1. .si文件
.si文件存储了段的元数据,主要涉及SegmentInfoFormat.java和Segmentinfo.java这两个文件。由于本文介绍的Solr4.8.0,所以对应的是SegmentInfoFormat的子类Lucene46SegmentInfoFormat。
首先来看下.si文件的格式
头部(header) |
版本(SegVersion) |
doc个数(SegSize) |
是否符合文档格式(IsCompoundFile) |
Diagnostics |
文件 |
Footer |
- 头部:同Segment_N的头部结构相同,包括包含了Magic,CodecName,Version三部分
- 版本:生成segment的编码版本
- 大小: segment索引的documents的个数
- IsCompoundFile:是否以复合文档格式存储,如果设置1则为复合文档格式
- Diagnostics:包含一些信息可以用于debug,比如Lucene版本,OS,java version,以及生成该segment生成的方式(merge,add,addindexs)等
- 文件:该段包含了哪些文件
- Footer: codec编码的结尾,包含了检验和以及检验算法ID
上文讲到Solr4.8.0使用的是Lucene46SegmentInfoFormat(说明4.6以后.si文件并未发生变化),那么来看下Lucene46SegmentInfoFormat的内容,从下文代码中可以看出,Lucene46SegmentInfoFormat内容很简单,只包含了一个Lucene46SegmentInfoReader和Lucene46SegmentInfoWriter实例
public class Lucene46SegmentInfoFormat extends SegmentInfoFormat {
private final SegmentInfoReader reader = new Lucene46SegmentInfoReader();
private final SegmentInfoWriter writer = new Lucene46SegmentInfoWriter();
/** Sole constructor. */
public Lucene46SegmentInfoFormat() {
}
@Override
public SegmentInfoReader getSegmentInfoReader() {
return reader;
}
@Override
public SegmentInfoWriter getSegmentInfoWriter() {
return writer;
}
/** File extension used to store {@link SegmentInfo}. */
public final static String SI_EXTENSION = "si";
static final String CODEC_NAME = "Lucene46SegmentInfo";
static final int VERSION_START = 0;
static final int VERSION_CHECKSUM = 1;
static final int VERSION_CURRENT = VERSION_CHECKSUM;
}
顾名思义,Lucene46SegmentInfoReader负责了对.si文件的读,Lucene46SegmentInfoWriter负责了对.si文件的写
public SegmentInfo read(Directory dir, String segment, IOContext context) throws IOException {
//获取segment的.si文件名
final String fileName = IndexFileNames.segmentFileName(segment, "", Lucene46SegmentInfoFormat.SI_EXTENSION);
//打开.si文件,获取文件信息,并检查检验和
final ChecksumIndexInput input = dir.openChecksumInput(fileName, context);
boolean success = false;
try {
//检查header,并返回编码版本
int codecVersion = CodecUtil.checkHeader(input, Lucene46SegmentInfoFormat.CODEC_NAME,
Lucene46SegmentInfoFormat.VERSION_START,
Lucene46SegmentInfoFormat.VERSION_CURRENT);
//获取版本
final String version = input.readString();
//获取documents个数
final int docCount = input.readInt();
if (docCount < 0) {
throw new CorruptIndexException("invalid docCount: " + docCount + " (resource=" + input + ")");
}
//是否复合文档格式
final boolean isCompoundFile = input.readByte() == SegmentInfo.YES;
//获取segemnt额外的信息
final Map<String,String> diagnostics = input.readStringStringMap();
//获取segment包含的文件
final Set<String> files = input.readStringSet();
//获取Footer(检验和以及ID)
if (codecVersion >= Lucene46SegmentInfoFormat.VERSION_CHECKSUM) {
CodecUtil.checkFooter(input);
