一、Server服务端架构组件
1.前话
Zookeeper有集群和单机模式,鉴于一开始学习Zookeeper源码,因此从单机切入,先了解其主要的组件及其相关功能,等基础功打好之后再去深入了解Zookeeper的集群模式。
对于Zookeeper有以下疑问,Zookeeper的主要组件有哪些?其中大致的功能又是什么?为什么服务端的数据结构是树状的?和Client端的交互对象又是什么?带着这些疑问编写了这篇文章。
Zookeeper整体的架构及结构组成网上随便一搜全有,但可惜的便是基本都是同一篇,要想找到不同的分析得翻N页说不定还是找不到。本人在会简单的使用Zookeeper完成某些操作后对于其服务端和客户端的主要组件架构组成及交互流程十分感兴趣,尝试先通过网上搜索资料进行学习,但是基本上没有这种的分析,依旧是同一篇文章抄来抄去,甚是无趣。
因此只能自己通过源码逐步分析其内部组成以及交互流程了,整个流程分析可能会存在不对或者遗漏的地方,如果对此有研究的小伙伴发现了欢迎指正。
注:本篇基于ZK版本3.4.8分析的,且归为基本组件都是个人认为在ZK的执行流程中完成主要功能必不可少的组件。
2.基本组件
其Server端基本重要组件如下:
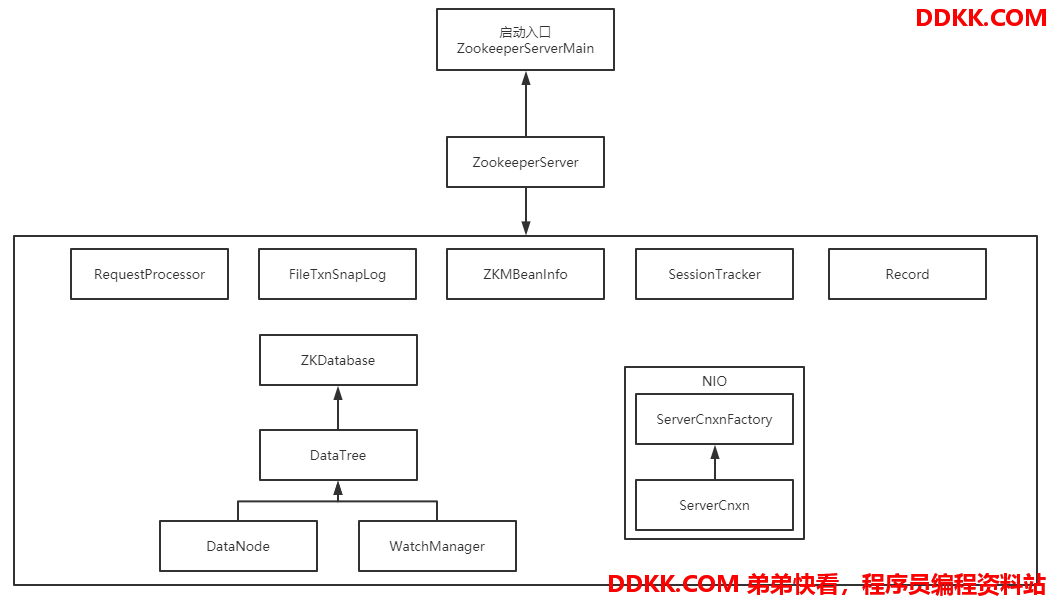
从图中可以看到基本有九个主要组件,包括启动入口一起来简要的说明下其功能及组成:
1、 ZookeeperServerMain:这个类是ZK单机启动的启动入口,QuorumPeerMain是集群ZK的启动入口,等以后分析到集群的时候再来讲解当然,启动入口使用QuorumPeerMain也是可以的,只要把入参形式传成单机的即可而对于其作用也很简单,启动ZK的各类Thread处理线程以及生成ZK的文件日志;
2、 ZookeeperServer:单机的实例类型,这个类的对象实例就是ZK的server实例如果是集群模式实例类型将会是其实现子类,包括Leade、Follower和Observer这些角色,都是其实现子类;如果把ZK服务比喻成人,那么这个类的实例就是具体的某个人,其重要的组件便是人的一些重要的器官,互相协调完成某种动作和功能;
3、 RequestProcessor:看名字便可以得知,这个组件的作用便是用来处理Request请求的在ZK实例中,会有多个RequestProcessor实例链,每个实例都会对Request对象进行某种操作;
4、 FileTxnSnapLog:用来管理TxnLog和SnapShot对象和其对应的File对象,TxnLog实现类的作用便是提供操作Txn日志文件的api方法,SnapShot实现类的作用便是保存、序列化和反序列化快照的功能;
