1、 Logstash输入插件
1.1 input介绍
logstash支持很多数据源,比如说file,http,jdbc,s3等等
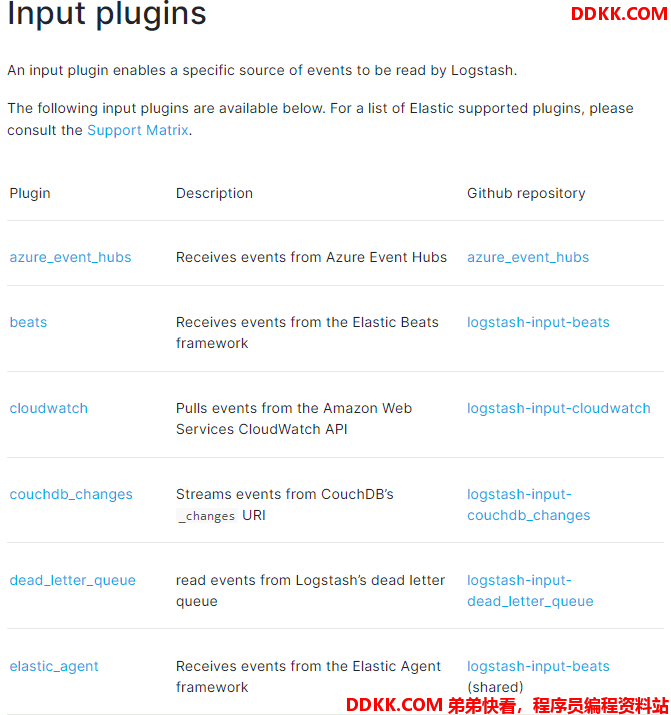
图片上面只是一少部分。详情见网址:https://www.elastic.co/guide/en/logstash/current/input-plugins.html
1.2 标准输入(Stdin)
这种控制台输入前面已经介绍过了,这里就不解析了。
链接:ElasticSearch7.3学习(三十一)----Logstash基础学习
input{
stdin{
}
}
output {
stdout{
codec=>rubydebug
}
}
1.3 读取文件(File)
比如说我存在一个nginx1.log文件,文件内容如下:
注意:文件光标要指向下一行,不然最后一行可能读取不到

我想把文件内容打印至控制台显示。可在config/test1.conf里面添加如下内容,可采用通配符读取多个文件
input {
file {
path => ["E:/ElasticSearch/logstash-7.3.0/nginx*.log"]
start_position => "beginning"
}
}
output {
stdout {
codec=>rubydebug
}
}
具体的运行方式参照:ElasticSearch7.3学习(三十一)----Logstash基础学习
结果如下:
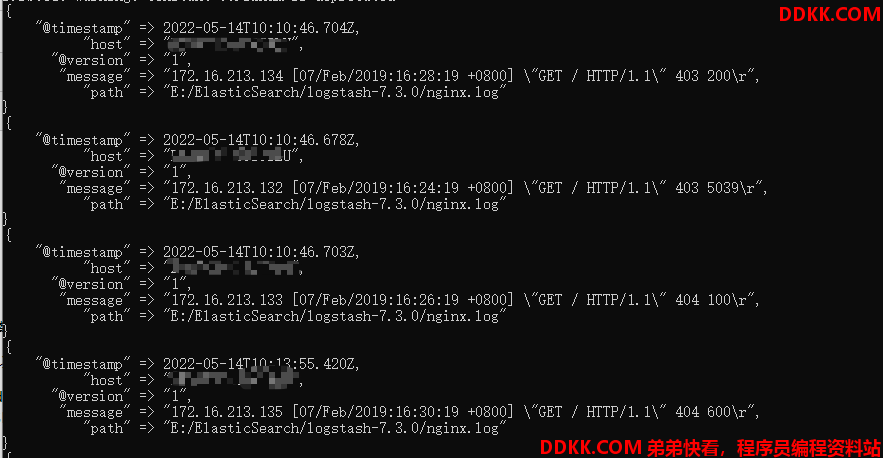
1.4 实时更新文件
假如说我们往nginx1.log下新增加一条数据,看下效果

在生产环境下,服务一直在运行,日志文件一直在增加,logstash会自动读取新增的数据
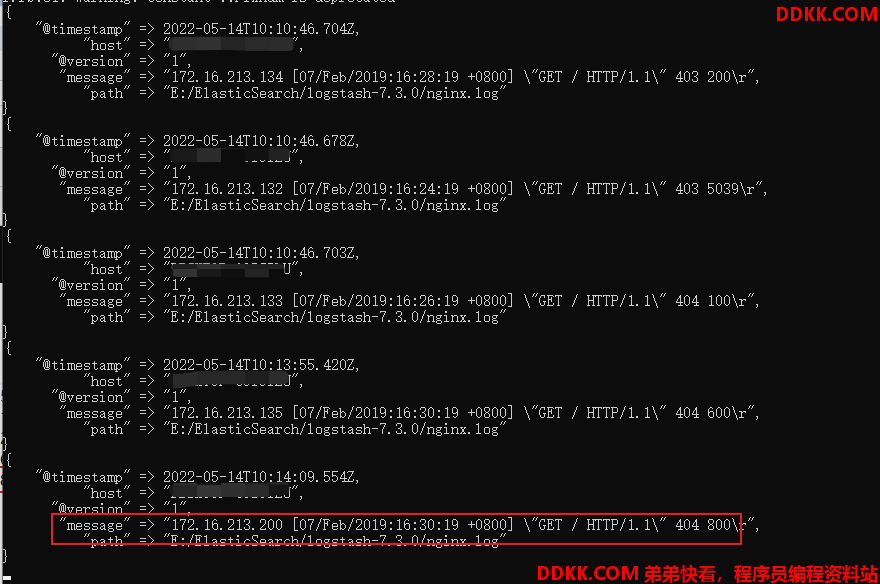
默认情况下,logstash会从文件的结束位置开始读取数据,也就是说logstash进程会以类似tail -f命令的形式逐行获取数据。
logstash使用一个名为filewatch的ruby gem库来监听文件变化,并通过一个叫.sincedb的数据库文件来记录被监听的日志文件的读取进度(时间戳),这个sincedb数据文件的默认路径在 <path.data>/plugins/inputs/file下面,文件名类似于.sincedb_123456,而<path.data>表示logstash插件存储目录,默认是LOGSTASH_HOME/data。
1.5 读取TCP网络数据
下面的内部表示监听端口的数据打印在控制台,用的比较少,这里就不演示了。
input {
tcp {
port => "1234"
}
}
filter {
grok {
match => { "message" => "%{SYSLOGLINE}" }
}
}
output {
stdout{
codec=>rubydebug
}
}
2、Logstash过滤器插件(Filter)
2.1 Filter介绍
Logstash 可以帮利用它自己的Filter帮我们对数据进行解析,丰富,转换等
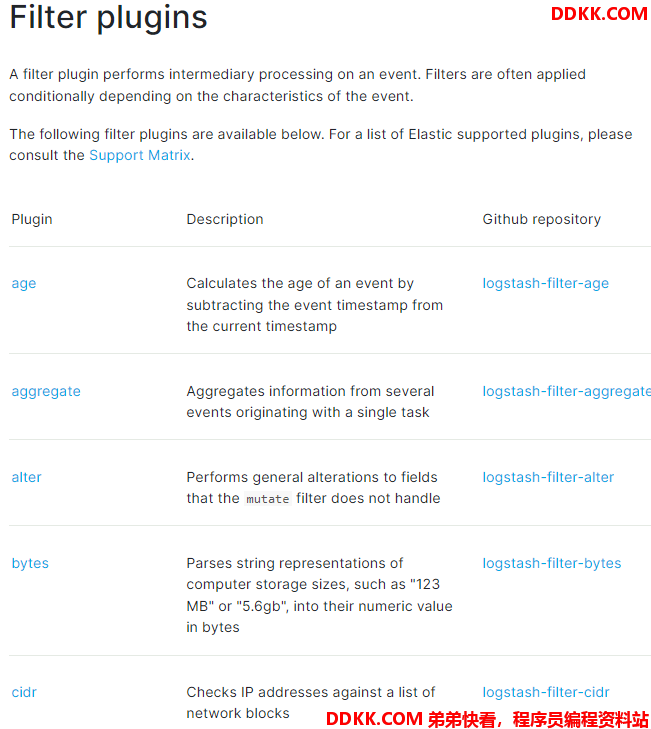
详情请见网址:https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
下面简单的介绍几个常用的。
