一、前言
Hive 学习过程中的一个练习项目,如果不妥的地方或者更好的建议,欢迎指出! 😁
我们主要进行一下一些练习:
- 数据结构
- 数据清洗
- 基于Hive的数据分析
二、项目需求
首先和大家讲一下这个项目的需求:
对某零售企业最近1年门店收集的数据进行数据分析
- 潜在客户画像
- 用户消费统计
- 门店的资源利用率
- 消费的特征人群定位
- 数据的可视化展现
三、数据结构
本次练习一共用到四张表,如下:
Customer表

Transaction表

Store表

Review表

四、项目实战
Create HDFS Folder
hdfs dfs -mkdir -p /tmp/shopping/data/customer
hdfs dfs -mkdir -p /tmp/shopping/data/transaction
hdfs dfs -mkdir -p /tmp/shopping/data/store
hdfs dfs -mkdir -p /tmp/shopping/data/review
Upload the file to HDFS
hdfs dfs -put /opt/soft/data/customer_details.csv /tmp/shopping/data/customer/
hdfs dfs -put /opt/soft/data/transaction_details.csv /tmp/shopping/data/transaction/
hdfs dfs -put /opt/soft/data/store_details.csv /tmp/shopping/data/store/
hdfs dfs -put /opt/soft/data/store_review.csv /tmp/shopping/data/review/
Create database
drop database if exists shopping cascade
create database shopping
Use database
use shopping
Create external table
创建四张对应的外部表,也就是本次项目中的近源表。
create external table if not exists ext_customer_details(
customer_id string,
first_name string,
last_name string,
email string,
gender string,
address string,
country string,
language string,
job string,
credit_type string,
credit_no string
)
row format delimited fields terminated by ','
location '/tmp/shopping/data/customer/'
tblproperties('skip.header.line.count'='1')
create external table if not exists ext_transaction_details(
transaction_id string,
customer_id string,
store_id string,
price double,
product string,
buydate string,
buytime string
)
row format delimited fields terminated by ','
location '/tmp/shopping/data/transaction'
tblproperties('skip.header.line.count'='1')
create external table if not exists ext_store_details(
store_id string,
store_name string,
employee_number int
)
row format delimited fields terminated by ','
location '/tmp/shopping/data/store/'
tblproperties('skip.header.line.count'='1')
create external table if not exists ext_store_review(
transaction_id string,
store_id string,
review_score int
)
row format delimited fields terminated by ','
location '/tmp/shopping/data/review'
tblproperties('skip.header.line.count'='1')
通过UDF自定义 MD5加密函数
Create MD5 encryption function
这里通过UDF自定义 MD5加密函数 ,对地址、邮箱等信息进行加密。
-- md5 udf自定义加密函数
--add jar /opt/soft/data/md5.jar
--create temporary function md5 as 'com.shopping.services.Encryption'
--select md5('abc')
--drop temporary function encrymd5
