jmeter作为一个开源的性能测试工具,作用还是蛮强大的,找到一篇对jmeter中函数助手解释蛮详细的一篇博客,感觉不错,转载过来,希望对大家有所帮助。
由于时间和版本问题,其中有些内容和排版我做了修改和重新整理,使其更符合最新的jmeter版本。
一、使用jmeter函数助手
启动jmeter后,可以在JMeter的选项菜单中找到函数助手对话框(快捷键:Ctrl+Shift+F1),如下图所示:
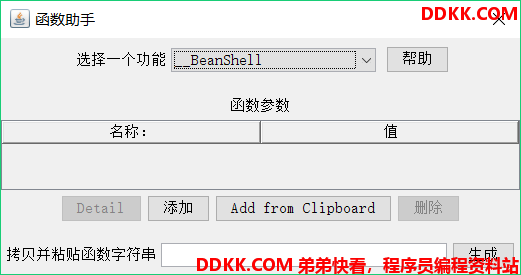
打开函数助手,可以从下拉列表中选择一个函数,并为其参数设定值,不同函数要求的参数也不同;表格的左边一列是函数参数的简要描述,右边一列是供用户填充参数的值。
二、常用JMeter函数
1、__regexFunction
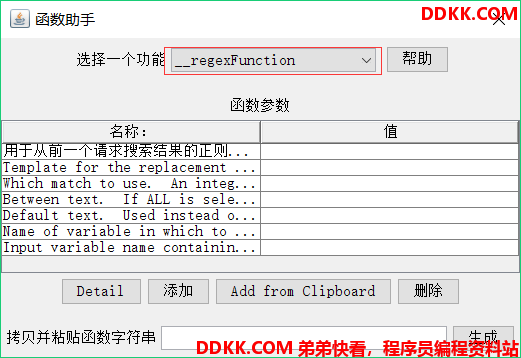
正则表达式函数可以使用正则表达式(用户提供的)来解析前面的服务器响应(或者是某个变量值),函数会返回一个有模板的字符串,其中携带有可变的值。
__regexFunction还可以被用来保存值,以便供后续使用。
在函数的第6个参数中,可以指定一个引用名;在函数执行以后,可以使用用户定义值的语法来获取同样的值。例如,如果输入"refName"作为第6个参数,那么可以使用:
${refName}来引用第2个参数(Template for the replacement string)的计算结果,这依赖于函数的解析结果;
${refName_g0}来引用函数解析后发现的所有匹配结果;
${refName_g1}来引用函数解析后发现的第一个匹配组合;
${refName_g#}来引用函数解析后发现的第n个匹配组合;
${refName_matchNr}来引用函数总共发现的匹配组合数目;
参数如下表所示:
函数参数 |
描述 |
是否必需 |
第1个参数 |
第1个参数是用于解析服务器响应数据的正则表达式,它会找到所有匹配项;如果希望将表达式中的 某部分应用在模板字符串中,一定记得为其加上圆括号。例如,<a href="(.*)">,这样就会将链 接的值存放到第一个匹配组合中(这里只有一个匹配组合)。又如,<input type="hidden" name="(.*)"value="(.*)">,在这个例子中,链接的name作为第一个匹配组合,链接的value会 作为第二个匹配组合,这些组合可以用在测试人员的模板字符串中。 |
是 |
第2个参数 |
这是一个模板字符串,函数会动态填写字符串的部分内容。要在字符串中引用正则表达式捕获的匹配组 合,请使用语法:[groupnumber][groupnumber]。例如11或者 22,模板可以是任何字符串。 |
是 |
第3个参数 |
第3个参数告诉JMeter使用第几次匹配;测试人员的正则表达式可能会找到多个匹配项,对此, 有4种选择: n 整数,直接告诉JMeter使用第几个匹配项; n “1”对应第一个匹配,“2”对应第二个匹配,以此类推; n RAND,告诉JMeter随机选择一个匹配项; n ALL,告诉JMeter使用所有匹配项,为每个匹配项创建一个模板字符串,并将它们连接在一起 n 浮点值0到1之间,根据公式(找到的总匹配数目*指定浮点值)计算使用第几个匹配项,计算值 向最近的整数取整 |
否,默认值为1 |
第4个参数 |
如果在上一个参数中选择了“ALL”,那么这第4个参数会被插入到重复的模板值之间 |
否 |
第5个参数 |
如果没有找到匹配项返回的默认值 |
否 |
第6个参数 |
重用函数解析值的引用名,参见上面内容 |
否 |
第7个参数 |
输入变量名称。如果指定了这一参数,那么该变量的值就会作为函数的输入,而不再使用前面的采样结 果作为搜索对象 |
否 |
2、__counter
每次调用计数器函数都会产生一个新值,从1开始每次加1。计数器既可以被配置成针对每个虚拟用户是独立的,也可以被配置成所有虚拟用户公用的。如果每个虚拟用户的计数器
是独立增长的,那么通常被用于记录测试计划运行了多少遍。全局计数器通常被用于记录发送了多少次请求,计数器使用一个整数值来记录,允许的最大值为2,147,483,647。
目前计数器函数实例是独立实现的(JMeter 2.1.1及其以前版本,使用一个固定的线程变量来跟踪每个用户的计数器,因此多个计数器函数会操作同一个值)。
全局计数器(FALSE)每个计数器实例都是独立维护的。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
第1个参数 |
True,如果希望每个虚拟用户的计数器保持独立,与其他用户的计数器相区别; false,全局计数器; |
