1、搜索结果字段解析
首先插入一条测试数据
PUT /my_index/_doc/1
{
"title": "2019-09-10"
}
然后无条件搜索所有
GET my_index/_search
得到的结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "2019-09-10"
}
}
]
}
}
解释
took:took表示Elasticsearch执行搜索所用的时间,单位是毫秒。这里0毫秒代表特别快,实际上一般都在几十毫秒以上。
timed_out:是否超时,这里是没有
_shards:指示搜索了多少分片,成功几个,跳过几个,失败几个。
hits.total:查询结果的数量,3个document
hits.max_score:score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高
hits.hits:包含了匹配搜索的document的所有详细数据
2、time_out字段解析
例如下图所示:存在一个book索引,2个分片,0副本。
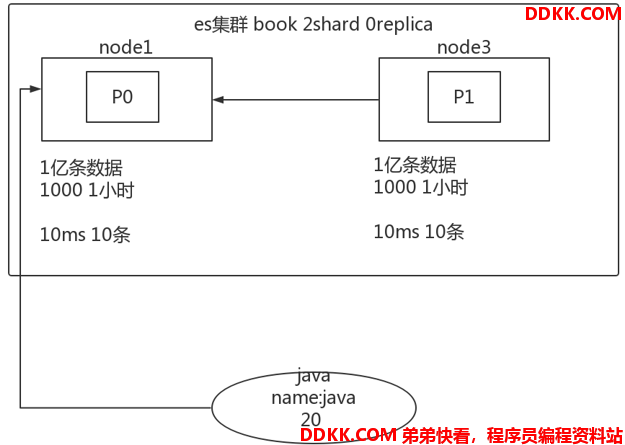
两个节点上都存在1亿条数据,假如说搜索10条,只需要10ms,这样对前端没啥影响,但是数据量太大时,搜索1个分片都需要10分钟的话,而且ES搜索的请求是每个主分片都要进行搜索,那么这个时间还得加长。这样情况下,用户肯定是受不了的。
于是引出time_out机制。指定每个shard只能在给定时间内查询数据,能有几条就返回几条。这样至少能搜索出来结果,用户也能好受一点。