Clean and Mask customer_details 创建明细表
create table if not exists customer_details
as select customer_id,first_name,last_name,md5(email) email,gender,md5(address) address,country,job,credit_type,md5(credit_no)
from ext_customer_details
对表内容进行检查,为数据清洗做准备
Check ext_transaction_details data
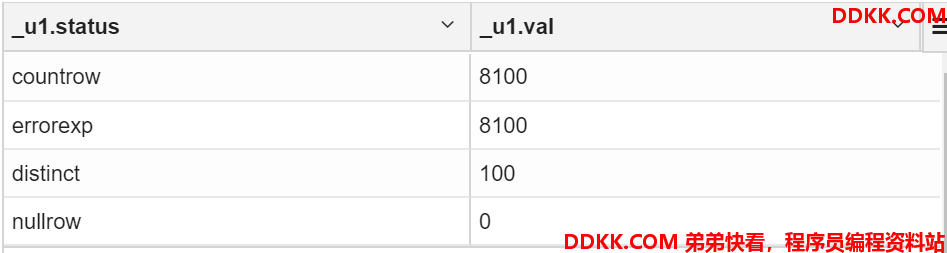
对transaction表的transaction_id进行检查,查看重复的、错误的、以及空值的数量。
这里从表中我们可以看到transaction_id存在100个重复的值。
with
t1 as (select 'countrow' as status,count(transaction_id) as val from ext_transaction_details),
t2 as (select 'distinct' as status,(count(transaction_id)-count(distinct transaction_id)) as val from ext_transaction_details),
t3 as (select 'nullrow' as status,count(transaction_id) as val from ext_transaction_details where transaction_id is null),
t4 as (select 'errorexp' as status,count(regexp_extract(transaction_id,'^([0-9]{1,4})$',0)) as val from ext_transaction_details)
select * from t1 union all select * from t2 union all select * from t3 union all select * from t4
Clean transaction_details into partition table
create table if not exists transaction_details(
transaction_id string,
customer_id string,
store_id string,
price double,
product string,
buydate string,
buytime string
)
partitioned by (partday string)
row format delimited fields terminated by ','
stored as rcfile
开启动态分区
set hive.exec.dynamic.partition=true
set hive.exec.dynamic.partition.mode=nonstrict
开启动态分区,通过窗口函数对数据进行清洗
Clear data and import data into transaction_details
-- partday 分区 transaction_id 重复
select if(t.ct=1,transaction_id,concat(t.transaction_id,'_',t.ct-1))
transaction_id,customer_id,store_id,price,product,buydate,buytime,date_format(buydate,'yyyy-MM')
as partday
from (select *,row_number() over(partition by transaction_id) as ct
from ext_transaction_details) t
insert into transaction_details partition(partday)
select if(t.ct=1,transaction_id,concat(t.transaction_id,'_',t.ct-1)) transaction_id,customer_id,store_id,price,product,buydate,buytime,date_format(regexp_replace(buydate,'/','-'),'yyyy-MM')
as partday from (select *,row_number() over(partition by transaction_id) as ct
from ext_transaction_details) t
- row_number() over(partition by transaction_id) 窗口函数 :从1开始,按照顺序,生成分组内记录的序列,row_number()的值不会存在重复,当排序的值相同时,按照表中记录的顺序进行排列 这里我们对分组的transaction_id
- if(t.ct=1,transaction_id,concat(t.transaction_id,'_',t.ct-1)) 如果满足ct=1,就是transaction_id,否则进行字符串拼接生成新的id
