题记:最近有幸看到觉先大神的Lucene的博客,感觉自己之前学习的以及工作的太为肤浅,所以决定先跟随觉先大神的博客学习下Lucene的原理。由于觉先大神主要介绍的是Lucene3.X系的,那我就根据源码以及结合觉先大神的来学习下4.X系的。内容可能会有些变化,且加入下我个人的理解。
http://www.cnblogs.com/forfuture1978/archive/2009/12/14/1623597.html
基本类型
Lucene索引文件中,用一下基本类型来保存信息:
-
Byte:是最基本的类型,长8位(bit),应该也是Lucene的最小单位了吧。
-
Short:由两个Byte组成。
-
Int :由4个Byte组成。
-
Long:由8个Byte组成。
-
VInt:
-
变长的整数类型,它可能包含多个Byte,对于每个Byte的8位,其中后7位表示数值,最高1位表示是否还有另一个Byte,0表示没有,1表示有。
-
1到5个字节之间。
-
越前面的Byte表示数值的低位,越后面的Byte表示数值的高位。
-
例如130化为二进制为 1000, 0010,总共需要8位,一个Byte表示不了,因而需要两个Byte来表示,第一个Byte表示后7位,并且在最高位置1来表示后面还有一个Byte,所以为(1) 0000010,第二个Byte表示第8位,并且最高位置0来表示后面没有其他的Byte了,所以为(0) 0000001。
Value Byte 1 Byte 2 Byte 3
0 00000000
1 00000001
2 00000010
...
127 01111111
128 10000000 00000001
129 10000001 00000001
130 10000010 00000001
...
16,383 11111111 01111111
16,384 10000000 10000000 00000001
16,385 10000001 10000000 00000001
...
-
VLong:
-
变长的Long型,规则同VInt一样,最大字节数不同。
-
在1到9个字节之间
-
Char:是UTF-8编码的一系列Byte。
-
String:一个字符串首先是一个VInt来表示此字符串包含的字符的个数,接着便是UTF-8编码的字符序列Chars。
关于类型可以从Dataoutput.java 和 DataInput.java 上查看,以Dataoutput.java为例
- Int的存储方式,经过移位,分别存储为4个Byte
/** Writes an int as four bytes.
* <p>
* 32-bit unsigned integer written as four bytes, high-order bytes first.
*
* @see DataInput#readInt()
*/
public void writeInt(int i) throws IOException {
writeByte((byte)(i >> 24));
writeByte((byte)(i >> 16));
writeByte((byte)(i >> 8));
writeByte((byte) i);
}
- VInt的存储方式,可以看到首先与127作与操作,即判断是否大于127,若大于127就将第8位设1(表示还有下一字节),写入Byte并进行移位(除以127);否则就直接写入Byte(表示没有下一字节)
public final void writeVInt(int i) throws IOException {
while ((i & ~0x7F) != 0) {
writeByte((byte)((i & 0x7F) | 0x80));
i >>>= 7;
}
writeByte((byte)i);
}
- Long和VLong跟Int和VInt类似,这里就不再具体描述
- String类型的存储方式,String类型的存储是首先将String转换成UTF-8格式,然后存储一个Vint型的UTF-8字符串字符个数,最后实际的Bytes格式存储
public void writeString(String s) throws IOException {
final BytesRef utf8Result = new BytesRef(10);
UnicodeUtil.UTF16toUTF8(s, 0, s.length(), utf8Result);
writeVInt(utf8Result.length);
writeBytes(utf8Result.bytes, 0, utf8Result.length);
}
基本规则
Lucene为了使的信息的存储占用的空间更小,访问速度更快,采取了一些特殊的技巧,然而在看Lucene文件格式的时候,这些技巧却容易使我们感到困惑,所以有必要把这些特殊的技巧规则提取出来介绍一下。
规则的命名采用觉先大神的。
1.前缀后缀规则(Prefix+Suffix)
Lucene在反向索引中,要保存词典(Term Dictionary)的信息,所有的词(Term)在词典中是按照字典顺序进行排列的,然而词典中包含了文档中的几乎所有的词,并且有的词还是非常的长的,这样索引文件会非常的大。所谓前缀后缀规则,即当某个词和前一个词有共同的前缀的时候,后面的词仅仅保存前缀在词中的偏移(offset),以及除前缀以外的字符串(称为后缀),这样的好处就是能大大缩短存储空间。
 ]
]比如要存储如下词:term,termagancy,termagant,terminal,
如果按照正常方式来存储,需要的空间如下(前面讲到String类型的存储是Vint+字符串格式的):
[VInt = 4] [t][e][r][m],[VInt = 10][t][e][r][m][a][g][a][n][c][y],[VInt = 9][t][e][r][m][a][g][a][n][t],[VInt = 8][t][e][r][m][i][n][a][l]
共需要35个Byte.