5、 ZKMBeanInfo:ZK的主要类信息接口,用来方便对接JMX代理服务,进而实现对JVM中的这些类进行监控,主要用于监控管理;
6、 SessionTracker:ZK服务端用来追踪session的组件,单机和集群leader使用的是同一个,而Follower使用的是简单的Shell来跟踪转发给leader的;
7、 Record:在ZK中是信息承载的角色,诸如各种的Request、Response和DataNode这些都是属于该接口的实现类,这个接口提供了序列化和反序列化接口标准;
8、 ZKDatabase:维护内存中ZK关于session、datatree和提交日志的内存数据库,在从硬盘上读取日志和快照时将会被创建这个组件主要由DataTree、DataNode、WatchManager和Watcher等几个部分组成,这几个部分主要负责存储记录ZK的节点数据以及节点数据的监听功能,而Watcher接口则是Server端和Client端共用的监听接口;
9、 NIO的ServerCnxn等:这次只分析通过NIO进行连接的ZK服务端,Netty的暂不分析ServerCnxn是Client端连接到Server端的实际实例类型,而其对象将是从ServerCnxnFactory工厂对象中产生的;
接下来分析一下上述几个组件中最关键的几个重要组件。
2.1 RequestProcessor
先看下在单机模式下该组件的组成情况,UML类图如下:
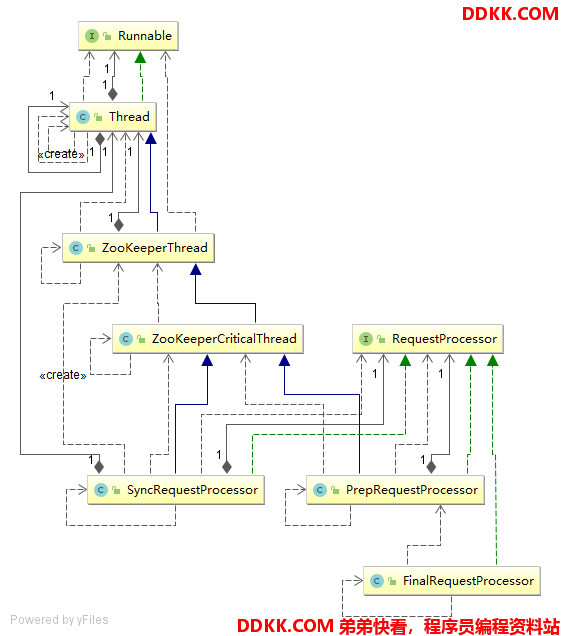
从图中可以看到PrepRequestProcessor和SyncRequestProcessor都是一个线程子类,而在实际的ZK服务端运行过程中这两个就是以线程轮询的方式异步执行的。FinalRequestProcessor实现类只实现了RequestProcessor接口,因此这个类的流程是同步的,为什么呢?因为这个类一般都是处理所有的请求类型,且在RequestProcessor调用链的末尾,没有nextProcessor,因此便不需要像其它的RequestProcessor实现类一样使用线程轮询的方式来处理请求。
其用到的三个重要实现子类功能分别如下:
1、 PrepRequestProcessor:RequestProcessor的开始部分,根据请求的参数判断请求的类型,如create、delete操作这些,随后将会创建相应的Record实现子类,进行一些合法性校验以及改动记录;
2、 SyncRequestProcessor:同步刷新记录请求到日志,在将请求的日志同步到磁盘之前,不会把请求传递给下一个RequestProcessor;