Clean store_review table
create table store_review
as select transaction_id,store_id,nvl(review_score,ceil(rand()*5))
as review_score from ext_store_review
NVL(E1, E2)的功能为:如果E1为NULL,则函数返回E2,否则返回E1本身。
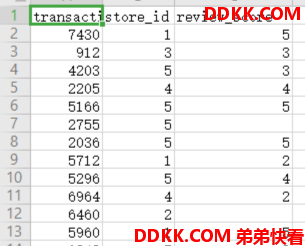
我们可以看到表中的数据存在空值,通过NVL函数对数据进行填充。
show tables

通过清洗后的近源表和明细表如上。
数据分析
Customer分析
- 找出顾客最常用的信用卡
select credit_type,count(credit_type) as peoplenum from customer_details
group by credit_type order by peoplenum desc limit 1
- 找出客户资料中排名前五的职位名称
select job,count(job) as jobnum from customer_details
group by job
order by jobnum desc
limit 5
- 在美国女性最常用的信用卡
select credit_type,count(credit_type) as femalenum from customer_details
where gender='Female'
group by credit_type
order by femalenum desc
limit 1
- 按性别和国家进行客户统计
select count(*) as customernum,country,gender from customer_details
group by country,gender
Transaction分析
- 计算每月总收入
select partday,sum(price) as countMoney from transaction_details group by partday
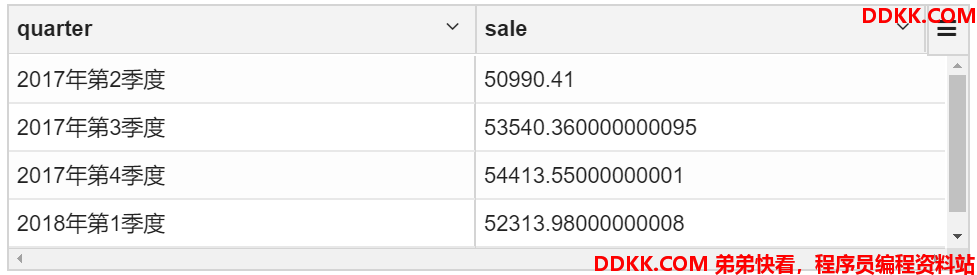
- 计算每个季度的总收入
Create Quarter Macro 定义季度宏,将时间按季度进行划分
create temporary macro
calQuarter(dt string)
concat(year(regexp_replace(dt,'/','-')),'年第',ceil(month(regexp_replace(dt,'/','-'))/3),'季度')
select calQuarter(buydate) as quarter,sum(price) as sale
from transaction_details group by calQuarter(buydate)
- 按年计算总收入
create temporary macro calYear(dt string) year(regexp_replace(dt,'/','-'))
select calYear(buydate) as year,sum(price) as sale from transaction_details group by calYear(buydate)
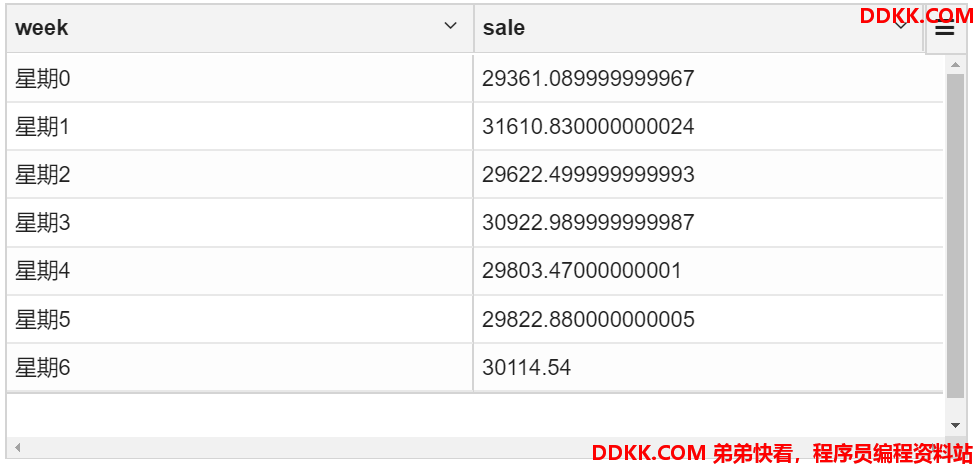
- 按工作日计算总收入
create temporary macro calWeek(dt string) concat('星期',dayofweek(regexp_replace(dt,'/','-'))-1)
select concat('星期',dayofweek(regexp_replace(buydate,'/','-'))-1) as week,sum(price) as sale
from transaction_details group by dayofweek(regexp_replace(buydate,'/','-'))
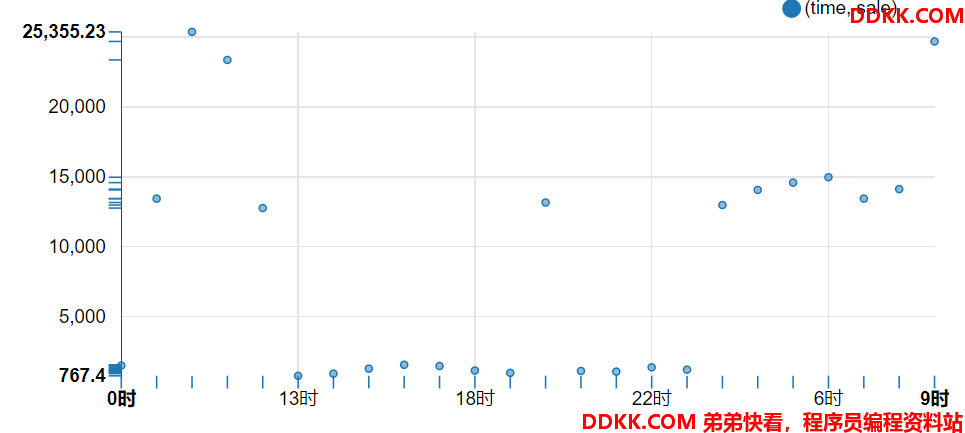
- 按时间段计算总收入(需要清理数据)
select concat(regexp_extract(buytime,'[0-9]{1,2}',0),'时') as time,sum(price) as sale from transaction_details group by regexp_extract(buytime,'[0-9]{1,2}',0)
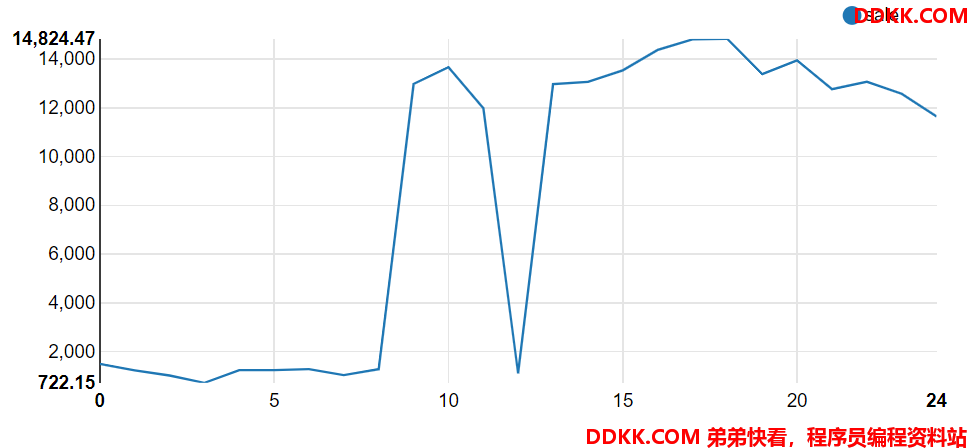
- 按时间段计算平均消费
Time macro
create temporary macro calTime(time string) if(split(time,' ')[1]='PM',regexp_extract(time,'[0-9]{1,2}',0)+12,
if(split(time,' ')[1]='AM',regexp_extract(time,'[0-9]{1,2}',0),split(time,':')[0]))
select calTime(buytime) as time,sum(price) as sale from transaction_details group by calTime(buytime)