如果应用前缀后缀规则,需要的空间如下:
[VInt = 4] [t][e][r][m],
[VInt = 4 (offset)][VInt = 6][a][g][a][n][c][y], 表示存储6个,且前面获取4个
[VInt = 8 (offset)][VInt = 1][t], 表示存储1个,且前面获取8个
[VInt = 4(offset)][VInt = 4][i][n][a][l] 表示存储4个,且前面获取4个
共需要22个Byte。
大大缩小了存储空间,尤其是在按字典顺序排序的情况下,前缀的重合率大大提高。
2. 差值规则(Delta)
前缀后缀规则是对应String类型,那么差值规则则应用于数字类型。
在Lucene的反向索引中,需要保存很多整型数字的信息,比如文档ID号,比如词(Term)在文档中的位置等等。
由上面介绍,我们知道,整型数字是以VInt的格式存储的。随着数值的增大,每个数字占用的Byte的个数也逐渐的增多。所谓差值规则(Delta)就是先后保存两个整数的时候,后面的整数仅仅保存和前面整数的差即可。
 ]
]比如要存储如下整数:16386,16387,16388,16389
如果按照正常方式来存储,需要的空间如下:
[(1) 000, 0010][(1) 000, 0000][(0) 000, 0001],[(1) 000, 0011][(1) 000, 0000][(0) 000, 0001],[(1) 000, 0100][(1) 000, 0000][(0) 000, 0001],[(1) 000, 0101][(1) 000, 0000][(0) 000, 0001]
供需12个Byte。
如果应用差值规则来存储,需要的空间如下:
[(1) 000, 0010][(1) 000, 0000][(0) 000, 0001],[(0) 000, 0001],[(0) 000, 0001],[(0) 000, 0001]
共需6个Byte。
大大缩小了存储空间,而且无论是文档ID,还是词在文档中的位置,都是按从小到大的顺序,逐渐增大的。
3. 或然跟随规则(A, B?)