3、 FinalRequestProcessor:为RequestProcessor的末尾处理类,从名字也能看出来,基本上所有的请求都会最后经过这里此类将会处理改动记录以及session记录,最后会根据请求的操作类型更新对象的ServerCnxn对象并回复请求的客户端;
2.2 Record
现在以创建节点的操作为例,稍微看下这个操作涉及的具体类以及各自的功能作用。大致图如下:
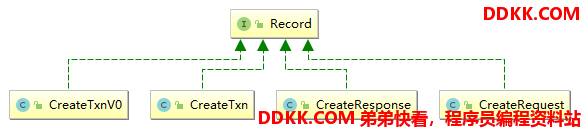
前面说过Record接口实现类在ZK中是信息承载的角色,以创建节点为实例,来分析Record如何实现的。Record接口一共只有两个方法,serialize()序列化和deserialize()反序列化方法,我们都知道ZK是通过网络在Server间及Client端间进行交互的,因此如何传递携带的消息就是一个重要的问题。而ZK的处理方式则是为每一种操作提供对应的Request和Response,每个Request和Response都有各自不一样的序列化反序列化规则。
CreateTxn代表着一次创建请求实例,ZK很多地方都用到了Txn后缀,那么txn具体是什么意思呢?在英语中txn为transaction的缩写,因此CreateTxn从字面意思上理解就是创建事务对象。
以一次ZK Client端向Server端请求创建节点请求为例,ZK的做法是使用一个RequestHeader对象和CreateRequest分别序列化并组合形成一次请求,到ZK Server端先反序列化RequestHeader获取Client端的请求类型,再根据不同的请求类型使用相应的Request对象反序列化,这样Server端和Client端就可以完成信息的交互。相应也是一样的步骤,只是RequestHeader变成了ReplyHeader,而Request变成了Response。大致交互图如下:
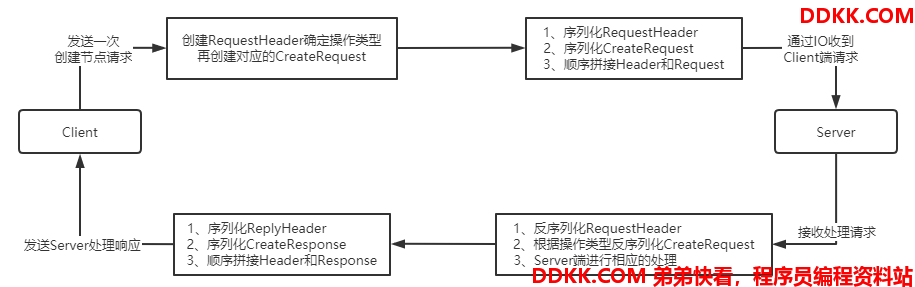
了解这个过程十分重要,因为ZK的Server和Client端的数据交互就是根据这种模式进行的,只是IO传输ZK提供了NIO和Netty两种方式。
2.3 DataTree及DataNode监听
其中关键类的组成依赖关系如下:
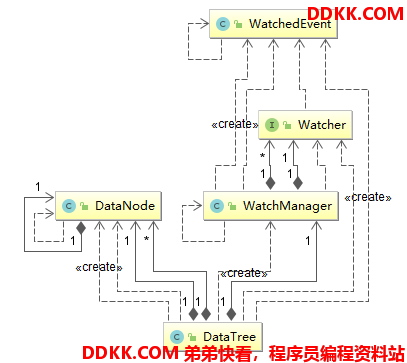
接下来详细介绍下这些子组件:
1、 DataTree:我们都知道ZK的数据结构就是类似于文件夹式的树状结构,其原因便是该对象的数据结构组成这个类维护了树状数据结构,其没有任何的网络操作以及连接相关代码在这里面,只会操作DataNode数据节点其维护了两个平行的数据结构:一个是节点全路径和DataNode的对应关系HashMap,一个是DataNode对象的树状结构;
