1、SQL解析
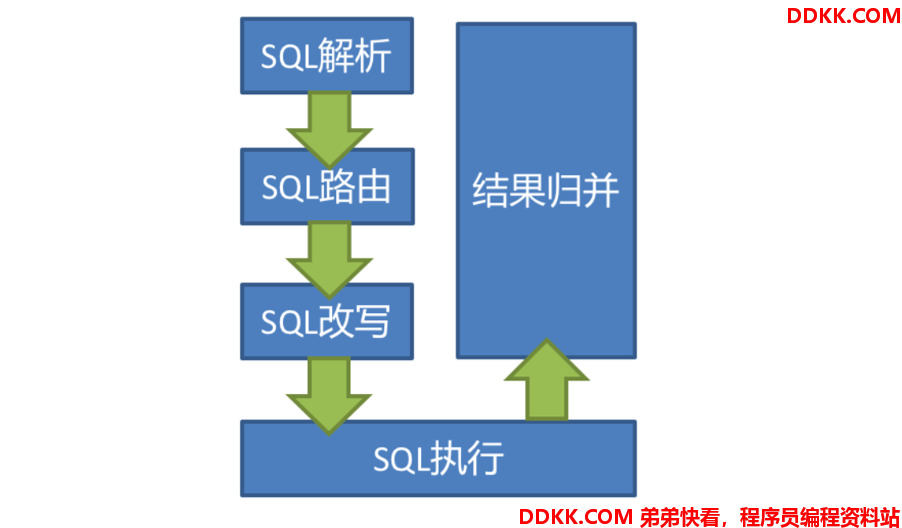
当Sharding-JDBC接受到一条SQL语句时,会陆续执行 SQL解析 => 查询优化 => SQL路由 => SQL改写 => SQL执行 =>结果归并,最终返回执行结果。
SQL解析过程分为词法解析和语法解析。 词法解析器用于将SQL拆解为不可再分的原子符号,称为Token。并根据不同数据库方言所提供的字典,将其归类为关键字,表达式,字面量和操作符。 再使用语法解析器将SQL转换为抽象语法树。例如:
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18
解析之后的为抽象语法树见下图:
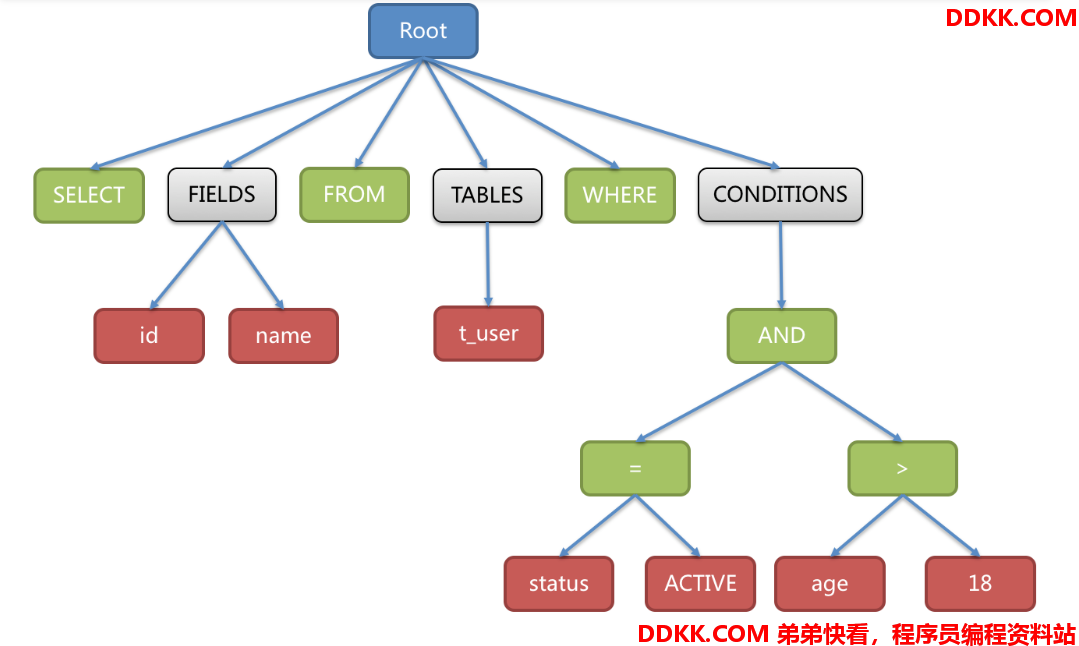
为了便于理解,抽象语法树中的关键字的Token用绿色表示,变量的Token用红色表示,灰色表示需要进一步拆分。
最后,通过对抽象语法树的遍历去提炼分片所需的上下文,并标记有可能需要SQL改写的位置。 供分片使用的解析上下文包含查询选择项(Select Items)、表信息(Table)、分片条件(Sharding Condition)、自增主键信息(Auto increment PrimaryKey)、排序信息(Order By)、分组信息(Group By)以及分页信息(Limit、Rownum、Top)。
2、SQL路由
SQL路由就是把针对逻辑表的数据操作映射到对数据结点操作的过程。
根据解析上下文匹配数据库和表的分片策略,并生成路由路径。 对于携带分片键的SQL,根据分片键操作符不同可以划分为单片路由(分片键的操作符是等号)、多片路由(分片键的操作符是IN)和范围路由(分片键的操作符是BETWEEN),不携带分片键的SQL则采用广播路由。根据分片键进行路由的场景可分为直接路由、标准路由、笛卡尔路由等。
