最近在公司做SolrCloud的容灾测试,刚好碰到了一个比较蛋疼的问题,跟SolrCloud的Recovery和leader选举有关,正好拿出来分析下。
现象是这样的:比如我有一台3个shard的SolrCloud,每一个shard又有一个leader和replica。由于SolrCloud的leader选举策略,造成了IP1中同时出现了shard1和shard2的leader。
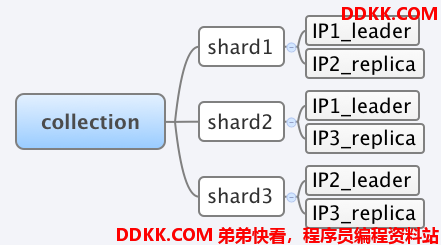
这个时候往collection update数据进去,以shard1为例,数据转发过程,IP1_leader –> IP2_replica。 在前文Recovery策略中介绍过,在这个数据转发过程中,如果IP1_leader没有收到IP2_replica的success反应,就会发送recovery命令到IP2_replica,使得IP2_replica触发recovery。那么现在我把IP2服务器关掉一会,此时数据仍然会往shard1打入,仍然会往IP1_leader update数据,但是不会往IP2_replica。过几分钟后,我重新启动IP2服务器,这个时候IP2_replica就会进行版本检查,发现跟IP1_leader commit版本不一致,随机就触发recovery。这个时候,我立马把IP1服务器关掉,即IP1_leader就是down了。此时SolrCloud会出现什么现象呢?由于IP2_replica正在进行recovery,它会从IP1_leader下载索引文件,这个时候IP1_leader处于down了,那么IP2_replica就无法获取需要recovery的索引文件了,因此在尝试多次recovery后,IP2_replica就会处于recovery_failed状态。又由于本来shard1的leader down了,会触发IP2_replica重新进行选举,但是由于IP2_replica处于recovery_failed状态而无法选举为leader,所以此时SolrCloud的shard1就会处于没有leader的,那么SolrCloud就会处于宕机状态。
private boolean shouldIBeLeader(ZkNodeProps leaderProps, SolrCore core, boolean weAreReplacement) {
log.info("Checking if I should try and be the leader.");
if (isClosed) {
log.info("Bailing on leader process because we have been closed");
return false;
}
if (!weAreReplacement) {
// we are the first node starting in the shard - there is a configurable wait
// to make sure others participate in sync and leader election, we can be leader
return true;
}
if (core.getCoreDescriptor().getCloudDescriptor().getLastPublished()
.equals(ZkStateReader.ACTIVE)) {
log.info("My last published State was Active, it's okay to be the leader.");
return true;
}
log.info("My last published State was "
+ core.getCoreDescriptor().getCloudDescriptor().getLastPublished()
+ ", I won't be the leader.");
// TODO: and if no one is a good candidate?
return false;
}
至于解决方法,目前没想到十分有效的,我能想得是两个:
1、 重启整个集群;
2、 源码上修改;
等有具体的有效的方法时候再写。