2、 DataNode:存储数结构DataTree的数据节点,也包括父节点和所有子节点的引用关系;
3、 WatchManager:用来管理多个Watcher实现类的,可以用来记录全路径和Watcher的关联关系,也可以删除Watcher和触发路径的对应Watcher;
4、 Watcher:ZK监听通知实现的重要接口,Server端和Client共用同一个接口Client连接端将会通过这些Watcher获得多种事件,同时也会通过Client端注册的Watcher发送回调对象处理这些事件;
5、 WatchedEvent:当Watcher监听生效时,不同的事件类型将会被保存到这个类中,包括ZK当前的状态、触发事件类型和事件对应的节点路径;
另外提一嘴,在ZK的Server端中,闻名遐迩的监听事件发布机制都是在DataTree中使用监听器管理对象WatchManager触发的,入口便是processTxn()方法。
2.4 NIO的ServerCnxn组件
这部分组件的主要组件如下图:
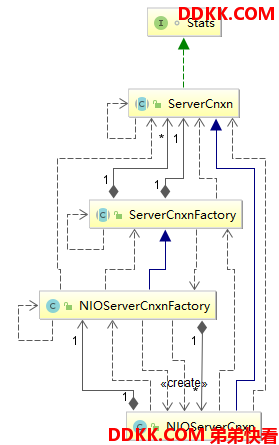
鉴于Netty不够熟悉,因此暂时根据研究过使用流程的NIO来分析ZK的流程。这里面有很多的Cnxn缩写,为什么使用Cnxn这个缩写?很多和连接相关的类都会有Cnxn缩写,个人猜测类似于txn表示transaction缩写,因此cnxn应该是表示connectio缩写,了解了这个之后接下来看这种缩写的类名称就可以很好理解了。接下来详细介绍一下这几个类:
1、 ServerCnxn:在Server端连接的抽象父类,其每个实现子类都代表着Client端在Server端的连接根据前面的缩写也能知道其全名称应该是ServerConnection,即服务连接;
2、 NIOServerCnxn:ServerCnxn的实现子类,使用NIO来处理Client端的连接通信请求,每个客户端在Server端对应一个ServerCnxn实例在类中有NIO的SocketChannel和SelectionKey这种具体的连接相关类;
3、 ServerCnxnFactory:ZK的Server端生成ServerCnxn实例是使用工厂模式,这个类便是抽象父类工厂;
4、 NIOServerCnxnFactory:用来生产NIOServerCnxn类实例的工厂,并且还含有NIO的选择器Selector和ServerSocketChannel类,用来对Client端的连接进行多路复用;
5、 Stats:这个接口提供了每个ServerCnxn的参数获取方法,诸如zxid、cxid和lastOperation等这样的连接参数;
3.启动流程