标准路由
标准路由是Sharding-Jdbc最为推荐使用的分片方式,它的适用范围是不包含关联查询或仅包含绑定表之间关联查询的SQL。 当分片运算符是等于号时,路由结果将落入单库(表),当分片运算符是BETWEEN或IN时,则路由结果不一定落入唯一的库(表),因此一条逻辑SQL最终可能被拆分为多条用于执行的真实SQL。
笛卡尔路由
笛卡尔路由是最复杂的情况,它无法根据绑定表的关系定位分片规则,因此非绑定表之间的关联查询需要拆解为笛卡尔积组合执行,比如user_0/1,与account_0/1进行关联时,可能每个事实表之间均会进行关联查询(产生四条SQL)。
3、SQL改写
程序面向逻辑表书写的SQL,并不能够直接在真实的数据库中执行,SQL改写用于将逻辑SQL改写为在真实数据库中可以正确执行的SQL。
如果用于order by 或者group by的字段,不是用于返回的字段,则sharding-jdbc会在返回的字段中加上用于order by 或者group by的字段,比如:
<!--逻辑表SQL-->
SELECT order_id FROM t_order ORDER BY user_id;
<!--SQL改写-->
SELECT order_id, user_id AS ORDER_BY_DERIVED_0 FROM t_order ORDER BY user_id;
4、SQL执行
Sharding-JDBC采用一套自动化的执行引擎,负责将路由和改写完成之后的真实SQL安全且高效发送到底层数据源执行。 它不是简单地将SQL通过JDBC直接发送至数据源执行;也并非直接将执行请求放入线程池去并发执行。它更关注平衡数据源连接创建以及内存占用所产生的消耗,以及最大限度地合理利用并发等问题。 执行引擎的目标是自动化的平衡资源控制与执行效率,他能在以下两种模式自适应切换:内存限制模式、连接限制模式
内存限制模式