} else {
CodecUtil.checkEOF(input);
}
//将从.si获取到的segment信息写入SegmentInfo中
final SegmentInfo si = new SegmentInfo(dir, version, segment, docCount, isCompoundFile, null, diagnostics);
si.setFiles(files);
success = true;
return si;
} finally {
if (!success) {
IOUtils.closeWhileHandlingException(input);
} else {
input.close();
}
}
}
Lucene46SegmentInfoReader是读取.si文件并生成Segmentinfo,那么可想而知Lucene46SegmentInfoWriter是将Segmentinfo信息写入.si文件中
public void write(Directory dir, SegmentInfo si, FieldInfos fis, IOContext ioContext) throws IOException {
//将要生成的.si的文件名
final String fileName = IndexFileNames.segmentFileName(si.name, "", Lucene46SegmentInfoFormat.SI_EXTENSION);
//将.si文件加入文件列表中
si.addFile(fileName);
//生成.si文件
final IndexOutput output = dir.createOutput(fileName, ioContext);
boolean success = false;
try {
//写入文件头header
CodecUtil.writeHeader(output, Lucene46SegmentInfoFormat.CODEC_NAME, Lucene46SegmentInfoFormat.VERSION_CURRENT);
// Write the Lucene version that created this segment, since 3.1
//写入version
output.writeString(si.getVersion());
//写入documents个数
output.writeInt(si.getDocCount());
//写入是否复合文档个数
output.writeByte((byte) (si.getUseCompoundFile() ? SegmentInfo.YES : SegmentInfo.NO));
//写入segment 额外的信息
output.writeStringStringMap(si.getDiagnostics());
//写入segment包含的文件
output.writeStringSet(si.files());
//写入footer 检验和以及ID
CodecUtil.writeFooter(output);
success = true;
} finally {
if (!success) {
IOUtils.closeWhileHandlingException(output);
si.dir.deleteFile(fileName);
} else {
output.close();
}
}
}
在Segmentinfo有个tostring()函数,当我们将solr的日志等级设置为debug时候,它会打印出.si的信息。比如它打印出"_a(3.1):c45/4",可以从中看出以下几个信息:
1、 _a是segment名字;
2、 (3.1)表示Lucene版本,如果出现?表示未知;
3、 c表示复合文档格式,C表示非复合文档格式;
4、 45表示segment具有45个documents;
5、 4表示删除的documents个数;
2. .fnm文件(域元数据文件)
前面讲的都是以segment为单位的,现在起开始学习segment的细分结构。首先学习的是.fnm(域元数据文件),它存储了segment内域的相关信息。
首先学习下.fnm的文件结构:
Header,FieldsCount, <FieldName,FieldNumber, FieldBits,DocValuesBits,DocValuesGen,Attributes> FieldsCount,Footer
-
Header: 同前文
-
FieldsCount:域的个数
-
<FieldName,FieldNumber, FieldBits,DocValuesBits,DocValuesGen,Attributes>FieldsCount: 包含FieldsCount个域的信息 -
FieldName:域名
-
FieldNumber:域的编号,不同与先前版本的域的编码是按在文件中的顺序编码,现在版本的域的编码是明确的。
-
FieldBits: 一系列标志位,表明对此域的索引方式
-
最低位:1表示此域被索引,0则不被索引。所谓被索引,也即放到倒排表中去。
- 仅仅被索引的域才能够被搜到。
- Field.Index.NO则表示不被索引。
- Field.Index.ANALYZED则表示不但被索引,而且被分词,比如索引"hello world"后,无论是搜"hello",还是搜"world"都能够被搜到。
- Field.Index.NOT_ANALYZED表示虽然被索引,但是不分词,比如索引"hello world"后,仅当搜"hello world"时,能够搜到,搜"hello"和搜"world"都搜不到。
- 一个域出了能够被索引,还能够被存储,仅仅被存储的域是搜索不到的,但是能通过文档号查到,多用于不想被搜索到,但是在通过其它域能够搜索到的情况下,能够随着文档号返回给用户的域。
- Field.Store.Yes则表示存储此域,Field.Store.NO则表示不存储此域。
-
第二最低位:1表示保存词向量,0为不保存词向量。