是 |
第2个参数 |
重用计数器函数创建值的引用名。可以这样引用计数器的值:${refName}。这样一来,就可以创建一个 计数器后,在多个地方引用它的值(JMeter 2.1.1及其以前版本,这个参数是必需的) |
否 |
3、__threadNum
函数__threadNum只是简单地返回当前线程的编号。线程编号不依赖于线程组,这就意味着从函数的角度看来,某个线程组的线程#1和另一个线程组的线程#1是没有区别的。
另外,该函数没有参数。这一函数不能用在任何配置元件中(如用户定义的变量),原因在于配置元件是由一个独立线程运行的。另外在测试计划中使用也是没有意义的。
4)__intSum
函数__intSum可以被用来计算两个或者更多整数值的合。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
第1个参数 |
第1个整数值 |
是 |
第2个参数 |
第2个整数值 |
是 |
第n个参数 |
第n个整数值 |
否 |
最后一个参数 |
重用函数计算值的引用名。如果用户指定了这一参数,那么引用名中必须包含一个非数字字母,否则它会被当成另 一个整数值,而被函数用于计算 |
否 |
JMeter 2.3.1及其以前版本,要求必须有引用名参数。后续JMeter版本中,引用名是可选的参数,但是引用名不能是整数值。
5、__longSum
函数__ longSum可以被用来计算两个或者更多长整型值的合。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
第1个参数 |
第1个长整型值 |
是 |
第2个参数 |
第2个长整型值 |
是 |
第n个参数 |
第n个长整型值 |
否 |
最后一个参数 |
重用函数计算值的引用名。如果用户指定了这一参数,那么引用名中必须包含一个非数字字母,否则它会被当成 另一个长整型值,而被函数用于计算 |
否 |
6、__StringFromFile
__StringFromFile可以被用来从文本文件中读取字符串,这对需要大量可变数据的测试很有用。例如,当测试一个银行系统时,测试人员可能需要100条甚至1000条账户信息。
使用配置元件CSV Data Set Config ,也能达到相同的目的,而且方法更简单,但是该配置元件目前不支持多输入文件。
每次调用函数,都会从文件中读取下一行。当到达文件末尾时,函数又会从文件开始处重新读取,直到最大循环次数。如果在一个测试脚本中对该函数有多次引用,那么每一次引用
都会独立打开文件,即使文件名是相同的(如果函数读取的值,在脚本其他地方也有使用,那么就需要为每一次函数调用指定不同的变量名)。
如果在打开或者读取文件时发生错误,那么函数就会返回字符串"**ERR**"。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
文件名 |
文件名(可以使用相对于JMeter启动目录的相对路径)。如果要在文件名中使用可选的序列号,那么文件名 必须适合转成十进制格式。参考下面的例子 |
是 |
变量名 |
一个引用名(refName)的目的是复用这一函数创建的值。可以使用语法${refName}来引用函数创建的 值。默认值为“StringFromFile_” |
否 |
初始序列号 |
初始序列号(如果省略这一参数,终止序列号会作为一个循环计数器) |
否 |
终止序列号 |
终止序列号(如果省略这一参数,序列号会一直增加下去,不会受到限制) |
否 |
当打开或者重新打开文件时,文件名参数将会被解析;每次执行函数时,引用名参数(如果支持)将会被解析。
使用序列号:当使用可选的序列号时,文件名需要使用格式字符串Java.text.DecimalFormat;当前的序列号会作为唯一的参数,如果不指明可选的初始序列号,
就使用文件名作为起始值。一些有用的格式序列如下:
#:插入数字,不从零开始,不包含空格。
000:插入数字,包含3个数字组合,不从零开始。
例如:
①pin#'.'dat -> pin1.dat, ... pin9.dat, pin10.dat, ... pin9999.dat
②pin000'.'dat -> pin001.dat ... pin099.dat ... pin999.dat ... pin9999.dat
③pin'.'dat# -> pin.dat1, ... pin.dat9 ... pin.dat999
如果不希望某个格式字符被翻译,测试人员需要为它加上单引号;注意"."是格式字符,必须被单引号所包含。
如果省略了初始序列号,而终止序列号参数将会作为循环计数器,文件将会被使用指定的次数。例如:
${_StringFromFile(PIN#'.'DAT,,1,2)}:读取 PIN1.DAT, PIN2.DAT。
${_StringFromFile(PIN.DAT,,,2)}:读取 PIN.DAT 两次。
7、__machineName
函数__machineName返回本机的主机名。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
变量名 |
重用函数计算值的引用名 |
否 |
8、__javaScript
函数__javaScript可以用来执行JavaScript代码片段(非Java),并返回结果值。JMeter的_javaScript函数会调用标准的JavaScript解释器;
JavaScript会作为脚本语言使用,因此测试人员可以做相应的计算;在脚本中可以访问如下一些变量:
Log:该函数的日志记录器;
Ctx:JmeterContext对象;
Vars:JmeterVariables对象;
threadName:字符串包含当前线程名称 (在2.3.2 版本中它被误写为"theadName");
sampler:当前采样器对象(如果存在);
sampleResult:前面的采样结果对象(如果存在);
props:JMeter属性对象;
Rhinoscript允许通过它的包对象来访问静态方法;例如,用户可以使用如下方法访问JMeterContextService静态方法:
Packages.org.apache.jmeter.threads.JMeterContextService.getTotalThreads()
JMeter不是一款浏览器,它不会执行从页面下载的JavaScript;
参数如下表所示:
函数参数 |
描述 |
是否必需 |
JavaScript代码片段 |
待执行的JavaScript代码片段;例如: n new Date():返回当前日期和时间 n Math.floor(Math.random()*(${maxRandom}+1)):在0和变量maxRandom之间的随机数 n ${minRandom}+Math.floor(Math.random()*(maxRandom−maxRandom−{minRandom}+1)): n 在变量 minRandom和maxRandom之间的随机数 n "${VAR}"=="abcd" |
是 |
变量名 |
重用函数计算值的引用名 |
否 |
请记得为文本字符串添加必要的引号。另外,如果表达式中有逗号,请确保对其转义。例如,{__javaScript('{__javaScript('{sp}'.slice(7\,99999))},对7之后的逗号进行了转义。
9、__Random
函数__Random会返回指定最大值和最小值之间的随机数。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
最小值 |
最小数值 |
是 |
最大值 |
最大数值 |
是 |
变量名 |
重用函数计算值的引用名 |
否 |
10、__CSVRead
函数__CSVRead会从CSV文件读取一个字符串(请注意与StringFromFile 的区别)。
JMeter 1.9.1以前的版本仅支持从单个文件中读取,JMeter 1.9.1及其以后版本支持从多个文件中读取。在大多数情况下,新配置元件CSV Data Set更好用一些。
当对某文件进行第一次读取时,文件将被打开并读取到一个内部数组中;如果在读取过程中找到了空行,函数就认为到达文件末尾了,即允许拖尾注释(JMeter 1.9.1版本引入);
后续所有对同一个文件名的引用,都使用相同的内部数组。另外,文件名大小写对函数调用很重要,哪怕操作系统不区分大小写,CSVRead(abc.txt,0)和CSVRead(aBc.txt,0)
会引用不同的内部数组;使用*ALIAS特性可以多次打开同一个文件,另外还能缩减文件名称。
每一个线程都有独立的内部指针指向文件数组中的当前行;当某个线程第一次引用文件时,函数会为线程在数组中分配下一个空闲行。如此一来,任何一个线程访问的文件行,
都与其他线程不同(除非线程数大于数组包含的行数)。
默认下,函数会在遇到每一个逗号处断行;如果希望在输入列中使用逗号,那么需要换一个分隔符(设置属性csvread.delimiter实现),且该符号没有在CSV文件任何列中出现。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
文件名 |
设置从哪个文件读取(或者*ALIAS) |
是 |
列数 |