2.2 Grok 正则捕获
grok是一个十分强大的logstash filter插件,他可以通过正则解析任意文本,将非结构化日志数据弄成结构化和方便查询的结构。他是目前logstash 中解析非结构化日志数据最好的方式。
Grok 的语法规则是:
%{语法: 语义}
例如输入的内容为:
172.16.213.132 [07/Feb/2019:16:24:19 +0800] "GET / HTTP/1.1" 403 5039
下面是一个组合匹配模式,它可以获取上面输入的所有内容:
%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}
- %{IP:clientip}匹配模式将获得的结果为:clientip: 172.16.213.132
- %{HTTPDATE:timestamp}匹配模式将获得的结果为:timestamp: 07/Feb/2018:16:24:19 +0800
- %{QS:referrer}匹配模式将获得的结果为:referrer: "GET / HTTP/1.1"
- %{NUMBER:response}匹配模式将获得的结果为:NUMBER: "403"
- %{NUMBER:bytes}匹配模式将获得的结果为:NUMBER: "5039"
通过上面这个组合匹配模式,我们将输入的内容分成了五个部分,即五个字段,将输入内容分割为不同的数据字段,这对于日后解析和查询日志数据非常有用,这正是使用grok的目的。
举个例子:可在config/test1.conf里面添加如下内容,用法同上
input{
stdin{}
}
filter{
grok{
match => ["message","%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}"]
}
}
output{
stdout{
codec => "rubydebug"
}
}
输入内容:
172.16.213.132 [07/Feb/2019:16:24:19 +0800] "GET / HTTP/1.1" 403 5039
结果如下:
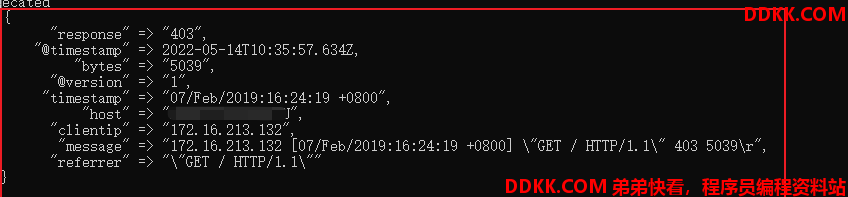
可以看到将一个长的字符串拆分为好几个字段,这样做的一个好处在于可以分割字符串,这样的话可直接输出至ElasticSearch。
2.3 时间处理(Date)
date插件是对于排序事件和回填旧数据尤其重要,它可以用来转换日志记录中的时间字段,变成LogStash::Timestamp对象,然后转存到@timestamp字段里,这在之前已经做过简单的介绍。 下面是date插件的一个配置示例:
可在config/test1.conf里面添加如下内容,用法同上
input{
stdin{}
}
filter {
grok {
match => ["message", "%{HTTPDATE:timestamp}"]
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
}
}
output{
stdout{
codec => "rubydebug"
}
}
输入内容:
172.16.213.132 [07/Feb/2019:16:24:19 +0800] "GET / HTTP/1.1" 403 5039
结果如下:

可以看到将时间戳格式转换为比较容易理解的格式。
