接第25节
3、使用
在上一小节中实现了创建索引,这一小节来试一下数据的检索功能。
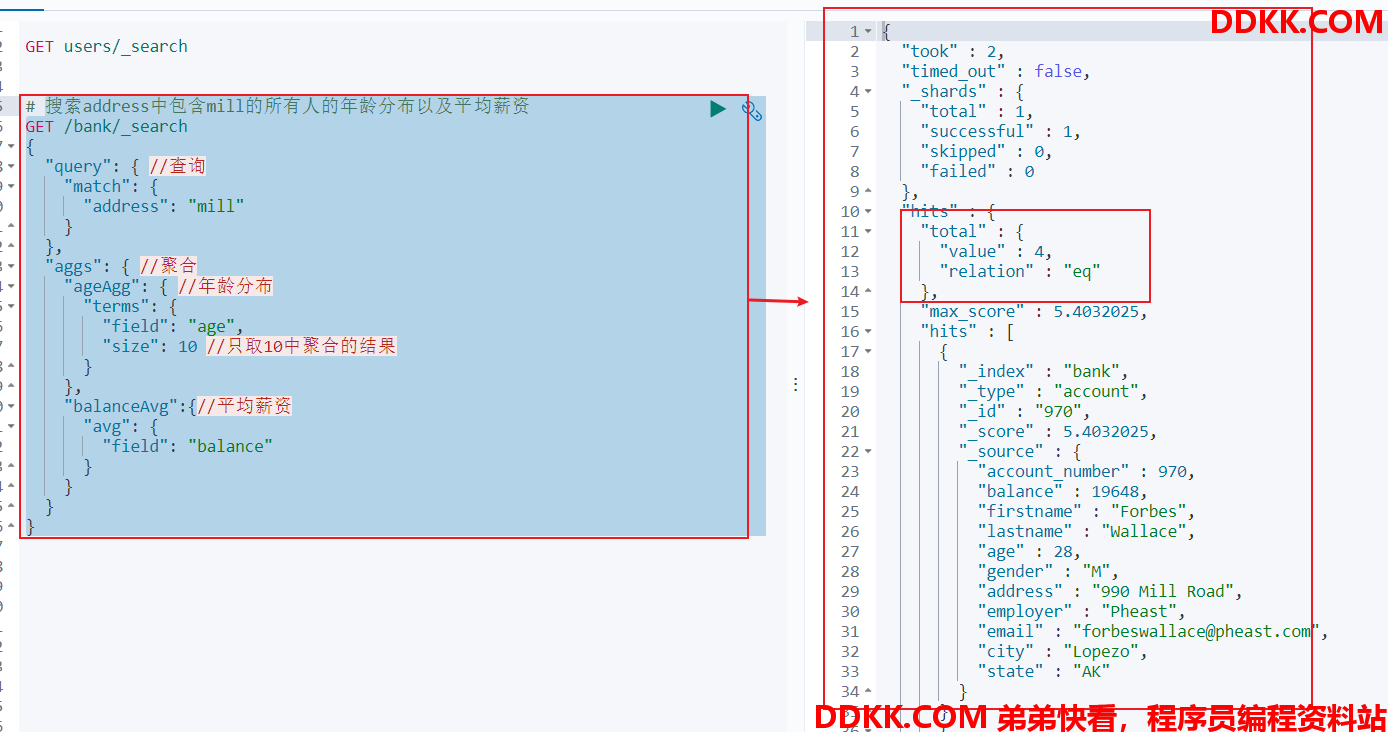
在代码中实现 搜索address中包含mill的所有人的年龄分布以及平均薪资 这个功能,如果是在 kibana 中,使用的是下面的DSL语句:
GET /bank/_search
{
"query": {
//查询
"match": {
"address": "mill"
}
},
"aggs": {
//聚合
"ageAgg": {
//年龄分布
"terms": {
"field": "age",
"size": 10 //只取10中聚合的结果
}
},
"balanceAvg":{
//平均薪资
"avg": {
"field": "balance"
}
}
}
}
结果如下图所示:
要在SpringBoot 集成环境中该如何实现呢?下面来使用代码实现上面的功能。
1)、测试类 PafcmallSearchApplicationTests.java 中添加测试方法searchData():
/**
* 检索数据
*
* @throws IOException
*/
@Test
void searchData() throws IOException {
// 1、创建检索请求
SearchRequest searchRequest = new SearchRequest();
// 指定索引
searchRequest.indices("bank");
// 指定DSL,检索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 1.1)、构造检索条件
// sourceBuilder.query(QueryBuilders.termQuery("user", "kimchy"));
// sourceBuilder.from(0);
// sourceBuilder.size(5);
// sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchSourceBuilder.query(QueryBuilders.matchQuery("address","mill"));
// 聚合数据
// 1.2)、根据年龄分布聚合
TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg").field("age").size(10);
searchSourceBuilder.aggregation(ageAgg);
// 1.3)、计算平薪资
AvgAggregationBuilder balanceAvg = AggregationBuilders.avg("balanceAvg").field("balance");
searchSourceBuilder.aggregation(balanceAvg);
System.out.println("检索条件:"+searchSourceBuilder.toString());
searchRequest.source(searchSourceBuilder);
// 2、执行检索
SearchResponse searchResponse = client.search(searchRequest, PafcmallElasticsearchConfig.COMMON_OPTIONS);
// 3、分析结果 searchResponse
System.out.println(searchResponse.toString());
//3.1)、获取所有查到的数据
SearchHits hits = searchResponse.getHits(); // 获取到最外围的 hits
SearchHit[] searchHits = hits.getHits(); // 内围的 hits 数组
for (SearchHit hit : searchHits) {
/**
* "_index":"bank",
* "_type":"account",
* "_id":"970",
* "_score":5.4032025,
* "_source":{
*/
// hit.getIndex();hit.getType()''
String str = hit.getSourceAsString();
Account account = JSON.parseObject(str, Account.class);
System.out.println(account.toString());
}
//3.1)、获取这次检索到的分析数据
Aggregations aggregations = searchResponse.getAggregations();
// 可以遍历获取聚合数据
// for (Aggregation aggregation : aggregations.asList()) {
// System.out.println("当前聚合:"+aggregation.getName());
// aggregation.getXxx
// }
// 也可使使用下面的方式
Terms ageAgg1 = aggregations.get("ageAgg");
for (Terms.Bucket bucket : ageAgg1.getBuckets()) {
String keyAsString = bucket.getKeyAsString();
System.out.println("年龄:"+keyAsString+" ==> 有 "+bucket.getDocCount()+" 个");
}
Avg balanceAvg1 = aggregations.get("balanceAvg");
System.out.println("平均薪资:"+balanceAvg);
}
2)、添加收集结果的测试类:
/**
* 测试用账号类
*/
@ToString
@Data
static class Account {
private int account_number;
private int balance;
private String firstname;
private String lastname;
private int age;
private String gender;
private String address;
private String employer;
private String email;
private String city;
private String state;
}
3)、执行测试方法,结果如下:
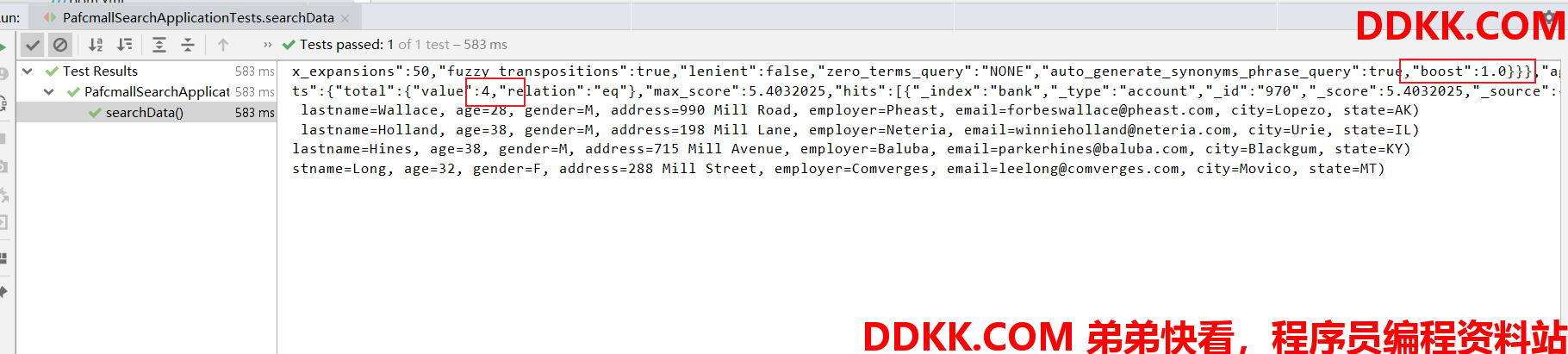

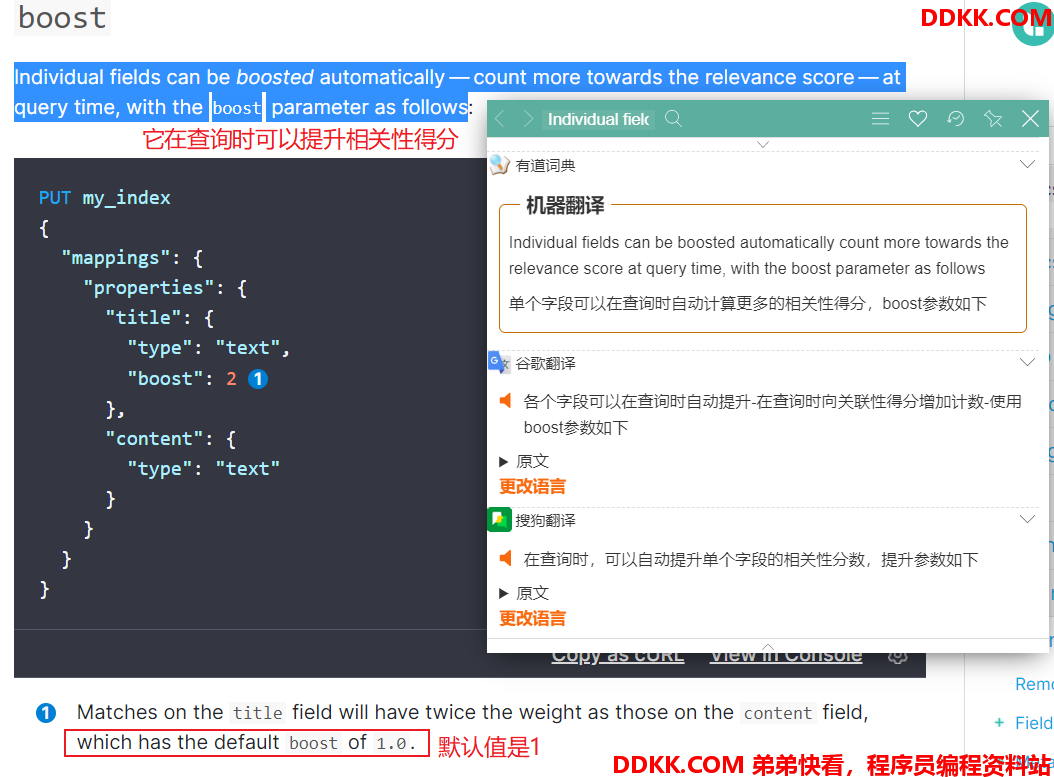
可以看到结果第一行中有一个 boost 参数,这个是系统自动为我们添加的,之前在 kibana 中使用 DSL 语言检索数据的时候是没有的。那么这个 boost 到底是什么呢?
参考官方文档,可以得出结论。
再来看查询结果,使用 json 工具格式化可以看到返回符合条件的数据有 4 条,和之前 kibana 中查出的一致:

以上,便是 SpringBoot 整合 ES 的全部内容,更多高级用法可以参考 ES 的官方文档进行尝试。
更多检索信息请参考 java-rest-high-search
总结
当然ES 的在实际的生产中应用广泛:
比如使用 ELK 组件用来进行日志的收集或者进行全文的检索:
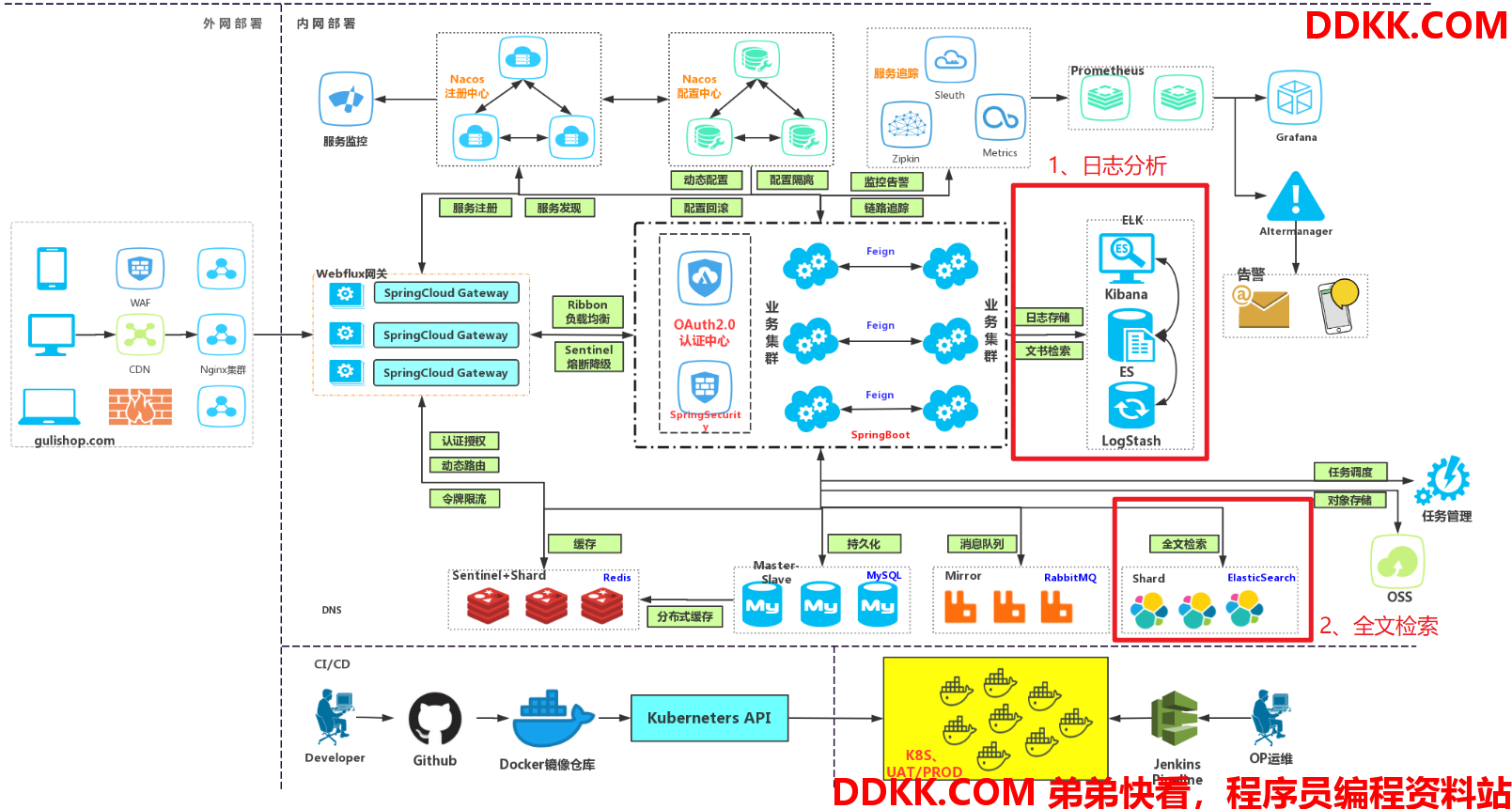
或者用来收集异常信息,做成可视化的界面来提供分析等:
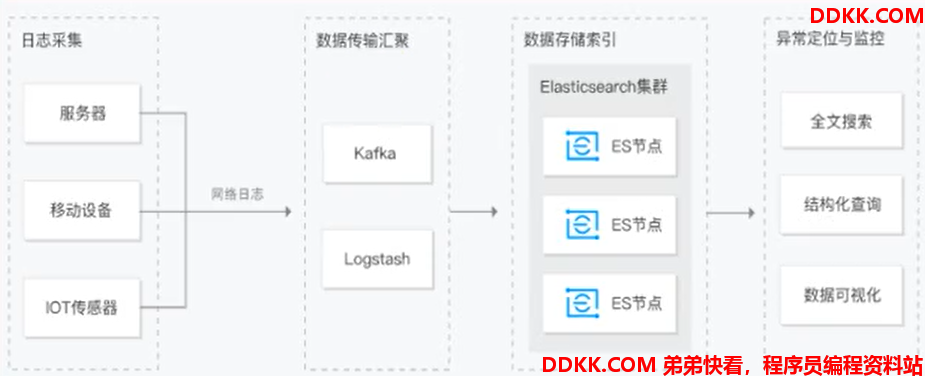
更多应用场景,还需要和实际的生产结合起来,也需要我们自己去尝试和探索。