上面已经介绍过各个组件的大致作用,接下来看下ZK在启动的时候的流程,流程图如下:
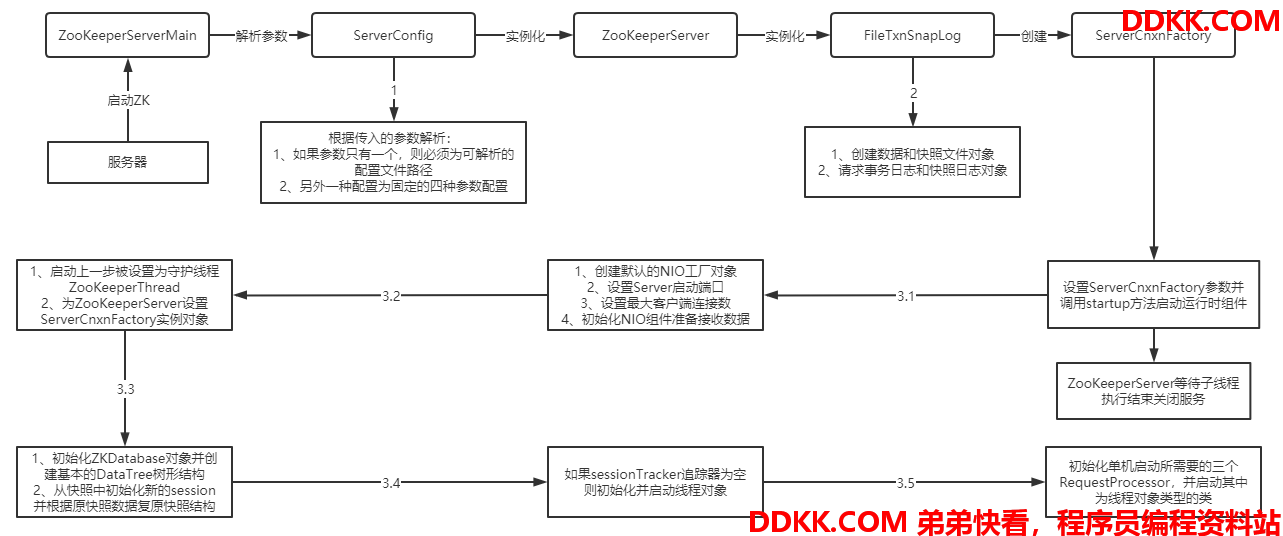
接下来逐一分析一下其中的一点细节:
1、 解析参数步骤:在ServerConfig对象解析参数时,如果参数长度为1则代表着指定配置文件路径,而后会使用集群启动用的QuorumPeerConfig去解析对应的配置文件获取相应的配置;另外一种情况参数长度只能是3或4位,一是Server端启动端口地址clientPortAddress,二是数据和日志目录dataDir,三是心跳间隔时间tickTime,四是最大客户端连接数maxClientCnxns;
2、 在3.1当中:如果未指定ServerCnxnFactory类型将会默认指定NIO类型,且在工厂类中会打开NIO的ServerSocketChannel绑定刚刚配置的端口地址,并且注册到NIO的选择器Selector中实现IO多路复用此外,在这个步骤里面还会以ServerCnxnFactory为运行线程创建一个类型是ZooKeeperThread的守护线程;
3、 在3.3当中:在实例化ZKDatabase将root节点初始化后,将会读取快照日志,将快照中的数据再重新初始化成树状的DataTree对象,同时生成最新的zxid,把快照中已经死亡的连接去除;
4、 在3.5当中:单机的RequestProcessor一共有三个,前面说过,其中两个是线程对象,另一个是处于最末尾的FinalRequestProcessor,用来处理请求并返回Response给Client端;
接下来开始进行简单的源码分析。
二、启动流程源码简析
1.入口启动类ZooKeeperServerMain
其关键源码如下:
public class ZooKeeperServerMain {
private ServerCnxnFactory cnxnFactory;
public static void main(String[] args) {
ZooKeeperServerMain main = new ZooKeeperServerMain();
try {
// 和Java普通的启动类一样,也是一个main函数,进行调用其它的方法
main.initializeAndRun(args);
} // 处理异常略过...
}
protected void initializeAndRun(String[] args)
throws ConfigException, IOException {
try {
// 注册Log4j日志
ManagedUtil.registerLog4jMBeans();
}// 异常略过...