从文件的哪一列读取。0=第一列, 1=第二列,依此类推。“next”为走到文件的下一行。*ALIAS为打开 一个文件,并给它分配一个别名 |
是 |
例如,可以用如下参数来设置某些变量:
①COL1a ${__CSVRead(random.txt,0)}
②COL2a {__CSVRead(random.txt,1)}{__CSVRead(random.txt,1)}{__CSVRead(random.txt,next)}
③COL1b ${__CSVRead(random.txt,0)}
④COL2b {__CSVRead(random.txt,1)}{__CSVRead(random.txt,1)}{__CSVRead(random.txt,next)}
上面例子会从一行中读取两列,接着从下一行中读取两列。如果所有变量都在同一个前置处理器中(用户参数上定义),那么行都是顺序读取的。否则,不同线程可能会读取不同的行。
这一函数并不适合于读取很大的文件,因为整个文件都会被存储到内存之中。对于较大的文件,请使用配置元件CSV Data Set或者StringFromFile 。
11、__property
函数__property会返回一个JMeter属性的值。如果函数找不到属性值,而又没有提供默认值,则它会返回属性的名称。
例如:
${__property(user.dir)}:返回属性user.dir的值;
${__property(user.dir,UDIR)}:返回属性user.dir的值,并保存在变量UDIR中;
${__property(abcd,ABCD,atod)}:返回属性abcd的值 (如果属性没有定义,返回"atod"),并保存在变量ABCD 中;
${__property(abcd,,atod)}:返回属性abcd 的值(如果属性没有定义,返回"atod"),但是并不保存函数的返回值;
参数如下表所示:
函数参数 |
描述 |
是否必需 |
属性名 |
获取属性值、所需的属性名 |
是 |
变量名 |
重用函数计算值的引用名 |
否 |
默认值 |
属性未定义时的默认值 |
否 |
12、_P
函数_P是一个简化版的属性函数,目的是使用在命令行中定义的属性。不同于函数_property,本函数没有提供选项用于设置保存属性值的变量。
另外,如果没有设置默认值,默认值自动设为1。之所以选择1,原因在于它对于很多常见测试变量都是一个合理值,例如,循环次数、线程数、启动线程耗时间等。
例如:定义属性值:
jmeter -Jgroup1.threads=7 -Jhostname1=www.realhost.edu
获取值如下:
${__P(group1.threads)}:返回属性group1.threads的值;
${__P(group1.loops)}:返回属性group1.loops 的值;
${__P(hostname,www.dummy.org)}:返回属性hostname的值,如果没有定义该属性则返回值www.dummy.org;
在上面的例子中,第一个函数调用返回7,第二个函数调用返回1,而最后一个函数调用返回www.dummy.org(除非这些属性在其他地方有定义);
参数如下表所示:
函数参数 |
描述 |
是否必需 |
属性名 |
获取属性值、所需的属性名 |
是 |
默认值 |
属性未定义时的默认值。如果省略此参数,默认值自动设为1 |
否 |
13、__log
函数__log会记录一条日志,并返回函数的输入字符串。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
待记录字符串 |
一个字符串 |
是 |
日志级别 |
OUT、ERR、DEBUG、INFO(默认)、WARN或者ERROR |
否 |
可抛弃的文本 |
如果非空,会创建一个可抛弃的文本传递给记录器 |
否 |
注释 |
如果存在,注释会在字符串中展示,用于标识日志记录了什么 |
否 |
OUT和ERR的日志级别,将会分别导致输出记录到System.out和System.err中。在这种情况下,输出总是会被打印(它不依赖于当前的日志设置)。
例如:
${__log(Message)}:写入日志文件,形如"...thread Name : Message";
${__log(Message,OUT)}:写到控制台窗口;
{__log({__log({VAR},,,VAR=)}:写入日志文件,形如"...thread Name VAR=value";
14、__logn
函数__logn会记录一条日志,并返回空字符串。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
待记录字符串 |
一个字符串 |
是 |
