本文是SolrCloud的Recovery策略系列的第三篇文章,前面两篇主要介绍了Recovery的总体流程,以及PeerSync策略。本文以及后续的文章将重点介绍Replication策略。Replication策略不但可以在SolrCloud中起到leader到replica的数据同步,也可以在用多个单独的Solr来实现主从同步。本文先介绍在SolrCloud的leader到replica的数据同步,下一篇文章将介绍通过配置SolrConfig.xml来实现多个Solr节点间的主从同步。
Replication策略介绍
Replication的作用在前文已经介绍过了,当需要同步的数据较多时候,Solr会放弃按document为单位的同步模式(PeerSync)而采用以文件为最小单位的同步模式。在Replication的过程中,重点使用了SnapPuller类,它封装了对leader数据快照以及通过快照来实现同步的代码。Replication流程原理如下图所示。接下来根据源码来介绍每一步骤。
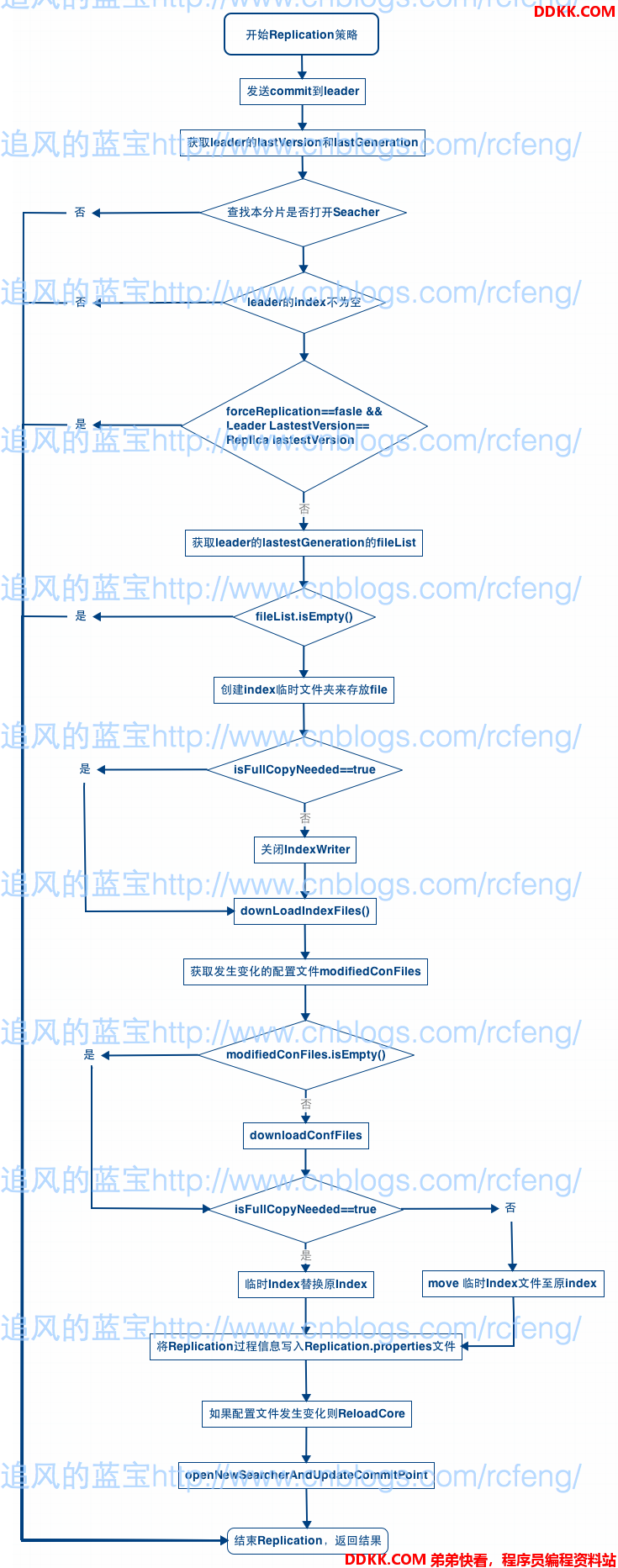
- 开始Replication的时候,首先进行一次commitOnLeader操作,即发送commit命令到leader。它的作用就是将leader的update中的数据刷入到索引文件中,使得快照snap完整。
private void commitOnLeader(String leaderUrl) throws SolrServerException,
IOException {
HttpSolrServer server = new HttpSolrServer(leaderUrl);
try {
server.setConnectionTimeout(30000);
UpdateRequest ureq = new UpdateRequest();
ureq.setParams(new ModifiableSolrParams());
ureq.getParams().set(DistributedUpdateProcessor.COMMIT_END_POINT, true);
ureq.getParams().set(UpdateParams.OPEN_SEARCHER, false);
ureq.setAction(AbstractUpdateRequest.ACTION.COMMIT, false, true).process(
server);
} finally {
server.shutdown();
}
}
- 获取leader的lastVersion与lastGeneration,同本分片的进行比较来确定是否需要进行同步。
//get the current 'replicateable' index version in the master
NamedList response = null;
try {
response = getLatestVersion();
} catch (Exception e) {
LOG.error("Master at: " + masterUrl + " is not available. Index fetch failed. Exception: " + e.getMessage());
return false;
}
long latestVersion = (Long) response.get(CMD_INDEX_VERSION);
long latestGeneration = (Long) response.get(GENERATION);
- 检查本分片是否打开IndexWriter,如果没有则Recovery失败。这是因为没有打开indexWriter就无法获取索引的generation以及version信息,replication无法进行下去。
// TODO: make sure that getLatestCommit only returns commit points for the main index (i.e. no side-car indexes)