// 客户端的配置对象
ServerConfig config = new ServerConfig();
if (args.length == 1) {
// 如果参数只有一位,则意味着只传了配置文件路径
config.parse(args[0]);
} else {
// 如果参数有多个,则每个位置都是具体的参数值
config.parse(args);
}
// 根据前面解析获得的配置对象进行进一步的配置
runFromConfig(config);
}
public void runFromConfig(ServerConfig config) throws IOException {
// 在这个方法流程中,执行的大致功能为实例化其它的线程对象并启动
// 根据传进来的参数创建日志文件
FileTxnSnapLog txnLog = null;
try {
ZooKeeperServer zkServer = new ZooKeeperServer();
// 在FileTxnSnapLog的构造方法中会创建数据和快照文件夹对象
// 如果文件夹为空则会新建一个
txnLog = new FileTxnSnapLog(new File(config.dataLogDir),
new File(config.dataDir));
// 接下来的四个参数便是从args对象传进来解析获取到的
zkServer.setTxnLogFactory(txnLog);
zkServer.setTickTime(config.tickTime);
zkServer.setMinSessionTimeout(config.minSessionTimeout);
zkServer.setMaxSessionTimeout(config.maxSessionTimeout);
// 创建的默认类型是NIOServerCnxnFactory,使用NIO进行IO多路复用
cnxnFactory = ServerCnxnFactory.createFactory();
// 会打开绑定端口地址到NIO对象上,稍后看下该方法
cnxnFactory.configure(config.getClientPortAddress(),
config.getMaxClientCnxns());
// 开始启动和配置ZK运行时所需要的重要组件,基本都是启动相应线程对象
cnxnFactory.startup(zkServer);
// 等待cnxnFactory对象启动的子线程执行结束再往下走,否则阻塞
cnxnFactory.join();
// 跑到处理说明cnxnFactory的子线程都停止了
if (zkServer.isRunning()) {
// 如果ZK还是正常运行则需要关闭
zkServer.shutdown();
}
}// 异常忽略...
finally {
if (txnLog != null) {
txnLog.close();
}
}
}
}
2.解析配置类ServerConfig
其关键源码如下:
public class ServerConfig {
// 端口和ip的存储对象
protected InetSocketAddress clientPortAddress;
// 数据文件夹以及日志文件夹路径
protected String dataDir;
protected String dataLogDir;
// 检测心跳的间隔时间
protected int tickTime = ZooKeeperServer.DEFAULT_TICK_TIME;
// 最大客户端连接数
protected int maxClientCnxns;
// 最小的session过期时间
protected int minSessionTimeout = -1;
// 最大的session过期时间
protected int maxSessionTimeout = -1;
public void parse(String path) throws ConfigException {
// 如果传进来的是文件夹路径则使用QuorumPeerConfig对象去解析
QuorumPeerConfig config = new QuorumPeerConfig();
// 开始解析文件
config.parse(path);
// 将解析获得的配置文件属性进行赋值
readFrom(config);
}
public void readFrom(QuorumPeerConfig config) {
// 分别对成员对象进行赋值
// 略...
}
public void parse(String[] args) {
// 参数长度必须为3-4,否则抛异常
if (args.length < 2 || args.length > 4) {
// 抛异常忽略...
}
// 第一个是ip和端口
// 第二个是数据日志路径
// 第三个是心跳检测间隔时间
// 第四个是客户端最大连接数
// 具体赋值略过...
}
}
3.NIOServerCnxnFactory设置主要启动组件
主要关键源码如下:
public class NIOServerCnxnFactory extends ServerCnxnFactory
implements Runnable {
static {
// 为了防止JVM的bug,使用Selector.open()包NULL异常
// 但这是JDK1.5版本的BUG,到了1.8版本应该修复了
try {
// 因此在加载该类是就需要先打开再关闭
Selector.open().close();
}// 异常略过...
