上一节主要介绍了SolrCloud分布式索引的整体流程图以及索引链的实现,那么本节开始将分别介绍三个索引过程即LogUpdateProcessor,DistributedUpdateProcessor,DirectUpdateHandler2。本节主要研究下LogUpdateProcessor和DistributedUpdateProcessor。
1. LogUpdateProcessor
上一节中记述了LogUpdateProcessor的实例化,如下所示。从getInstance可以发现,LogUpdateProcessor在SolrCloud中并不一定会起作用,只有当Solr的日志等级为INFO的时候LogUpdateProcessor才会被实例化,否则就是Null,不会加入到索引链中。
@Override
public UpdateRequestProcessor getInstance(SolrQueryRequest req, SolrQueryResponse rsp, UpdateRequestProcessor next) {
return LogUpdateProcessor.log.isInfoEnabled() ? new LogUpdateProcessor(req, rsp, this, next) : null;
}
那么问题就来了,LogUpdateProcessor 这玩意到底是干什么的呢?看了下LogUpdateProcessor的源码就可以发现,原来这玩意就是一个记录Solr update过程日志的,所以当日志等级大于INFO时候,这个过程就是没有的。以processAdd()和finish()为例看下源码:
@Override
public void processAdd(AddUpdateCommand cmd) throws IOException {
if (logDebug) { log.debug("PRE_UPDATE " + cmd.toString() + " " + req); }
// call delegate first so we can log things like the version that get set later
if (next != null) next.processAdd(cmd);
// Add a list of added id's to the response
if (adds == null) {
adds = new ArrayList<>();
toLog.add("add",adds);
}
if (adds.size() < maxNumToLog) {
long version = cmd.getVersion();
String msg = cmd.getPrintableId();
if (version != 0) msg = msg + " (" + version + ')';
adds.add(msg);
}
numAdds++;
}
@Override
public void finish() throws IOException {
if (logDebug) { log.debug("PRE_UPDATE FINISH " + req); }
if (next != null) next.finish();
// LOG A SUMMARY WHEN ALL DONE (INFO LEVEL)
if (log.isInfoEnabled()) {
StringBuilder sb = new StringBuilder(rsp.getToLogAsString(req.getCore().getLogId()));
rsp.getToLog().clear(); // make it so SolrCore.exec won't log this again
// if id lists were truncated, show how many more there were
if (adds != null && numAdds > maxNumToLog) {
adds.add("... (" + numAdds + " adds)");
}
if (deletes != null && numDeletes > maxNumToLog) {
deletes.add("... (" + numDeletes + " deletes)");
}
long elapsed = rsp.getEndTime() - req.getStartTime();
sb.append(toLog).append(" 0 ").append(elapsed);
log.info(sb.toString());
}
}
之前我把这个LogUpdateProcessor的log的概念跟updatelog的概念搞混了,这里区分下:
- LogUpdateProcessor的log是程序运行的日志,即我们所说的一般的操作日志,带有INFO,WARN,ERROR等等级,当然他也会包含update的document信息,在log4j.property中设置。
- UpdateLog,下一节讲述DirectUpdateHandler2的时候会具体讲到,它是对一次request的内容的保存,是Solr内部进行数据备份、还原的文件,也包含了update的document,可再solrconfig.xml中进行配置文件路径。
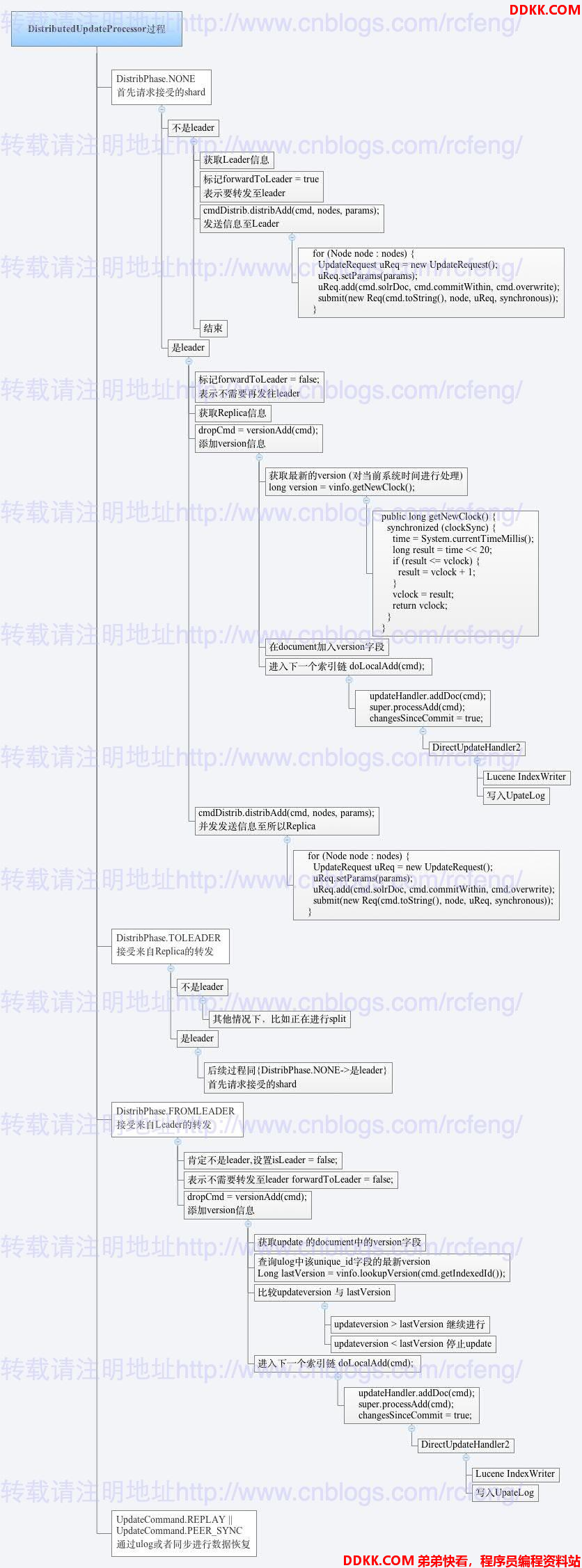
2. DistributedUpdateProcessor的整体流程图