日志级别 |
OUT,ERR,DEBUG, INFO(默认),WARN 或者ERROR |
否 |
可抛弃的文本 |
如果非空,会创建一个可抛弃的文本传递给记录器 |
否 |
OUT和ERR的日志级别,将会分别导致输出记录到System.out和System.err中。在这种情况下,输出总是会被打印(它不依赖于当前的日志设置)。
例如:{__logn(VAR1={__logn(VAR1={VAR1},OUT)}:将变量值写到控制台窗口中。
15、__BeanShell
函数__BeanShell会执行传递给它的脚本,并返回结果。关于BeanShell的详细资料,请参考BeanShell的Web站点:http://www.beanshell.org/ 。
需要注意,测试脚本中每一个独立出现的函数调用,都会使用不同的解释器,但是后续对函数调用的援引会使用相同的解释器;这就意味着变量会持续存在,并跨越函数调用。
单个函数实例可以从多个线程调用。另外,该函数的execute()方法是同步的。如果定义了属性"beanshell.function.init",那么它会作为一个源文件传递给解释器。
这样就可以定义一些通用方法和变量。在bin目录中有一个初始化文件的例子:BeanShellFunction.bshrc。
如下变量在脚本执行前就已经设置:
log:函数BeanShell(*)的记录器;
ctx:目前的JMeter Context变量;
vars:目前的JMeter变量;
props:JMeter属性对象;
threadName:线程名(字符串);
sampler:当前采样器(如果存在);
sampleResult:当前采样器(如果存在);
"*"意味着该变量在JMeter使用初始化文件之前就已经设置了。其他变量在不同调用之间可能会发生变化;
参数如下表所示:
函数参数 |
描述 |
是否必需 |
BeanShell脚本 |
一个BeanShell脚本(不是文件名) |
是 |
变量名 |
重用函数计算值的引用名 |
否 |
例如:
${__BeanShell(123*456)}:回56088;
${__BeanShell(source("function.bsh"))}:行在function.bsh中的脚本;
请记得为文本字符串及代表文本字符串的JMeter变量添加必要的引号;
16、__plit
函数__split会通过分隔符来拆分传递给它的字符串,并返回原始的字符串。如果分隔符紧挨在一起,那么函数就会以变量值的形式返回"?"。
拆分出来的字符串,以变量${VAR_1}、{VAR_2}…以此类推的形式加以返回。JMeter 2.1.2及其以后版本,拖尾的分隔符会被认为缺少一个变量,会返回"?"。
另外,为了更好地配合ForEach控制器,现在__split会删除第一个不用的变量(由前一次分隔符所设置)。
在测试计划中定义变量VAR="a||c|":{__split({__split({VAR},VAR),|} ,该函数调用会返回VAR变量的值,例如"a||c|",并设定VAR_n=4(3 ,JMeter 2.1.1及以前版本)、
VAR_1=a、VAR_2=?、VAR_3=c、VAR_4=?(null,JMeter 2.1.1及其以前版本)、VAR_5=null(JMeter 2.1.2及其以后版本)变量的值。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
待拆分字符串 |
一个待拆分字符串,例如“a|b|c” |
是 |
变量名 |
重用函数计算值的引用名 |
否 |
分隔符 |
分隔符,例如“|”。如果省略了此参数,函数会使用逗号做分隔符。需要注意的是,假如 要多此一举,明确指定使用逗号,需要对逗号转义,如“\,” |
否 |
17、__XPath
函数__XPath读取XML文件,并在文件中寻找与指定XPath相匹配的地方。每调用函数一次,就会返回下一个匹配项。到达文件末尾后,会从头开始。
如果没有匹配的节点,那么函数会返回空字符串,另外,还会向JMeter日志文件写一条警告信息;整个节点列表都会被保存在内存之中。
例如:
${__XPath(/path/to/build.xml, //target/@name)}
这会找到build.xml文件中的所有目标节点,并返回下一个name属性的内容。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
XML文件名 |
一个待解析的XML文件名 |
是 |
XPath |
一个XPath表达式,用于在XML文件中寻找目标节点 |
是 |
18、__setProperty