2.4 数据修改(Mutate)
下面几个用法就不单独演示了,后面会有一个综合示例演示所有的用法。
1、 正则表达式替换匹配字段
gsub可以通过正则表达式替换字段中匹配到的值,只对字符串字段有效,下面是一个关于mutate插件中gsub的示例(仅列出filter部分):
filter {
mutate {
gsub => ["filed_name_1", "/" , "_"]
}
}
这个示例表示将filed_name_1字段中所有"/"字符替换为"_"。
2、 分隔符分割字符串为数组
split可以通过指定的分隔符分割字段中的字符串为数组,下面是一个关于mutate插件中split的示例(仅列出filter部分):
filter {
mutate {
split => ["filed_name_2", "|"]
}
}
这个示例表示将filed_name_2字段以"|"为区间分隔为数组。
3、 重命名字段
rename可以实现重命名某个字段的功能,下面是一个关于mutate插件中rename的示例(仅列出filter部分):
filter {
mutate {
rename => { "old_field" => "new_field" }
}
}
这个示例表示将字段old_field重命名为new_field。
4、 删除字段
remove_field可以实现删除某个字段的功能,下面是一个关于mutate插件中remove_field的示例(仅列出filter部分):
filter {
mutate {
remove_field => ["timestamp"]
}
}
这个示例表示将字段timestamp删除。
5、 GeoIP 地址查询归类
将ip转为地理信息
filter {
geoip {
source => "ip_field"
}
}
2.5 综合示例
下面给出一个综合示例,将上面介绍到的用法集成到一个filter中使用。
首先转换成多个字段 --> 去除message字段 --> 日期格式转换 --> 字段转换类型 --> 字段重命名 --> replace替换字段 --> split按分割符拆分数据成为数组
可在config/test1.conf里面添加如下内容,用法同上
input {
stdin {}
}
filter {
grok {
match => { "message" => "%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}" }
remove_field => [ "message" ]
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
}
mutate {
convert => [ "response","float" ]
rename => { "response" => "response_new" }
gsub => ["referrer","\"",""]
split => ["clientip", "."]
}
}
output {
stdout {
codec => "rubydebug"
}
输入内容:
172.16.213.132 [07/Feb/2019:16:24:19 +0800] "GET / HTTP/1.1" 403 5039
结果如下:
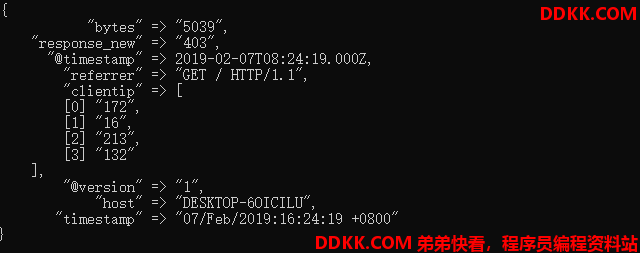