- Field.TermVector.YES表示保存词向量。
- Field.TermVector.NO表示不保存词向量。
-
第三最低位:1表示在位置列表中保存偏移量信息。
-
第四最低位:没用
-
第五最低位:1表示不保存标准化因子
- Field.Index.ANALYZED_NO_NORMS
- Field.Index.NOT_ANALYZED_NO_NORMS
-
第六最低位:是否保存payload
-
第七最低位:1表示不保存词的频率以及位置信息
-
第八最低位:不保存位置信息
-
DocValuesBits:一个字节表示DocValues的类型,低4位表示DocValues类型,高4位表示标准类型
-
DocValuesGen:DocValues的版本信息,如果该值为-1表示没有更新DocValues,大于0表示有更新
-
Attributes: 同前文
-
Footer:同前文
要了解域的元数据信息,还要了解以下几点:
-
位置(Position)和偏移量(Offset)的区别
-
位置是基于词Term的,偏移量是基于字母或汉字的。
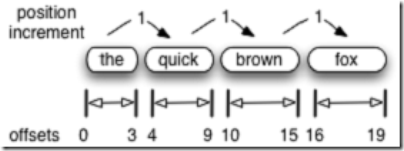
-
索引域(Indexed)和存储域(Stored)的区别
-
一个域为什么会被存储(store)而不被索引(Index)呢?在一个文档中的所有信息中,有这样一部分信息,可能不想被索引从而可以搜索到,但是当这个文档由于其他的信息被搜索到时,可以同其他信息一同返回。
-
举个例子,读研究生时,您好不容易写了一篇论文交给您的导师,您的导师却要他所第一作者而您做第二作者,然而您导师不想别人在论文系统中搜索您的名字时找到这篇论文,于是在论文系统中,把第二作者这个Field的Indexed设为false,这样别人搜索您的名字,永远不知道您写过这篇论文,只有在别人搜索您导师的名字从而找到您的文章时,在一个角落表述着第二作者是您。
-
payload的使用
-
我们知道,索引是以倒排表形式存储的,对于每一个词,都保存了包含这个词的一个链表,当然为了加快查询速度,此链表多用跳跃表进行存储。
-
Payload信息就是存储在倒排表中的,同文档号一起存放,多用于存储与每篇文档相关的一些信息。当然这部分信息也可以存储域里(stored Field),两者从功能上基本是一样的,然而当要存储的信息很多的时候,存放在倒排表里,利用跳跃表,有利于大大提高搜索速度。
-
Payload的存储方式如下图:
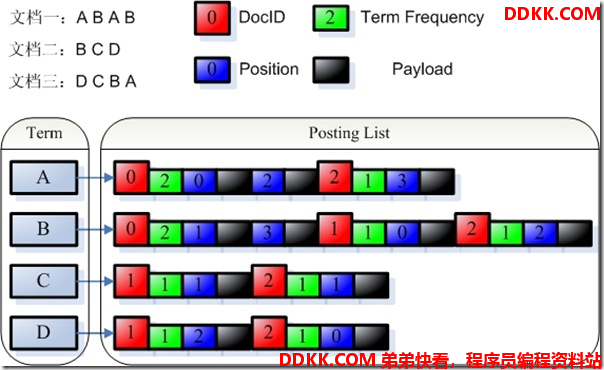 ]
]-
Payload主要有以下几种用法:
-
存储每个文档都有的信息:比如有的时候,我们想给每个文档赋一个我们自己的文档号,而不是用Lucene自己的文档号。于是我们可以声明一个特殊的域(Field)"_ID"和特殊的词(Term)"_ID",使得每篇文档都包含词"_ID",于是在词"_ID"的倒排表里面对于每篇文档又有一项,每一项都有一个payload,于是我们可以在payload里面保存我们自己的文档号。每当我们得到一个Lucene的文档号的时候,就能从跳跃表中查找到我们自己的文档号。
-
影响词的评分
- 在Similarity抽象类中有函数public float scorePayload(byte [] payload, int offset, int length) 可以根据payload的值影响评分。
同.si文件相同,.fnm同样有Lucene46FieldInfosFormat(包含Lucene46SegmentInfoReader,Lucene46FieldInfosWriter),以及FieldInfo
看下Lucene46SegmentInfoReader读取.fnm文件部分代码,Lucene46FieldInfosWriter内容差不多就不再介绍。
public FieldInfos read(Directory directory, String segmentName, String segmentSuffix, IOContext context) throws IOException {
//获取文件名
final String fileName = IndexFileNames.segmentFileName(segmentName, segmentSuffix, Lucene46FieldInfosFormat.EXTENSION);
//读取.fnm文件并检查检验和
ChecksumIndexInput input = directory.openChecksumInput(fileName, context);
boolean success = false;
try {
//header信息
int codecVersion = CodecUtil.checkHeader(input, Lucene46FieldInfosFormat.CODEC_NAME,
Lucene46FieldInfosFormat.FORMAT_START,
Lucene46FieldInfosFormat.FORMAT_CURRENT);
//域数量
final int size = input.readVInt(); //read in the size
FieldInfo infos[] = new FieldInfo[size];
for (int i = 0; i < size; i++) {
//域名
String name = input.readString();
//域编码
final int fieldNumber = input.readVInt();
//获取FieldBits 域的所有方式
byte bits = input.readByte();
//是否索引 &00000001
boolean isIndexed = (bits & Lucene46FieldInfosFormat.IS_INDEXED) != 0;
//是否保存字段的向量 &00000010
boolean storeTermVector = (bits & Lucene46FieldInfosFormat.STORE_TERMVECTOR) != 0;