IndexCommit commit = core.getDeletionPolicy().getLatestCommit();
if (commit == null) {
// Presumably the IndexWriter hasn't been opened yet, and hence the deletion policy hasn't been updated with commit points
RefCounted<SolrIndexSearcher> searcherRefCounted = null;
try {
searcherRefCounted = core.getNewestSearcher(false);
if (searcherRefCounted == null) {
LOG.warn("No open searcher found - fetch aborted");
return false;
}
commit = searcherRefCounted.get().getIndexReader().getIndexCommit();
} finally {
if (searcherRefCounted != null)
searcherRefCounted.decref();
}
}
- 如果获取的leader的lastestVersion为0,则表示leader没有索引数据,那么根本就不需要进行replication。所以返回true结果。
if (latestVersion == 0L) {
if (forceReplication && commit.getGeneration() != 0) {
// since we won't get the files for an empty index,
// we just clear ours and commit
RefCounted<IndexWriter> iw = core.getUpdateHandler().getSolrCoreState().getIndexWriter(core);
try {
iw.get().deleteAll();
} finally {
iw.decref();
}
SolrQueryRequest req = new LocalSolrQueryRequest(core,
new ModifiableSolrParams());
core.getUpdateHandler().commit(new CommitUpdateCommand(req, false));
}
//there is nothing to be replicated
successfulInstall = true;
return true;
}
- 我们还需要通过比较分片的lastestVersion和leader的lastestVersion来确定是否需要继续进行replication,因为两者相等同样没必要进行replication,除非进行的时forceReplication
if (!forceReplication && IndexDeletionPolicyWrapper.getCommitTimestamp(commit) == latestVersion) {
//master and slave are already in sync just return
LOG.info("Slave in sync with master.");
successfulInstall = true;
return true;
}
- 获取leader节点的lastestGeneration的索引文件列表以及相关文件信息,以及配置文件列表以及信息。如果文件列表为空,则退出replication。
// get the list of files first
fetchFileList(latestGeneration);
// this can happen if the commit point is deleted before we fetch the file list.