函数__setProperty用于设置JMeter属性的值。函数的默认返回值是空字符串,因此该函数可以被用在任何地方,只要对函数本身调用是正确的。
通过将函数可选的第3个参数设置为"true",函数就会返回属性的原始值。属性对于JMeter是全局的,因此可以被用来在线程和线程组之间通信。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
属性名 |
待设置属性名 |
是 |
属性值 |
属性的值 |
是 |
True/False |
是否返回属性原始值 |
否 |
19、__time
函数__time可以通过多种格式返回当前时间。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
格式 |
设置时间所采用的格式 |
否 |
变量名 |
待设置变量名 |
否 |
如果省略了格式字符串,那么函数会以毫秒的形式返回当前时间。其他情况下,当前时间会被转成简单日期格式。包含如下形式:
YMD= yyyyMMdd;
HMS= HHmmss;
YMDHMS = yyyyMMdd-HHmmss;
USER1 = JMeter属性time.USER1;
USER2 = JMeter属性time.USER2;
用户可以通过修改JMeter属性来改变默认格式,例如:time.YMD=yyMMdd。
20、_jexl
函数_jexl可以用于执行通用JEXL表达式,并返回执行结果。感兴趣的读者可以从下面这两个网页链接获取更多关于JEXL的信息。
http://commons.apache.org/jexl/reference/syntax.html。
http://commons.apache.org/jexl/reference/examples.html#Example_Expressions。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
表达式 |
待执行的表达式。例如,6*(5+2) |
是 |
变量名 |
待设置变量名 |
否 |
如下变量可以通过脚本进行访问:
log:函数记录器;
ctx:JMeterContext对象;
vars:JMeterVariables对象;
props:JMeter属性对象;
threadName:字符串包含当前线程名称 (在2.3.2 版本中它被误写为"theadName");
sampler:当前的采样器对象(如果存在);
sampleResult:前面的采样结果对象(如果存在);
OUT- System.out,例如 OUT.println("message");
JEXL可以基于它们来创建类,或者调用方法,例如:
①Systemclass=log.class.forName("java.lang.System");
②now=Systemclass.currentTimeMillis();
需要注意的是,Web站点上的JEXL文档错误地建议使用"div"做整数除法。事实上"div"和"/"都执行普通除法。
JMeter 2.3.2以后的版本允许在表达式中包含多个声明。JMeter 2.3.2及其以前的版本只处理第一个声明(如果存在多个声明,就会记录一条警告日志)。
21、__V
函数__V可以用于执行变量名表达式,并返回执行结果。它可以被用于执行嵌套函数引用(目前JMeter不支持)。
例如,如果存在变量A1、A2和N=1,则:
${A1}:能正常工作;
{A{A{N}}:无法正常工作(嵌套变量引用);
{__V(A${N})}:可以正常工作。A{__V(A${N})}:可以正常工作。A{N}变为A1,函数 __V返回变量值A1;
参数如下表所示:
函数参数 |
描述 |
是否必需 |
变量名表达式 |
待执行变量名表达式 |
是 |
22、__evalVar
函数__evalVar可以用来执行保存在变量中的表达式,并返回执行结果。
如此一来,用户可以从文件中读取一行字符串,并处理字符串中引用的变量。例如,假设变量"query"中包含有"select columnfromcolumnfrom{table}",
而"column"和"table"中分别包含有"name"和"customers",那么${__evalVar(query)}将会执行"select name from customers"。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
变量名 |
待执行变量名 |
是 |
23、__eval
函数__eval可以用来执行一个字符串表达式,并返回执行结果。如此一来,用户就可以对字符串(存储在变量中)中的变量和函数引用做出修改。