//是否保存标准化因子 &00010000
boolean omitNorms = (bits & Lucene46FieldInfosFormat.OMIT_NORMS) != 0;
//是否保存playload &00100000
boolean storePayloads = (bits & Lucene46FieldInfosFormat.STORE_PAYLOADS) != 0;
final IndexOptions indexOptions;
if (!isIndexed) {
indexOptions = null;
//不保存字段的频率以及位置信息 &01000000
} else if ((bits & Lucene46FieldInfosFormat.OMIT_TERM_FREQ_AND_POSITIONS) != 0) {
//只有当域是可以被索引时,该值才能设1,
indexOptions = IndexOptions.DOCS_ONLY;
//不保存位置信息,&10000000
} else if ((bits & Lucene46FieldInfosFormat.OMIT_POSITIONS) != 0) {
//索引文档以及字段频率,禁止位置信息
indexOptions = IndexOptions.DOCS_AND_FREQS;
//是否在位置列表中保存偏移量信息
} else if ((bits & Lucene46FieldInfosFormat.STORE_OFFSETS_IN_POSTINGS) != 0) {
//索引文档,频率,位置以及偏移信息
indexOptions = IndexOptions.DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS;
} else {
//索引文档,频率以及位置信息。这是全文检索的默认情况,支持评分以及位置查询
indexOptions = IndexOptions.DOCS_AND_FREQS_AND_POSITIONS;
}
// DV Types are packed in one byte
//获取DocValuesBits
byte val = input.readByte();
//低4位表示DocValues类型
final DocValuesType docValuesType = getDocValuesType(input, (byte) (val & 0x0F));
//高4位表示标准类型
final DocValuesType normsType = getDocValuesType(input, (byte) ((val >>> 4) & 0x0F));
//DocValues的版本代号
final long dvGen = input.readLong();
final Map<String,String> attributes = input.readStringStringMap();
//将读取的域信息存在FiledInfo里面
infos[i] = new FieldInfo(name, isIndexed, fieldNumber, storeTermVector,
omitNorms, storePayloads, indexOptions, docValuesType, normsType, Collections.unmodifiableMap(attributes));
infos[i].setDocValuesGen(dvGen);
}
//添加Footer
if (codecVersion >= Lucene46FieldInfosFormat.FORMAT_CHECKSUM) {
CodecUtil.checkFooter(input);
} else {
CodecUtil.checkEOF(input);
}
FieldInfos fieldInfos = new FieldInfos(infos);//将所有的域信息存放到FieldInfos里面
success = true;
return fieldInfos;
} finally {
if (success) {
input.close();
} else {
IOUtils.closeWhileHandlingException(input);
}
}
}
private static DocValuesType getDocValuesType(IndexInput input, byte b) throws IOException {
if (b == 0) {
return null;
} else if (b == 1) {
return DocValuesType.NUMERIC; //每一个document都是数字类型。
} else if (b == 2) {
return DocValuesType.BINARY; //每一个document都是byte[]类型。值可能大于32766bytes,根据codec不同最大值不同。
} else if (b == 3) {
return DocValuesType.SORTED; //该byte[]类型,存放按前缀后缀规则,所有值进行排序,只存放不同的那部分,值小于32766bytes
} else if (b == 4) {
return DocValuesType.SORTED_SET;//set<byte[]>类型
} else {
throw new CorruptIndexException("invalid docvalues byte: " + b + " (resource=" + input + ")");
}
}
尽管上述的代码比较简单,但是具体的对DocValue的概念仍然不是在熟悉,所以去找了下关于DocValue的一些信息
3. DocValue
说实话,公司的项目中并未用到DocValue这个东西,之前只知道有这个配置项在Schema.xml里面,并未引起关注,直到现在源码上看到这个东西才想去学习下。DocValue是Solr4.2加入的特性,那么为什么要DocValue?
