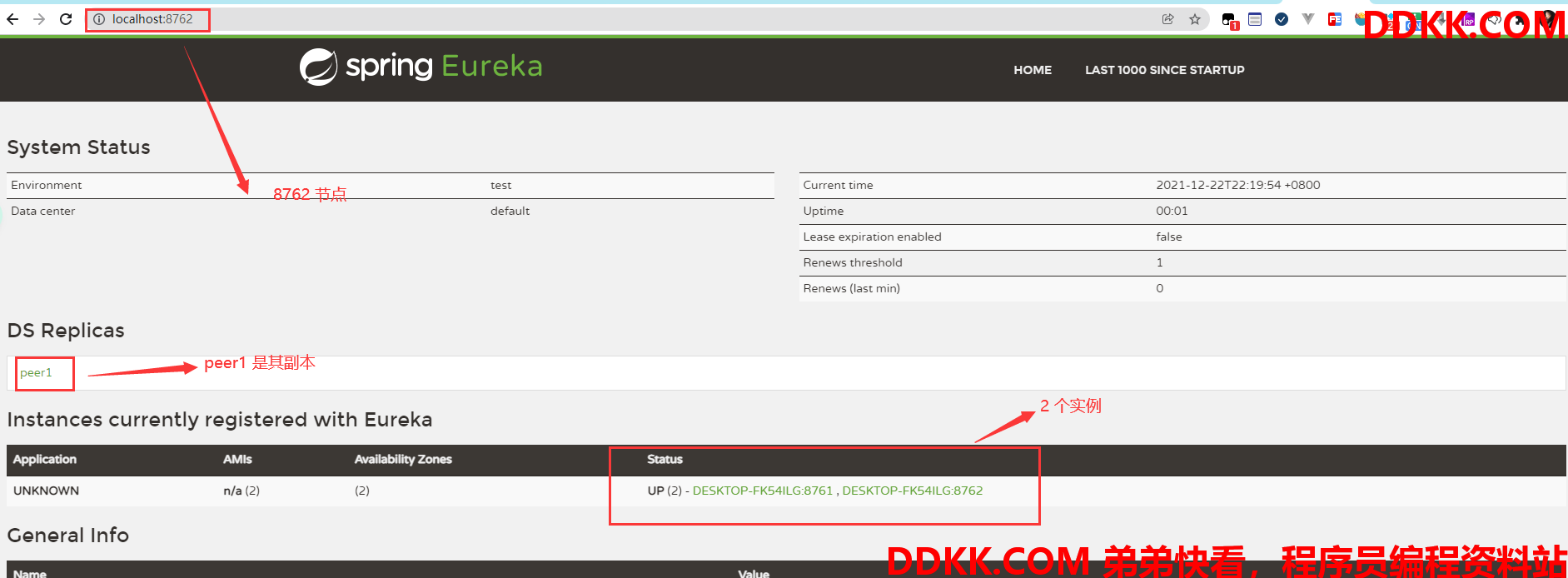
所以 2 者的同步是没有问题的,跟我们分析的一致。
版权声明:「DDKK.COM 弟弟快看,程序员编程资料站」本站文章,版权归原作者所有