}
// NIO的Server端SocketChannel对象,用来和Client端的SocketChannel通信
ServerSocketChannel ss;
// NIO的IO多路复用选择器
final Selector selector = Selector.open();
// Client连接默认最多60个
int maxClientCnxns = 60;
// 将会被执行的线程对象
Thread thread;
@Override
public void configure(InetSocketAddress addr, int maxcc)
throws IOException {
// 设置SASL登录相关的,略过
configureSaslLogin();
// 声明一个ZooKeeperThread类型的线程对象,且执行线程为本身
// 这个线程的执行放到后续的ZK运行时分析
thread = new ZooKeeperThread(this, "NIOServerCxn.Factory:" + addr);
// 设置为守护线程
thread.setDaemon(true);
// 设置最大客户端连接数
maxClientCnxns = maxcc;
// 开始打开Server通道并绑定端口和地址
this.ss = ServerSocketChannel.open();
ss.socket().setReuseAddress(true);
ss.socket().bind(addr);
ss.configureBlocking(false);
// 注册到Selector选择器
ss.register(selector, SelectionKey.OP_ACCEPT);
}
@Override
public void startup(ZooKeeperServer zks) throws IOException,
InterruptedException {
// 启动刚刚实例化的ZooKeeperThread线程
start();
// 关联ZooKeeperServer对象和工厂对象的关系
setZooKeeperServer(zks);
// 开始启动复原ZooKeeperServer的数据结构及session数据
zks.startdata();
// 正式启动ZooKeeperServer的主要组件
zks.startup();
}
}
4.单机Server类ZooKeeperServer
其关键源码如下:
public class ZooKeeperServer
implements SessionExpirer, ServerStats.Provider {
protected ZooKeeperServerBean jmxServerBean;
protected DataTreeBean jmxDataTreeBean;
// 默认心跳间隔时间
public static final int DEFAULT_TICK_TIME = 3000;
// 声明的session追踪
protected SessionTracker sessionTracker;
// ZK的database,其中包含了zk的数据结构节点信息以及监听器的信息
private ZKDatabase zkDb;
// 重要组件RequestProcessor调用链
protected RequestProcessor firstProcessor;
// server实例对象的初始状态
protected volatile State state = State.INITIAL;
// 绑定的ServerCnxnFactory
private ServerCnxnFactory serverCnxnFactory;
// 服务的状态对象
private final ServerStats serverStats;
// 服务监听器,目前的作用为用来停止ZK的Server实例
private final ZooKeeperServerListener listener =
new ZooKeeperServerListenerImpl();
// 下面四个参数便不做分析了
protected int tickTime = DEFAULT_TICK_TIME;
private FileTxnSnapLog txnLogFactory = null;
protected int minSessionTimeout = -1;
protected int maxSessionTimeout = -1;
public void startdata() throws IOException, InterruptedException {
// 如果zkDb对象为空则实例化
if (zkDb == null) {
// 实例化中会创建DataTree对象,并添加基础的root节点
zkDb = new ZKDatabase(this.txnLogFactory);
}
// 未初始化则加载快照来重新构建DataTree对象
if (!zkDb.isInitialized()) {
loadData();
}
}
public synchronized void startup() {
// 创建实例化sessionTracker对象并启动sessionTracker线程对象
if (sessionTracker == null) {
createSessionTracker();
}
startSessionTracker();
// 设置单机模式下的三个重要RequestProcessor
setupRequestProcessors();
// 注册到JMX中,以方便监控
registerJMX();
// 设置状态为运行
state = State.RUNNING;
// 唤醒所有线程
notifyAll();
}
protected void setupRequestProcessors() {
// 通过编码的方式确定各个RequestProcessor的前后关系以及手动启动
// RequestProcessor线程类型的对象
// 第一个RequestProcessor类型为调用链的FinalRequestProcessor类型
// 负责最后Response响应对象的实例化以及拼装
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
// 接下来的两个全是线程对象,大致功能这里便不做过多的分析了
RequestProcessor syncProcessor = new SyncRequestProcessor(this,
finalProcessor);
((SyncRequestProcessor)syncProcessor).start();
firstProcessor = new PrepRequestProcessor(this, syncProcessor);
((PrepRequestProcessor)firstProcessor).start();
}
public void loadData() throws IOException, InterruptedException {
// 如果是集群模式,这个方法将会由leader调用,用来初始化zkDb中的