3.1 Solr中的使用
Solr标准的索引方式是反向索引,它将所有在Document里找到的term放到一起组成一个链表,而每一个term后面又跟着一个term出现过的document的链表以及出现过的次数。在上面的图中显示其原理。这是查询非常迅速,当用户查询某一个term时,已经有准备好的term到document的映射表了。
但是当涉及到sorting(排序), faceting(面搜索), and highlighting(以及高亮)逆向索引就变得不是那么高效了。比如faceting查询,首先得找出每一个document中出现的每一个term,然后使得每一个docID进行排序然后放入faceting list里面。对于Solr来说,这些是在内存中进行的,当document以及term多的时候,就会变得比较慢。
因此在Lucene4.2里引入了DocValue,它是行导向的结构,在建索引的时候形成document到term的映射,它使得aceting, sorting, and grouping 查询更加快速。
要使用它得在schema.xml上设置:
<``fieldname``=``"manu_exact"type``=``"string"indexed``=``"false"stored``=``"false"docValues``=``"true"/>
DocValue只对一些特定的类型有效,比如:
-
StrField这种String类型
-
如果field类型是single-valued(也就是multi-valued是false),Lucene就会使用SORTED类型
-
如果filed类型是multi-valued,Lucene就会使用SORTED_SET类型
-
Trie* fields 类型
-
如果field类型是single-valued(也就是multi-valued是false),Lucene就会使用NUMERIC类型
-
如果filed类型是multi-valued,Lucene就会使用SORTED_SET类型
DocValue具有以下优点以及缺点
- 近实时索引:在每一个索引段里面都会有一个docvalues数据结构,这个结构与索引同时建立,并且能够快速更新、生效;
- 基本的查询和过滤支持:你可以做基本的词、范围等基本查询,但是不参与评分,并且速度较慢,如果你对速度和评分排序有要求,你可以讲该字段设置为(indexed=”true”)
- 更好的压缩比: Docvalues fields 的压缩效果比 fieldcache好,但不强调做到极致。
- 节约内存:你可以定义一个fieldType的 docValuesFormat (docValuesFormat="Disk"),这样的只有一小部分数据加载到内存,其它部分保留在磁盘上。
- 对于静态存储的数据查询提升不明显
3.2 DocValue原理
Lucene有四个基础字段类型可以使用docvalues。目前Solr使用了其中三种:
- NUMERIC:每一个文档里面只有一个这样类型的单值字段。这就像在整个索引里有一个很大的long[],数据基于实际使用的值经过压缩的。
例如,假设有3个这样的文档:
doc[0] = 1005
doc[1] = 1006
doc[2] = 1005
在这个例子中,每个文档仅需要一个bit。
- SORTED:每一个文档里面有一个这样类型的单值字段。这就像在整个索引里有一个很大的String[], 但用的是不同的寻址方式。.每一个唯一的value被赋予一个数字代表其顺序。所以每个文档只是记录一个压缩后的整数,有字典来还原他们原来的词。
例如,假设有3个这样的文档:
doc[0] = “aardvark”
doc[1] = “beaver”
doc[2] = “aardvark”
值“aardvark” 被映射成0,”beaver”映射成1, 建立两个数据结构如下:
doc[0] = 0
doc[1] = 1
doc[2] = 0
term[0] = “aardvark”
term[1] = “beaver”
- SORTED_SET: 每个文档里面有一个string类型的多值字段。这个和SORTED类型比较相似,每个文档有一个value的”set”。(按照递增存储)。 这里刻意的去除了重复的value,并且忽略了原有value的排序。
例如,假设有3个这样的文档:
doc[0] = “cat”, “aardvark”, “beaver”, “aardvark”
doc[1] =
doc[2] = “cat”
值“aardvark” 被映射成0,”beaver”映射成1, “cat”映射成2,建立两个数据结构如下:
doc[0] = [0, 1, 2]
doc[1] = []
doc[2] = [2]
term[0] = “aardvark”
term[1] = “beaver”
term[2] = “cat”
- BINARY: 每个文档存在一个 byte[] array。这个编码及数据结构可以由用户自定义。