if(filesToDownload.isEmpty()) return false;
private void fetchFileList(long gen) throws IOException {
ModifiableSolrParams params = new ModifiableSolrParams();
params.set(COMMAND, CMD_GET_FILE_LIST);
params.set(GENERATION, String.valueOf(gen));
params.set(CommonParams.WT, "javabin");
params.set(CommonParams.QT, "/replication");
QueryRequest req = new QueryRequest(params);
HttpSolrServer server = new HttpSolrServer(masterUrl, myHttpClient); //XXX modify to use shardhandler
try {
server.setSoTimeout(60000);
server.setConnectionTimeout(15000);
NamedList response = server.request(req);
List<Map<String, Object>> files = (List<Map<String,Object>>) response.get(CMD_GET_FILE_LIST);
if (files != null)
filesToDownload = Collections.synchronizedList(files);
else {
filesToDownload = Collections.emptyList();
LOG.error("No files to download for index generation: "+ gen);
}
files = (List<Map<String,Object>>) response.get(CONF_FILES);
if (files != null)
confFilesToDownload = Collections.synchronizedList(files);
} catch (SolrServerException e) {
throw new IOException(e);
} finally {
server.shutdown();
}
}
- 建立临时的index目录来存放同步过来的数据,临时index目录的格式是index.timestamp。它存放在data目录下。
String tmpIdxDirName = "index." + new SimpleDateFormat(SnapShooter.DATE_FMT, Locale.ROOT).format(new Date());
tmpIndex = createTempindexDir(core, tmpIdxDirName);
tmpIndexDir = core.getDirectoryFactory().get(tmpIndex, DirContext.DEFAULT, core.getSolrConfig().indexConfig.lockType);
// cindex dir...
indexDirPath = core.getIndexDir();
indexDir = core.getDirectoryFactory().get(indexDirPath, DirContext.DEFAULT, core.getSolrConfig().indexConfig.lockType);
- 判断isFullCopyNeeded是否为true来决定是否需要关闭IndexWriter。如果本分片(slave)的数据的version或者generation新于master(leader)或者是forceReplication,那么必须进行所有数据的完整同步。
// if the generation of master is older than that of the slave , it means they are not compatible to be copied
// then a new index directory to be created and all the files need to be copied
boolean isFullCopyNeeded = IndexDeletionPolicyWrapper
.getCommitTimestamp(commit) >= latestVersion
|| commit.getGeneration() >= latestGeneration || forceReplication;
if (isIndexStale(indexDir)) {
isFullCopyNeeded = true;
}
if (!isFullCopyNeeded) {
// rollback - and do it before we download any files
// so we don't remove files we thought we didn't need
// to download later
solrCore.getUpdateHandler().getSolrCoreState()
.closeIndexWriter(core, true);
}
- 现在才开始真正的下载不同的索引文件,Replication是根据索引文件的大小来判断是否发生过变化.下载文件时候,Replication是以packet的大小为单位进行下载的,这可以在SolrConfig.xml中设置,下一篇文章将具体介绍这个。
private void downloadIndexFiles(boolean downloadCompleteIndex,
Directory indexDir, Directory tmpIndexDir, long latestGeneration)
throws Exception {
if (LOG.isDebugEnabled()) {
LOG.debug("Download files to dir: " + Arrays.asList(indexDir.listAll()));
}
for (Map<String,Object> file : filesToDownload) {
if (!slowFileExists(indexDir, (String) file.get(NAME))
|| downloadCompleteIndex) {
dirFileFetcher = new DirectoryFileFetcher(tmpIndexDir, file,
(String) file.get(NAME), false, latestGeneration);
currentFile = file;
dirFileFetcher.fetchFile();
filesDownloaded.add(new HashMap<>(file));
} else {
LOG.info("Skipping download for " + file.get(NAME)
+ " because it already exists");
}
}
}
/**
* The main method which downloads file
*/
void fetchFile() throws Exception {
try {
while (true) {
final FastInputStream is = getStream();