可以看到上述规则已成功输出。
3、Logstash输出插件(output)
output是Logstash的最后阶段,一个事件可以经过多个输出,而一旦所有输出处理完成,整个事件就执行完成。也就是说可以输出到多个数据终点。
一些常用的输出包括:
- file: 表示将日志数据写入磁盘上的文件。
- elasticsearch:表示将日志数据发送给Elasticsearch。Elasticsearch可以高效方便和易于查询的保存数据。
详细请见网址:https://www.elastic.co/guide/en/logstash/current/output-plugins.html
下面用法就不演示了,和上面大同小异。
3、 1输出到标准输出(stdout);
output {
stdout {
codec => rubydebug
}
}
3、 2保存为文件(file);
output {
file {
path => "/data/log/%{+yyyy-MM-dd}/%{host}_%{+HH}.log"
}
}
3、 输出到elasticsearch;
output {
elasticsearch {
host => ["192.168.1.1:9200","172.16.213.77:9200"]
index => "logstash-%{+YYYY.MM.dd}"
}
}
- host:是一个数组类型的值,后面跟的值是elasticsearch节点的地址与端口,默认端口是9200。可添加多个地址。
- index:写入elasticsearch的索引的名称,这里可以使用变量。Logstash提供了%{+YYYY.MM.dd}这种写法。在语法解析的时候,看到以+ 号开头的,就会自动认为后面是时间格式,尝试用时间格式来解析后续字符串。这种以天为单位分割的写法,可以很容易的删除老的数据或者搜索指定时间范围内的数据。此外,注意索引名中不能有大写字母。
- manage_template:用来设置是否开启logstash自动管理模板功能,如果设置为false将关闭自动管理模板功能。如果我们自定义了模板,那么应该设置为false。
- template_name:这个配置项用来设置在Elasticsearch中模板的名称。
4、综合案例
4.1 数据准备
下面这个案例将综合上面所有的内容
实现实时读取文件内容到本地的ElasticSearch
首先初始文件nginx1.log空文件内容如下:

将光标指向下一行。在config/test1.conf里面添加如下内容,用法同上
input {
file {
path => ["E:/ElasticSearch/logstash-7.3.0/nginx*.log"]
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}" }
remove_field => [ "message" ]
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
}
mutate {
rename => { "response" => "response_new" }
convert => [ "response","float" ]
gsub => ["referrer","\"",""]
remove_field => ["timestamp"]
split => ["clientip", "."]