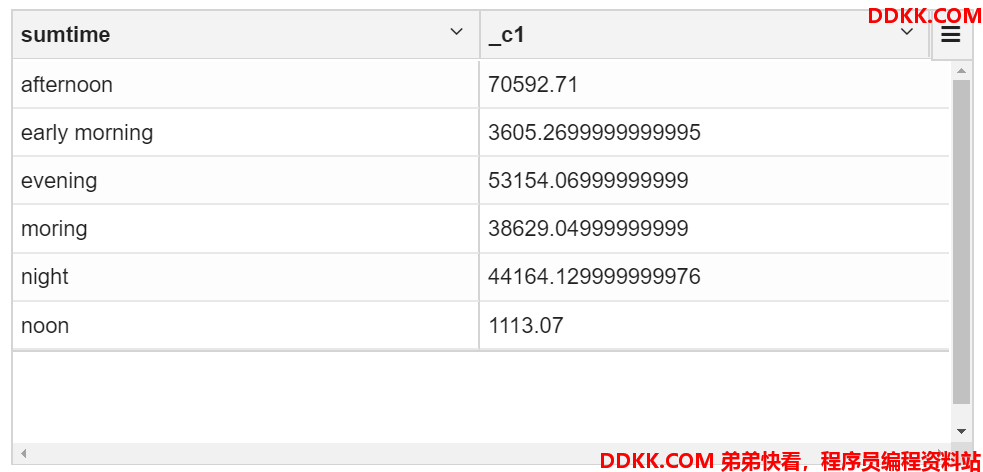
--define time bucket
--early morning: (5:00, 8:00]
--morning: (8:00, 11:00]
--noon: (11:00, 13:00]
--afternoon: (13:00, 18:00]
--evening: (18:00, 22:00]
--night: (22:00, 5:00] --make it as else, since it is not liner increasing
--We also format the time. 1st format time to 19:23 like, then compare, then convert minites to hours
with
t1 as
(select calTime(buytime) as time,sum(price) as sale from transaction_details group by calTime(buytime) order by time),
t2 as
(select if(time>5 and time<=8,'early morning',if(time >8 and time<=11,'moring',if(time>11 and time <13,'noon',
if(time>13 and time <=18,'afternoon',if(time >18 and time <=22,'evening','night'))))) as sumtime,sale
from t1)
select sumtime,sum(sale) from t2
group by sumtime
- 按工作日计算平均消费
select concat('星期',dayofweek(regexp_replace(buydate,'/','-'))-1)
as week,avg(price) as sale from transaction_details
where dayofweek(regexp_replace(buydate,'/','-'))-1 !=0 and dayofweek(regexp_replace(buydate,'/','-'))-1 !=6
group by dayofweek(regexp_replace(buydate,'/','-'))
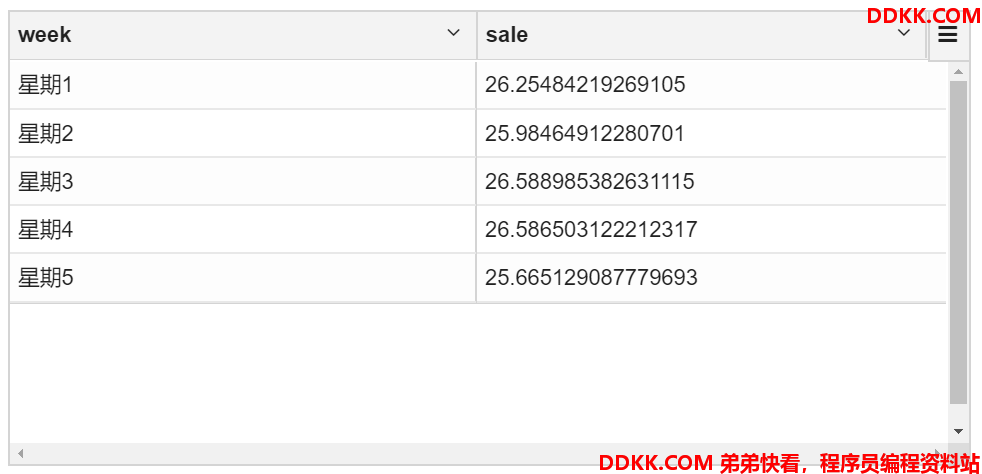
- 计算年、月、日的交易总数
select buydate as month,count(*) as salenum from transaction_details group by buydate
- 找出交易量最大的10个客户
select c.customer_id,c.first_name,c.last_name,count(c.customer_id) as custnum from customer_details c
inner join transaction_details t
on c.customer_id=t.customer_id
group by c.customer_id,c.first_name,c.last_name
order by custnum desc
limit 10
- 找出消费最多的前10位顾客
select c.customer_id,c.first_name,c.last_name,sum(price) as sumprice from customer_details c
inner join transaction_details t
on c.customer_id=t.customer_id
group by c.customer_id,c.first_name,c.last_name
order by sumprice desc
limit 10
- 统计该期间交易数量最少的用户
select c.customer_id,c.first_name,c.last_name,count(*) as custnum from customer_details c
inner join transaction_details t
on c.customer_id=t.customer_id
group by c.customer_id,c.first_name,c.last_name
order by custnum asc
limit 1
- 计算每个季度的独立客户总数
select calQuarter(buydate) as quarter,count(distinct customer_id) as uninum
from transaction_details
group by calQuarter(buydate)
- 计算每周的独立客户总数
select calWeek(buydate) as quarter,count(distinct customer_id) as uninum
from transaction_details
group by calWeek(buydate)
- 计算整个活动客户平均花费的最大值
select sum(price)/count(*) as sale
from transaction_details
group by customer_id
