1、分库分表场景介绍
垂直分表-分字段:
将单表的字段分成多个表,每个表存储其中一部分字段。
优点:单一表数据量过大,区分大字段、热门字段、冷门字段,降低IO消耗,提高检索效率。
水平分表-多个相同表(拓展):
每个表所存在的字段信息一致,根据不同的规则将不同的数据分布到不同的表中。
优点:解决单一表数据量过大,而产生的性能问题。
当都是单表数据过大时,并且各字段都常用,相对推荐使用水平分表
垂直分库-按业务分表:
将不同业务类型的表,分到不同的数据库中。
优点:业务数据库数据量过大,降低业务表耦合,提高系统并发性能。
水平分库-多个相同库(拓展):
每个数据库的表结构一致,根据不同的规则将不同的数据分布到不同的库中。
优点:解决单库数据量过大,而产生的性能问题。
四种分片方式在实际开发中可以进行多种相应的组合,比如:
根据不同业务系统进行 垂直分库。
根据不同业务系统进行 垂直分库,当单库数据过大时,可以进行水平分库。
根据不同业务系统进行 垂直分库,当单表数据过大时,可以进行水平分表。
根据不同业务系统进行 垂直分库,当单库数据过大时,可以进行水平分库,分库中单表数据过大时,可以进行水平分表。
不进行任何分库,当单表数据过大时,可以进行水平分表。
2、分库分表带来问题
- 数据来自不同的数据库,产生分布式事务一致性。。
- 无法直接进行分库关联。
- 无法直接分页、排序、聚合计算,会每个分库/表都进行分页,然后再将结果进行分页最终返回。
- 需要使用分布式ID方案。
3、Sharding-JDBC介绍
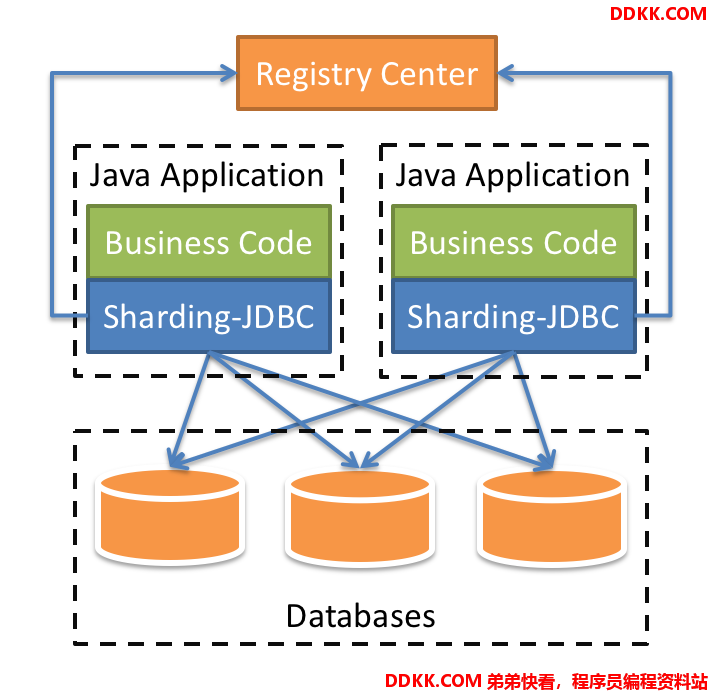
它定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
Sharding-JDBC的核心功能为数据分片和读写分离,通过Sharding-JDBC,应用可以透明的使用jdbc访问已经分库分表、读写分离的多个数据源,而不用关心数据源的数量以及数据如何分布,必须事先建立需要进行分库分表、读写分离的数据库。
使用Sharding-JDBC时,程序不需要指定具体的分库或者分表,而有Sharding-JDBC进行底层的操作。
支持范围广:
- 适用于任何基于Java的ORM框架,如: Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片。
分片算法
通过分片算法将数据分片,支持通过=、>=、<=、>、<、BETWEEN和IN分片。分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
行表达式语法说明
${begin..end}表示范围区间${[unit1, unit2, unit_x]}表示枚举值
${
['online', 'offline']}_table${
1..3}
// 最终会解析为:
online_table1, online_table2, online_table3, offline_table1, offline_table2, offline_table3
tb$->{
1..2}_table$->{
1..3}
// 最终会解析为:
tb1_table1,tb1_table2,tb1_table3,tb2_table1,tb2_table2,tb2_table3
// 通过取余的方式,设置分片的后缀,比如,分为:table_1/2/3
则表达式为:table_$->{
id % 3 +1}