这是我画的对 DistributedUpdateProcessor过程的示意图,以add过程为例主要介绍了DistributedUpdateProcessor的update 分发过程:
- document分发具有以下几种形态,DistribPhase.NONE , DistribPhase.TOLEADER , DistribPhase.FROMLEADER
public static enum DistribPhase {
NONE, TOLEADER, FROMLEADER;
public static DistribPhase parseParam(final String param) {
if (param == null || param.trim().isEmpty()) {
return NONE;
}
try {
return valueOf(param);
} catch (IllegalArgumentException e) {
throw new SolrException
(SolrException.ErrorCode.BAD_REQUEST, "Illegal value for " +
DISTRIB_UPDATE_PARAM + ": " + param, e);
}
}
}
-
除了以上几种情况,还需要考虑从ulog中恢复数据,这部分内容会在后文中单独写一节讲述SolrCloud的容灾恢复。
-
DistribPhase.NONE 表示SolrJ客户端直接往该Node种发送请求,而不是来自其他Node转发。分为两种情况
-
如果本Node是leader,
- 那么先设置标记forwardtoleader为false,表示不需要再往leader发了。
- 获取所有的Replica的Node信息
- 获取当前系统时间,并做移位操作,作为version的值。
- 在update request的document中加入_version_字段,value为version值
- 进入下一个索引链DirectUpdateHandler2,即在lucene Index中写入本次update的documents数据
- 将update request转发至各replica。
-
如果本Node不是leader,
- 首先获取leader信息
- 设置标记forwardtoleader为true,表示需要发往leader
- 将update request转发至leader。
-
DistribPhase.TOLEADER 表示request update请求是replica 发送给leader的,所有一般情况下,本Node就是leader。
-
如果本Node是leader,同DistribPhase.NONE 的leader的步骤一样
-
如果本Node不是leader,一般情况下是不会出现的,除非刚好在进行split或者在recovery,这部分将会在后面的容灾复原中介绍。
-
DistribPhase.FROMLEADER 表示request update请求是leader 发送给replica的,所有一般情况下,本Node就是replica。
-
设置isleader=false,表示不是leader
-
设置标记forwardtoleader为false,表示不需要再往leader发了
-
获取update 的document中的version字段,由leader加入version转发过来
-
查询ulog中该unique_id字段的最新version。
-
比较updateversion 与 lastVersion。如果updateversion > lastVersion 继续进行,如果updateversion < lastVersion 停止update。
-
进入下一个索引链DirectUpdateHandler2,即在lucene Index中写入本次update的documents数据
-
DistributedUpdateProcessor这一步主要实现了document的转发,以及version的生成与比较。而DirectUpdateHandler2才是真正的将request写入updatelog和Lucene Index过程,这在下一节中讲到。
-
本节主要将的是add过程,那么commit,delete过程跟add大同小异,这里就不再描述,下一节会顺带讲一下。
-
关于DistributedUpdateProcessor的processAdd()的源码因为篇幅原因就不再描述了。
@Override
public void processAdd(AddUpdateCommand cmd) throws IOException {
updateCommand = cmd;
//集群模式
if (zkEnabled) {
zkCheck();
//根据请求的DistribPhase获取将要转发的Node
nodes = setupRequest(cmd.getHashableId(), cmd.getSolrInputDocument());
} else {
//单机模式
isLeader = getNonZkLeaderAssumption(req);
}
boolean dropCmd = false;
if (!forwardToLeader) {
//对version信息进行处理,在request中加入version信息,并调用下一步索引链DirectUpdateHandler2。
dropCmd = versionAdd(cmd);
}
//如果update version 小于 lastversion,则放弃该次request
if (dropCmd) {
// TODO: do we need to add anything to the response?