order by sale desc
limit 1
- 统计每月花费最多的客户
with
t1 as
(select customer_id,partday,count(distinct buydate) as visit from transaction_details group by partday,customer_id),
t2 as
(select customer_id,partday,visit,row_number() over(partition by partday order by visit desc) as visitnum from t1)
select * from t2 where visitnum=1
- 统计每月访问次数最多的客户
with
t1 as
(select customer_id,partday,sum(price) as pay from transaction_details group by partday,customer_id),
t2 as
(select customer_id,partday,pay,row_number() over(partition by partday order by pay desc) as paynum from t1)
select * from t2 where paynum=1
- 按总价找出最受欢迎的5种产品
select product,sum(price) as sale from transaction_details
group by product
order by sale desc
limit 5
- 根据购买频率找出最畅销的5种产品
select product,count(*) as num from transaction_details
group by product
order by num desc
limit 5
- 根据客户数量找出最受欢迎的5种产品
select product,count(distinct customer_id) as num from transaction_details
group by product
order by num desc
limit 5
- 验证前5个details
select * from transaction_details where product in ('Goat - Whole Cut')
Store分析
- 按客流量找出最受欢迎的商店
with
t1 as (select store_id,count(*) as visit from transaction_details
group by
store_id order by visit desc limit 1)
select s.store_name,t.visit
from t1 t
inner join
ext_store_details s
on t.store_id=s.store_id
- 根据顾客消费价格找出最受欢迎的商店
with
t1 as (select store_id,sum(price) as sale from transaction_details
group by
store_id order by sale desc limit 1)
select s.store_name,t.sale
from t1 t
inner join
ext_store_details s
on t.store_id=s.store_id
- 根据顾客交易情况找出最受欢迎的商店
with
t1 as
(select store_id,store_name from ext_store_details)
select t.store_id,store_name,count(distinct t.customer_id) as num
from transaction_details t
inner join t1 s
on s.store_id=t.store_id
group by t.store_id,store_name
order by num desc
limit 1
- 根据商店和唯一的顾客id获取最受欢迎的产品
with
t1 as (select store_id,product,count(distinct customer_id) as num from transaction_details
group by store_id,product order by num desc limit 1)
select s.store_name,t.num,t.product
from t1 t
inner join
ext_store_details s
on t.store_id=s.store_id
- 获取每个商店的员工与顾客比
with
t1 as (select store_id,count(distinct customer_id) as num from transaction_details
group by store_id )
select s.store_name,employee_number/num as vs from t1 t
inner join ext_store_details s
on t.store_id=s.store_id
- 按年和月计算每家店的收入
select store_id,partday,sum(price) from transaction_details group by store_id,partday