int result;
try {
//fetch packets one by one in a single request
result = fetchPackets(is);
if (result == 0 || result == NO_CONTENT) {
return;
}
//if there is an error continue. But continue from the point where it got broken
} finally {
IOUtils.closeQuietly(is);
}
}
} finally {
cleanup();
//if cleanup suceeds . The file is downloaded fully. do an fsync
fsyncService.submit(new Runnable(){
@Override
public void run() {
try {
copy2Dir.sync(Collections.singleton(saveAs));
} catch (IOException e) {
fsyncException = e;
}
}
});
}
}
- 到这里已经完成了索引文件的同步,但是整一个同步过程才进行了一半。接下来要获取已经发生过修改的配置文件,如果没有修改过的配置文件则不需要下载配置文件。而比较配置文件是否发生变化则是比较文件的checksum信息。下载配置文件的过程downloadConfFiles()与下载索引文件的过程类似,就不具体介绍了。
//get the details of the local conf files with the same alias/name
List<Map<String, Object>> localFilesInfo = replicationHandler.getConfFileInfoFromCache(names, confFileInfoCache);
//compare their size/checksum to see if
for (Map<String, Object> fileInfo : localFilesInfo) {
String name = (String) fileInfo.get(NAME);
Map<String, Object> m = nameVsFile.get(name);
if (m == null) continue; // the file is not even present locally (so must be downloaded)
if (m.get(CHECKSUM).equals(fileInfo.get(CHECKSUM))) {
nameVsFile.remove(name); //checksums are same so the file need not be downloaded
}
}
private void downloadConfFiles(List<Map<String, Object>> confFilesToDownload, long latestGeneration) throws Exception {
LOG.info("Starting download of configuration files from master: " + confFilesToDownload);
confFilesDownloaded = Collections.synchronizedList(new ArrayList<Map<String, Object>>());
File tmpconfDir = new File(solrCore.getResourceLoader().getConfigDir(), "conf." + getDateAsStr(new Date()));
try {
boolean status = tmpconfDir.mkdirs();
if (!status) {
throw new SolrException(SolrException.ErrorCode.SERVER_ERROR,
"Failed to create temporary config folder: " + tmpconfDir.getName());
}
for (Map<String, Object> file : confFilesToDownload) {
String saveAs = (String) (file.get(ALIAS) == null ? file.get(NAME) : file.get(ALIAS));
localFileFetcher = new LocalFsFileFetcher(tmpconfDir, file, saveAs, true, latestGeneration);
currentFile = file;
localFileFetcher.fetchFile();
confFilesDownloaded.add(new HashMap<>(file));
}
// this is called before copying the files to the original conf dir
// so that if there is an exception avoid corrupting the original files.
terminateAndWaitFsyncService();
copyTmpConfFiles2Conf(tmpconfDir);
} finally {
delTree(tmpconfDir);
}
}
- 下载完索引数据以及配置文件后,现在需要处理临时的索引数据了。不同于索引文件的下载,配置文件在下载的过程中就已经替换了原先的配置文件了,这是在copyTmpConfFiles2Conf过程中。而索引数据的替换则需要根据isFullCopyNeeded这个参数,如果该值为true,则临时的索引文件将全部替换旧的索引文件,否则只是部分的文件的替换,他们的实现分别为:modifyIndexProps和moveIndexFiles。
if (isFullCopyNeeded) {
successfulInstall = modifyIndexProps(tmpIdxDirName);
deleteTmpIdxDir = false;
} else {
successfulInstall = moveIndexFiles(tmpIndexDir, indexDir);
}
接下来要重点介绍下modifyIndexProps和moveIndexFiles的实现。前文讲到,同步索引文件时候,下载下来的数据会存放在data目录下,以index. 加上同步开始时间的时间戳结构的目录下。当下载数据完成后,Replication会在同级目录下新建index.property文件。该文件内只会放入一句内容,index= index.2014XXXXXXXXXX,这样做的目的就是将索引目录index重定向到index.2014XXXXXXXXXX上,这个时候相当于index.2014XXXXXXXXXX成为了index目录。然后就可以删除原来的index目录了。
而moveIndexFiles则比较简单,即将临时文件下的索引文件都拷贝到正在用的index目录上,其中segment_N文件最后复制。
- 将Replication的统计信息存于Replication.properties文件当中。统计信息较多,这里就不介绍了。
- 如果配置文件发生变化,需要进行reloadcore操作才能使得配置生效。