return;
}
//根据DistribPhase 将数据转发至leader或者replica
if (zkEnabled && isLeader && !isSubShardLeader) {
DocCollection coll = zkController.getClusterState().getCollection(collection);
List<Node> subShardLeaders = getSubShardLeaders(coll, cloudDesc.getShardId(), cmd.getHashableId(), cmd.getSolrInputDocument());
// the list<node> will actually have only one element for an add request
if (subShardLeaders != null && !subShardLeaders.isEmpty()) {
ModifiableSolrParams params = new ModifiableSolrParams(filterParams(req.getParams()));
params.set(DISTRIB_UPDATE_PARAM, DistribPhase.FROMLEADER.toString());
params.set(DISTRIB_FROM, ZkCoreNodeProps.getCoreUrl(
zkController.getBaseUrl(), req.getCore().getName()));
params.set(DISTRIB_FROM_PARENT, req.getCore().getCoreDescriptor().getCloudDescriptor().getShardId());
for (Node subShardLeader : subShardLeaders) {
cmdDistrib.distribAdd(cmd, Collections.singletonList(subShardLeader), params, true);
}
}
List<Node> nodesByRoutingRules = getNodesByRoutingRules(zkController.getClusterState(), coll, cmd.getHashableId(), cmd.getSolrInputDocument());
if (nodesByRoutingRules != null && !nodesByRoutingRules.isEmpty()) {
ModifiableSolrParams params = new ModifiableSolrParams(filterParams(req.getParams()));
params.set(DISTRIB_UPDATE_PARAM, DistribPhase.FROMLEADER.toString());
params.set(DISTRIB_FROM, ZkCoreNodeProps.getCoreUrl(
zkController.getBaseUrl(), req.getCore().getName()));
params.set(DISTRIB_FROM_COLLECTION, req.getCore().getCoreDescriptor().getCloudDescriptor().getCollectionName());
params.set(DISTRIB_FROM_SHARD, req.getCore().getCoreDescriptor().getCloudDescriptor().getShardId());
for (Node nodesByRoutingRule : nodesByRoutingRules) {
cmdDistrib.distribAdd(cmd, Collections.singletonList(nodesByRoutingRule), params, true);
}
}
}
ModifiableSolrParams params = null;
if (nodes != null) {
params = new ModifiableSolrParams(filterParams(req.getParams()));
params.set(DISTRIB_UPDATE_PARAM,
(isLeader || isSubShardLeader ?
DistribPhase.FROMLEADER.toString() :
DistribPhase.TOLEADER.toString()));
params.set(DISTRIB_FROM, ZkCoreNodeProps.getCoreUrl(
zkController.getBaseUrl(), req.getCore().getName()));
cmdDistrib.distribAdd(cmd, nodes, params);
}
// TODO: what to do when no idField?
if (returnVersions && rsp != null && idField != null) {
if (addsResponse == null) {
addsResponse = new NamedList<String>();
rsp.add("adds",addsResponse);
}
if (scratch == null) scratch = new CharsRef();
idField.getType().indexedToReadable(cmd.getIndexedId(), scratch);
addsResponse.add(scratch.toString(), cmd.getVersion());
}
// TODO: keep track of errors? needs to be done at a higher level though since
// an id may fail before it gets to this processor.
// Given that, it may also make sense to move the version reporting out of this
// processor too.
}
3. 关于DistributedUpdateProcessor中Version bug的讨论
在查看DistributedUpdateProcessor中发现SolrCloud的version使用有bug,内容如下:
首先来查看VersionBucket这个类,这个类主要存放的是update的最高的version值。
// TODO: make inner?
// TODO: store the highest possible in the index on a commit (but how to not block adds?)
// TODO: could also store highest possible in the transaction log after a commit.
// Or on a new index, just scan "version" for the max?
/** @lucene.internal */
public class VersionBucket {
public long highest;
public void updateHighest(long val) {
if (highest != 0) {
highest = Math.max(highest, Math.abs(val));
}
}
}
当一个request发送过来时候,SolrCloud会根据request的document的个数新建VersionBucket数据,并初始化为0.
buckets = new VersionBucket[ BitUtil.nextHighestPowerOfTwo(nBuckets) ];
for (int i=0; i<buckets.length; i++) {
buckets[i] = new VersionBucket();
}
- 当进行update的时候,SolrCloud会根据每一个unique_id获取一个hash值,然后根据这个hash值在VersionBucket数组中寻找对应的VersionBucket的highest version
int bucketHash = Hash.murmurhash3_x86_32(idBytes.bytes, idBytes.offset, idBytes.length, 0);
VersionBucket bucket = vinfo.bucket(bucketHash);
long bucketVersion = bucket.highest;
那么问题来了,虽然VersionBucket的属性highest是public,但是SolrCloud从没有对highest进行赋值过。也就是说SolrCloud只会通过updateHighest这个方法取更新highest,但是由于highest的更新的前提是(highest != 0) ,那么highest就根本只会变成0,根本不会变成其他。所以这个version就成了摆设,根本没有起到任何作用,不知道是我理解的错误还是SolrCloud存在这样一个bug。
4. 总结
本节深入的研究了SolrCloud索引链三步走的前两步LogUpdateProcessor和DistributedUpdateProcessor。重点详细介绍了DistributedUpdateProcessor中对update request的分布情况,并对Version 比较的bug进行了说明。