Sharding-JDBC对一次操作所耗费的数据库连接数量不做限制。 如果实际执行的SQL需要对某数据库实例中的200张表做操作,则对每张表创建一个新的数据库连接,并通过多线程的方式并发处理,以达成执行效率最大化。
连接限制模式
Sharding-JDBC严格控制对一次操作所耗费的数据库连接数量。 如果实际执行的SQL需要对某数据库实例中的200张表做操作,那么只会创建唯一的数据库连接,并对其200张表串行处理。 如果一次操作中的分片散落在不同的数据库,仍然采用多线程处理对不同库的操作,但每个库的每次操作仍然只创建一个唯一的数据库连接。
5、结果归并
将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端,称为结果归并。Sharding-JDBC支持的结果归并从功能上可分为遍历、排序、分组、分页和聚合5种类型,它们是组合而非互斥的关系。
归并引擎的整体结构划分如下图:
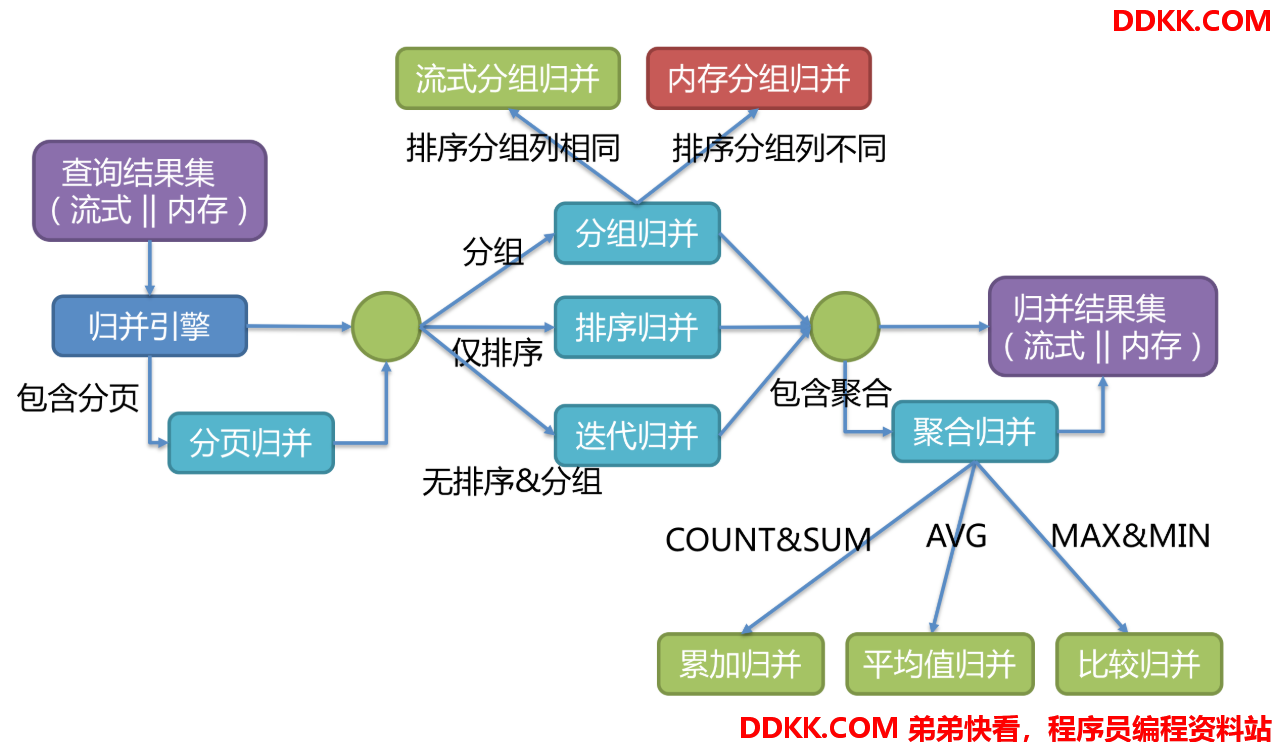
结果归并从结构划分可分为流式归并、内存归并、装饰者归并。流式归并和内存归并是互斥的,装饰者归并可以在流式归并和内存归并之上做进一步的处理。
内存归并很容易理解,他是将所有分片结果集的数据都遍历并存储在内存中,再通过统一的分组、排序以及聚合等计算之后,再将其封装成为逐条访问的数据结果集返回。
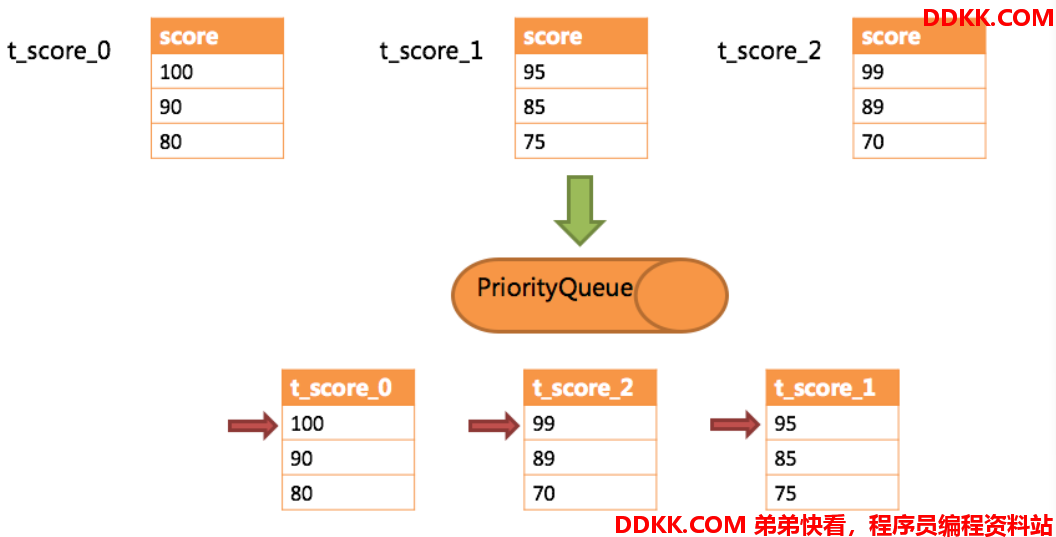
流式归并是指每一次从数据库结果集中获取到的数据,都能够通过游标逐条获取的方式返回正确的单条数据,它与数据库原生的返回结果集的方式最为契合。比如下图所示:
装饰者归并是对所有的结果集归并进行统一的功能增强,比如归并时需要聚合SUM前,在进行聚合计算前,都会通过内存归并或流式归并查询出结果集。因此,聚合归并是在之前介绍的归并类型之上追加的归并能力,即装饰者模式。