// DataTree并形成树形结构,而单机模式这个方法是一定会被调用的
if(zkDb.isInitialized()){
// 如果已经初始化了则只需要设置最新的zxid
setZxid(zkDb.getDataTreeLastProcessedZxid());
} else {
// 没有初始化则需要加载数据
setZxid(zkDb.loadDataBase());
}
// 清理已经死亡的session
LinkedList<Long> deadSessions = new LinkedList<Long>();
for (Long session : zkDb.getSessions()) {
if (zkDb.getSessionWithTimeOuts().get(session) == null) {
deadSessions.add(session);
}
}
// 设置为已经初始化
zkDb.setDataTreeInit(true);
for (long session : deadSessions) {
// 正式杀死已死亡session
killSession(session, zkDb.getDataTreeLastProcessedZxid());
}
}
}
5.ZKDatabase加载数据
其关键源码如下:
public class ZKDatabase {
protected DataTree dataTree;
protected ConcurrentHashMap<Long, Integer> sessionsWithTimeouts;
protected FileTxnSnapLog snapLog;
public ZKDatabase(FileTxnSnapLog snapLog) {
实例化DataTree对象
dataTree = new DataTree();
sessionsWithTimeouts = new ConcurrentHashMap<Long, Integer>();
this.snapLog = snapLog;
}
public long loadDataBase() throws IOException {
// 用来存放被触发的提交日志
PlayBackListener listener=new PlayBackListener(){
public void onTxnLoaded(TxnHeader hdr,Record txn){
Request r = new Request(null, 0, hdr.getCxid(),
hdr.getType(),
null, null);
r.txn = txn;
r.hdr = hdr;
r.zxid = hdr.getZxid();
addCommittedProposal(r);
}
};
// 加载快照数据到dataTree对象将由snapLog对象完成
long zxid = snapLog
.restore(dataTree,sessionsWithTimeouts,listener);
initialized = true;
return zxid;
}
}
6.数据快照日志对象FileTxnSnapLog
其关键源码如下:
public class FileTxnSnapLog {
private SnapShot snapLog;
public long restore(DataTree dt, Map<Long, Integer> sessions,
PlayBackListener listener) throws IOException {
// 反序列化快照文件到dataTree中
snapLog.deserialize(dt, sessions);
FileTxnLog txnLog = new FileTxnLog(dataDir);
// 加载连接日志
TxnIterator itr = txnLog.read(dt.lastProcessedZxid+1);
// 最大的zxid,表示最新的zxid
long highestZxid = dt.lastProcessedZxid;
TxnHeader hdr;
try {
// 开始遍历连接日志
while (true) {
// iterator points to
// the first valid txn when initialized
hdr = itr.getHeader();
if (hdr == null) {
// 日志为空,直接返回最新的zxid
return dt.lastProcessedZxid;
}
if (hdr.getZxid() < highestZxid && highestZxid != 0) {
// 抛出异常...
} else {
highestZxid = hdr.getZxid();
}
try {
// 这个方法十分重要,里面调用了DataTree的执行处理连接方法
processTransaction(hdr,dt,sessions, itr.getTxn());
}// 异常忽略...
// 处理成功,记录到提交日志中
listener.onTxnLoaded(hdr, itr.getTxn());
// 没有下一个了,退出循环
if (!itr.next())
break;
}
} finally {
if (itr != null) {
itr.close();
}
}
return highestZxid;
}
public void processTransaction(TxnHeader hdr,DataTree dt,
Map<Long, Integer> sessions, Record txn)
throws KeeperException.NoNodeException {
ProcessTxnResult rc;
// 不同的header操作类型调用的都是DataTree的processTxn方法
switch (hdr.getType()) {
case OpCode.createSession:
// 当有新连接进来时,将会进入这里,添加新的session信息
sessions.put(hdr.getClientId(),
((CreateSessionTxn) txn).getTimeOut());
// 调用DataTree的processTxn,所有的操作类型最终都会进入到这个
// 方法里面,等后面分析运行流程时再进一步分析
rc = dt.processTxn(hdr, txn);
break;
case OpCode.closeSession:
// 当有连接关闭时把session进行删除
sessions.remove(hdr.getClientId());
rc = dt.processTxn(hdr, txn);
break;
default:
// 不是新连接和关闭连接,则直接进入普通的操作类型,在这里面将会完成
// 不同操作类型的转发处理
rc = dt.processTxn(hdr, txn);
}
}
}
源码分析暂时就到此为止,启动流程这次只分析了同步流程,并且深度只到了DataTree,因为DataTree里面的逻辑很多,并且后续运行时的流程这回涉及,因此本次分析源码点到为止,下次分析源码再来。