- 按店铺制作总收益饼图
select store_id,sum(price) from transaction_details group by store_id
- 找出每个商店最繁忙的时间段
with
t1 as
(select store_id,count(customer_id) as peoplenum from transaction_details group by store_id,concat(regexp_extract(buytime,'[0-9]{1,2}',0),'时')),
t2 as
(select store_id,peoplenum,row_number() over(partition by store_id order by peoplenum desc) as peo from t1 )
select t.store_id,e.store_name,t.peoplenum from t2 t
inner join ext_store_details e
on e.store_id = t.store_id
where peo =1
- 找出每家店的忠实顾客
with
t1 as
(select customer_id,store_id,count(customer_id) as visit from transaction_details group by store_id,customer_id ),
t2 as
(select customer_id,store_id,visit,row_number() over(partition by store_id order by visit desc) as most from t1)
select r.customer_id,concat(first_name,last_name) as customer_name,r.store_id,store_name,r.visit from t2 r
inner join customer_details c
on c.customer_id=r.customer_id
inner join ext_store_details e
on e.store_id=r.store_id
where most=1
- 根据每位员工的最高收入找出明星商店
with
t1 as
(select store_id,sum(price) as sumprice from transaction_details group by store_id)
select t.store_id,s.store_name,sumprice/employee_number as avgprice from t1 t
inner join ext_store_details s
on s.store_id=t.store_id
order by avgprice desc
Review分析
- 在ext_store_review中找出存在冲突的交易映射关系
select t.transaction_id,t.store_id from transaction_details t
inner join ext_store_review e
on e.transaction_id=t.transaction_id
where e.store_id!=t.store_id
- 了解客户评价的覆盖率
with
trans as (select store_id,count(transaction_id) as countSale from transaction_details group by store_id),
rev as (select store_id,count(distinct transaction_id) as review from store_review group by store_id)
select s.store_name,(r.review*100/t.countSale) as cover from trans t
inner join rev r
on t.store_id=r.store_id
inner join ext_store_details s
on t.store_id=s.store_id
- 根据评分了解客户的分布情况
select store_id,review_score,count(review_score) as numview from ext_store_review where review_score>0 group by review_score,store_id
- 根据交易了解客户的分布情况
select store_id,count(transaction_id) as transactionnum from ext_store_review group by store_id
- 客户给出的最佳评价是否总是同一家门店
select store_id,customer_id,count(customer_id) as visit from transaction_details t
join ext_store_review e
on e.transaction_id = t.transaction_id
where e.review_score=5
group by t.store_id,t.customer_id