- 最后进行一次openNewSearcherAndUpdateCommitPoint,重新打开searcher以及更新commit信息。
Replication的一次同步过程就这么结束了,但是有个问题需要搞清楚,那就是在进行Replication的时候即shard的状态recoverying时候,分片是可以建索引的但是不能进行查询。在同步的时候,新进来的数据会进入到ulog中,但是这些数据是否会进入索引文件中?源码上我还没有发现可以证明新进来的数据的只会进入ulog中,但是不会进入索引文件。
目前我认为,当shard变为recoverying时候,新进来的请求只会进入ulog中,而不会进入索引文件中,原因有3:
1、 因为一旦有新数据写入旧索引文件中,索引文件发送变化了,那么下载好后的数据(索引文件)就不好替换旧的索引文件;
2、 在同步过程中,如果isFullCopyNeeded是false,那么就会closeindexwriter,既然关闭了indexwriter就无法写入新的数据而如果isFullCopyNeeded是true的话,因为整个index目录替换,所以是否关闭indexeriter也没啥意义;
3、 在recovery过程中,当同步replication结束后,会进行replay过程,该过程就是将ulog中的请求重新进行一遍;
以上是我目前的猜测,待我搞明白了再来修改这部分内容,或者是否有网友能指导下。
补上最近看的一些内容,主要是关于第二点的证明:在Replication的时候如果isFullCopyNeeded是false,那么在closeIndexWriter时候会对indexWriter进行回滚回到上次commit刚结束时候,即清空上次commit之后update操作。
if (indexWriter != null) {
if (!rollback) {
try {
log.info("Closing old IndexWriter... core=" + coreName);
indexWriter.close();
} catch (Exception e) {
SolrException.log(log, "Error closing old IndexWriter. core="
+ coreName, e);
}
} else {
try {
log.info("Rollback old IndexWriter... core=" + coreName);
indexWriter.rollback();
} catch (Exception e) {
SolrException.log(log, "Error rolling back old IndexWriter. core="
+ coreName, e);
}
}
}
而且在Replication结束的时候,Solr会重新打开IndexWriter,而重新打开IndexWriter任然会进行一次回滚,清除update记录。所以在一次Replication过程中update数据是无效的。
try {
if (indexWriter != null) {
if (!rollback) {
try {
log.info("Closing old IndexWriter... core=" + coreName);
indexWriter.close();
} catch (Exception e) {
SolrException.log(log, "Error closing old IndexWriter. core="
+ coreName, e);
}
} else {
try {
log.info("Rollback old IndexWriter... core=" + coreName);
indexWriter.rollback();
} catch (Exception e) {
SolrException.log(log, "Error rolling back old IndexWriter. core="
+ coreName, e);
}
}
}
indexWriter = createMainIndexWriter(core, "DirectUpdateHandler2");
log.info("New IndexWriter is ready to be used.");
// we need to null this so it picks up the new writer next get call
refCntWriter = null;
} finally {
pauseWriter = false;
writerPauseLock.notifyAll();
}
Replay过程
在整个recovery过程中,当replication结束后,会调用replay的来将ulog的请求重新刷入索引文件中。replay过程的本质是调用ulog的LogReplayer线程。
- LogReplayer是以transactionlog为单位的。
for(;;) {
TransactionLog translog = translogs.pollFirst();
if (translog == null) break;
doReplay(translog);
}
- doReplay会重新获取索引链,读取transctionlog的update命令然后重新走一遍索引链三步骤,这些内容在
<[Solr4.8.0源码分析(14)之SolrCloud索引深入(1)][Solr4.8.0_14_SolrCloud_1]>已经介绍过了,这里就不再介绍了。需要指出的是在进行doReplay时候会设置updatecmd为replay,而一旦cmd=UpdateCmd.Replay,因为无法获取到nodes所以不会分发给其他分片包括leader,所以doReplay只会对本分片有效,且不会记录ulog中。
tlogReader = translog.getReader(recoveryInfo.positionOfStart);
// NOTE: we don't currently handle a core reload during recovery. This would cause the core
// to change underneath us.
UpdateRequestProcessorChain processorChain = req.getCore().getUpdateProcessingChain(null);
UpdateRequestProcessor proc = processorChain.createProcessor(req, rsp);
if ((updateCommand.getFlags() & (UpdateCommand.REPLAY | UpdateCommand.PEER_SYNC)) != 0) {
isLeader = false; // we actually might be the leader, but we don't want leader-logic for these types of updates anyway.
forwardToLeader = false;
return nodes;
}
- LogReplayer主要用于applyBufferedUpdates(replication策略中)以及recoverFromLog(单机模式下的recovery,即从ulog进行recovery)。
总结:
本文主要介绍了SolrCloud中Replication的原理以及过程,同时简要讲述LogReplayer的doReplay线程对ulog的日志进行recovery。下文将要重点介绍主从模式下的Replication的配置以及使用。