4. 跳跃表规则(Skip list)
为了提高查找的性能,Lucene在很多地方采取的跳跃表的数据结构。
跳跃表(Skip List)是如图的一种数据结构,有以下几个基本特征:
- 元素是按顺序排列的,在Lucene中,或是按字典顺序排列,或是按从小到大顺序排列。
- 跳跃是有间隔的(Interval),也即每次跳跃的元素数,间隔是事先配置好的,如图跳跃表的间隔为3。
- 跳跃表是由层次的(level),每一层的每隔指定间隔的元素构成上一层,如图跳跃表共有2层。
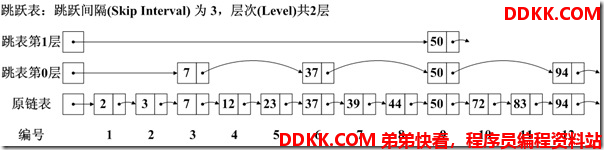 ]
]需要注意一点的是,在很多数据结构或算法书中都会有跳跃表的描述,原理都是大致相同的,但是定义稍有差别:
- 对间隔(Interval)的定义: 如图中,有的认为间隔为2,即两个上层元素之间的元素数,不包括两个上层元素;有的认为是3,即两个上层元素之间的差,包括后面上层元素,不包括前面的上层元素;有的认为是4,即除两个上层元素之间的元素外,既包括前面,也包括后面的上层元素。Lucene是采取的第二种定义。
- 对层次(Level)的定义:如图中,有的认为应该包括原链表层,并从1开始计数,则总层次为3,为1,2,3层;有的认为应该包括原链表层,并从0计数,为0,1,2层;有的认为不应该包括原链表层,且从1开始计数,则为1,2层;有的认为不应该包括链表层,且从0开始计数,则为0,1层。Lucene采取的是最后一种定义。
跳跃表比顺序查找,大大提高了查找速度,如查找元素72,原来要访问2,3,7,12,23,37,39,44,50,72总共10个元素,应用跳跃表后,只要首先访问第1层的50,发现72大于50,而第1层无下一个节点,然后访问第2层的94,发现94大于72,然后访问原链表的72,找到元素,共需要访问3个元素即可。
索引文件类型
索引文件类型主要包括以下:
| 文件名 | 文件后缀名 | 简介 |
Segments File |
segments.gen, segments_N | 一次提交操作的信息 |
| Lock File | write.lock | 写入锁,防止多个indexwriter同时操作相同文件 |
Segment Info |
si | 存储segment信息 |
Compound File |
.cfs, .cfe | 复合文件类型 |
Fields |
.fnm | 存储域信息 |
Field Index |
.fdx | 存储指向域数据的索引信息 |
Field Data |
.fdt | 存储域的元数据 |
Term Dictionary |
.tim | 存储词典以及域信息 |
Term Index |
.tip | 指向词典的索引信息 |
Frequencies |
.doc | 存储文档集包含词的频率信息,即某个词被文档引用的频率 |
Positions |
.pos | 存储词的位置信息 |
Payloads |
.pay | 存储附加到每个位置的元数据信息,如字符偏移量和用户的自定义信息(?) |
Norms |
.nvd, .nvm | 文件和域的length和boost |
Per-Document Values |
.dvd, .dvm | 存储了编码了的文档和域的长度和影响因子 |
Term Vector Index |
.tvx | 存储term在文档中的偏移量 |
Term Vector Documents |
.tvd | 存储每篇文档包含的term向量 |
Term Vector Fields |
.tvf | 存储term向量的域级别(?)信息 |
Deleted Documents |
.del | 存储删除的文档 |
Lock File
write.lock的作用是在同一时间内只有一个indexwriter在进行写入索引文件操作。如果write.lock文件跟索引文件不是相同路径,那么write.lock就会以索引文件的绝对路径作为前缀XXXX-write.lock
正向与反向索引
Lucene的索引文件分为正向索引和反向索引,正向索引包括从Index开始到Segment再到Document再到Field再到Term的这样一个层次,正向索引文件主要作用我认为是提供索引信息以及数据的存储。而反向索引是包含了Term到Document映射的过程,它提供一个由term查找document的功能。
所谓正向信息:
- 按层次保存了从索引,一直到词的包含关系:索引(Index) –> 段(segment) –> 文档(Document) –> 域(Field) –> 词(Term)
- 也即此索引包含了那些段,每个段包含了那些文档,每个文档包含了那些域,每个域包含了那些词。
- 既然是层次结构,则每个层次都保存了本层次的信息以及下一层次的元信息,也即属性信息,比如一本介绍中国地理的书,应该首先介绍中国地理的概况,以及中国包含多少个省,每个省介绍本省的基本概况及包含多少个市,每个市介绍本市的基本概况及包含多少个县,每个县具体介绍每个县的具体情况
所谓反向信息:
- 保存了词典到倒排表的映射:词(Term) –> 文档(Document)