例如,给定变量name=Smith、column=age、table=birthdays、SQL=select columnfromcolumnfrom{table} where name='${name}',
那么通过{__eval({__eval({SQL})},就能执行"select age from birthdays where name='Smith'"。这样一来,就可以与CSV数据集相互配合;
例如:将SQL语句和值都定义在数据文件中。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
变量名 |
待执行变量 |
是 |
24、__char
函数__char会将一串数字翻译成Unicode字符,另外还请参考下面__unescape()函数。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
Unicode字符编码(十进制数或者十六进制数) |
待转换的Unicode字符编码,可以是十进制数或者十六进制数 |
是 |
Unicode字符编码(十进制数或者十六进制数) 待转换的Unicode字符编码,可以是十进制数或者十六进制数;
例如:
①${__char(0xC,0xA)} = CRLF
②${__char(165)} = � (yen)
25、__unescape
函数__unescape用于反转义Java-escaped字符串,另外还请参考上面的__char函数。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
待反转义字符串 |
待反转义字符串 |
是 |
例如:
①${__unescape(\r\n)} = CRLF
②${__unescape(1\t2)} = 1[tab]2
26、__unescapeHtml
函数__unescapeHtml用于反转义一个包含HTML实体的字符串,将其变为包含实际Unicode字符的字符串。支持HTML 4.0实体。
例如,字符串"<Français>"变为"<Fran?ais>"。
如果函数不认识某个实体,就会将实体保留下来,并一字不差地插入结果字符串中。例如,">&zzzz;x"会变为">&zzzz;x"。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
待反转义字符串 |
待反转义字符串 |
是 |
27、__escapeHtml
函数__escapeHtml用于转义字符串中的字符(使用HTML实体)。支持HTML 4.0实体。
例如,"bread" & "butter"变为"bread" & "butter"。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
待转义字符串 |
待转义字符串 |
是 |
28、__FileToString
函数__FileToString可以被用来读取整个文件。每次对该函数的调用,都会读取整个文件。
如果在打开或者读取文件时发生错误,那么函数就会返回字符串"**ERR**"。
参数如下表所示:
函数参数 |
描述 |
是否必需 |
文件名 |
包含路径的文件名(路径可以是相对于JMeter启动目录的相对路径) |
是 |
文件编码方式(如果不采 用平台默认的编码方式) |
读取文件需要用到的文件编码方式。如果没有指明就使用平台默认的编码方式 |
否 |
变量名 |
引用名(refName)用于重用函数创建的值 |
否 |
三、变量
1、预定义变量
大多数变量都是通过函数调用和测试元件(如用户定义变量)来设置的;在这种情况下用户拥有对变量名的完整控制权。但是有些变量是JMeter内置的。例如:
Cookiename:包含Cookie值。
JMeterThread.last_sample_ok:最近的采样是否可以(true/false)。
2、预定义变量属性
JMeter属性集是在JMeter启动时通过系统属性初始化的;其他补充JMeter属性来自于jmeter.properties、user.properties或者命令行。
JMeter还另外定义了一些内置属性。下面是具体列表。从方便的角度考虑,属性START的值会被复制到同名变量中去。
START.MS:以毫秒为单位的JMeter启动时间;
START.YMD:JMeter启动日期格式yyyyMMdd;
START.HMS:JMeter启动时间格式HHmmss;
TESTSTART.MS:以毫秒为单位的测试启动时间;
请注意:START变量/属性表征的是JMeter启动时间,而非测试的启动时间。它们主要用于文件名之中。