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "logstash-%{+YYYY.MM.dd}"
}
}
4.2 运行结果
查看es中索引结果
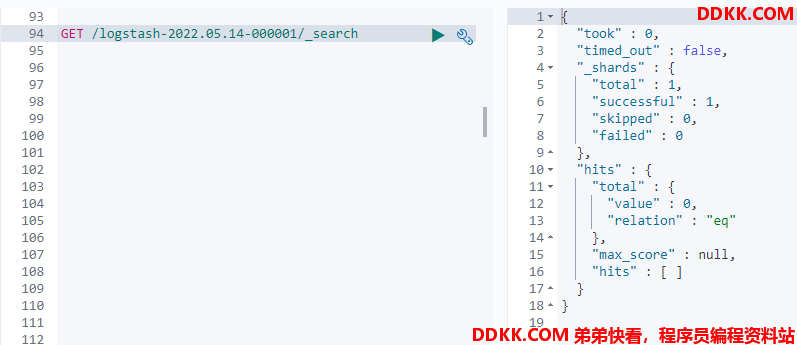
可以看到索引已成功建立
在往文件里添加内容
172.16.213.132 [07/Feb/2019:16:24:19 +0800] "GET / HTTP/1.1" 403 5039

结果如下:
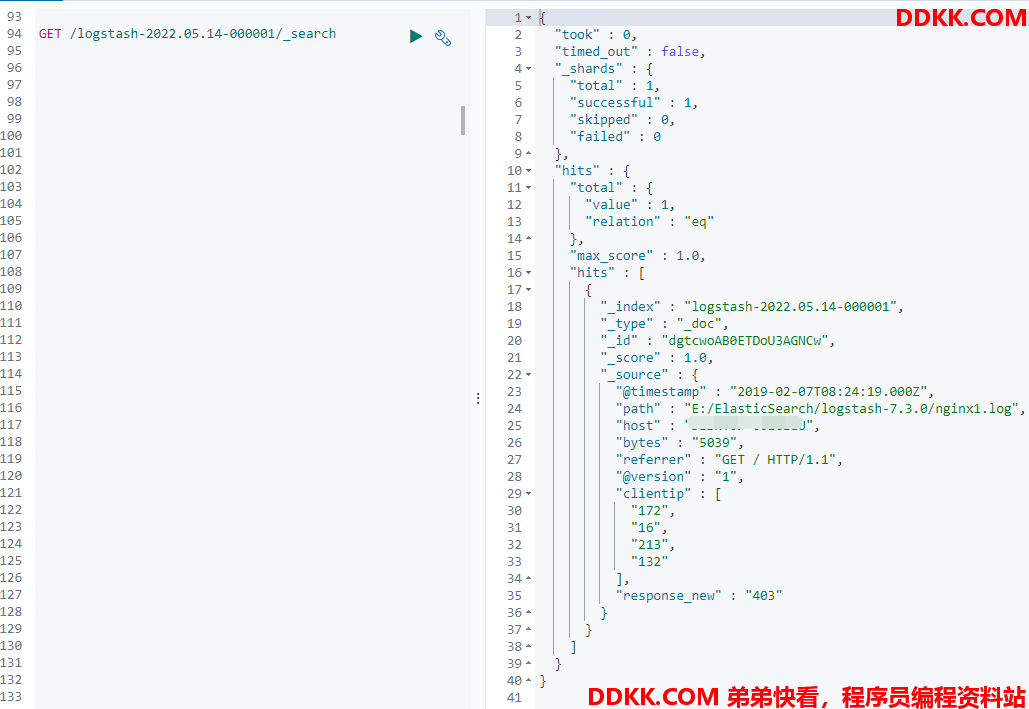
可以看到更新的数据已输出至ES,并且规则已成功体现在数据上面。