一、简介
本文主要介绍Hive中的窗口函数,Hive中的窗口函数和SQL中的窗口函数相类似,都是用来做一些数据分析类的工作,一般用于olap分析(在线分析处理)。
二、概念
我们都知道在sql中有一类函数叫做聚合函数,例如sum()、avg()、max()等等,这类函数可以将多行数据按照规则聚集为一行,一般来讲聚集后的行数是要少于聚集前的行数的,但是有时我们想要既显示聚集前的数据,又要显示聚集后的数据,这时我们便引入了窗口函数。
在深入研究Over字句之前,一定要注意:在SQL处理中,窗口函数都是最后一步执行,而且仅位于Order by字句之前。
三、数据准备
我们准备一张order表,字段分别为name,orderdate,cost,数据内容如下:
jack 2015-04-03 23
jack 2015-01-01 10
tony 2015-01-02 15
jack 2015-02-03 23
tony 2015-01-04 29
jack 2015-01-05 46
jack 2015-04-06 42
tony 2015-01-07 50
jack 2015-01-08 55
mart 2015-04-08 62
mart 2015-04-09 68
neil 2015-05-10 12
mart 2015-04-11 75
neil 2015-06-12 80
mart 2015-04-13 94
在hive中建立一张表order,将数据插入进去。
四、聚合函数+over()
假如说我们想要查询在2015年4月份购买过的顾客及总人数,我们便可以使用窗口函数去去实现。
select name,count(*) over() from order where substring(orderdate,1,7)='2015-04';
得到结果如下:
mart 6
mart 6
mart 6
mart 6
jack 6
jack 6
可见其实在2015年4月一共有5次购买记录,mart购买了4次,jack购买了2次。事实上,大多数情况下,我们是只看去重后的结果的。针对于这种情况,我们想对代码改进,进行去重,该怎么办呢 😉
第一种方式:group by
select j.name,j.e from
(select name,count(*) over() as e from order where substring(orderdate,1,7)='2015-04') j
group by j.name,j.e;
结果如下:
jack 6
mart 6
第二种方式:distinct
select distinct name,count(*) over() from order where substring(orderdate,1,7)='2015-04';
结果如下:
jack 2
mart 2
五、partition by 子句
Over子句之后第一个提到的就是Partition By。Partition By子句也可以称为查询分区子句,非常类似于Group By,都是将数据按照边界值分组,而Over之前的函数在每一个分组之内进行,如果超出了分组,则函数会重新计算。
实例
我们想要去看顾客的购买明细及月购买总额,可以执行如下的sql。
select name,orderdate,cost,sum(cost) over(partition by month(orderdate))
from order
结果如下:
tony 2015-01-07 50 205
jack 2015-01-01 10 205
jack 2015-01-05 46 205
tony 2015-01-04 29 205
tony 2015-01-02 15 205
jack 2015-01-08 55 205
jack 2015-02-03 23 23
mart 2015-04-13 94 364
mart 2015-04-11 75 364
mart 2015-04-09 68 364
mart 2015-04-08 62 364
jack 2015-04-06 42 364
jack 2015-04-03 23 364
neil 2015-05-10 12 12
neil 2015-06-12 80 80
这里我们可以看到数据已经完全按照月份进行聚合。
六、order by 子句
上述的场景,假如我们想要将cost按照月进行累加,这时我们引入order by子句。
order by子句会让输入的数据强制排序(窗口函数是SQL语句最后执行的函数,因此可以把SQL结果集想象成输入数据)。Order By子句对于诸如Row_Number(),Lead(),LAG()等函数是必须的,因为如果数据无序,这些函数的结果就没有任何意义。因此如果有了Order By子句,则Count(),Min()等计算出来的结果就没有任何意义。
我们在上面的代码中加入order by
select name,orderdate,cost,sum(cost) over(partition by month(orderdate) order by orderdate)
from order;
结果如下:
jack 2015-01-01 10 10 // 10
tony 2015-01-02 15 25 // 10+15
tony 2015-01-04 29 54 // 25+29
jack 2015-01-05 46 100
tony 2015-01-07 50 150
jack 2015-01-08 55 205
jack 2015-02-03 23 23
jack 2015-04-03 23 23
jack 2015-04-06 42 65
mart 2015-04-08 62 127
mart 2015-04-09 68 195
mart 2015-04-11 75 270
mart 2015-04-13 94 364
neil 2015-05-10 12 12
neil 2015-06-12 80 80
七、window 子句
我们在上面已经通过使用partition by子句将数据进行了分组的处理,如果我们想要更细粒度的划分,我们就要引入window子句了。
我们首先要理解两个概念:
- 如果只使用partition by子句,未指定order by的话,我们的聚合是分组内的聚合。
- 使用了order by子句,未使用window子句的情况下,默认从起点到当前行。
当同一个select查询中存在多个窗口函数时,他们相互之间是没有影响的,每个窗口函数应用自己的规则。
window子句:
- PRECEDING:往前
- FOLLOWING:往后
- CURRENT ROW:当前行
- UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING:表示到后面的终点
我们按照name进行分区,按照购物时间进行排序,做cost的累加。
如下我们结合使用window子句进行查询
select name,orderdate,cost,
sum(cost) over() as fullagg, --所有行相加
sum(cost) over(partition by name) as fullaggbyname, --按name分组,组内数据相加
sum(cost) over(partition by name order by orderdate) as fabno, --按name分组,组内数据累加
sum(cost) over(partition by name order by orderdate rows between unbounded preceding and current row) as mw1 --和fabno一样,由最前面的起点到当前行的聚合
sum(cost) over(partition by name order by orderdate rows between 1 preceding and current row) as mw2, --当前行和前面一行做聚合
sum(cost) over(partition by name order by orderdate rows between 1 preceding and 1 following) as mw3, --当前行和前边一行及后面一行
sum(cost) over(partition by name order by orderdate rows between current row and unbounded following) as mw4 --当前行及后面所有行
from order;
结果如下:
jack 2015-01-01 10 684 199 10 10 10 56 199
jack 2015-01-05 46 684 199 56 56 56 111 189
jack 2015-01-08 55 684 199 111 111 101 124 143
jack 2015-02-03 23 684 199 134 134 78 101 88
jack 2015-04-03 23 684 199 157 157 46 88 65
jack 2015-04-06 42 684 199 199 199 65 65 42
mart 2015-04-08 62 684 299 62 62 62 130 299
mart 2015-04-09 68 684 299 130 130 130 205 237
mart 2015-04-11 75 684 299 205 205 143 237 169
mart 2015-04-13 94 684 299 299 299 169 169 94
neil 2015-05-10 12 684 92 12 12 12 92 92
neil 2015-06-12 80 684 92 92 92 92 92 80
tony 2015-01-02 15 684 94 15 15 15 44 94
tony 2015-01-04 29 684 94 44 44 44 94 79
tony 2015-01-07 50 684 94 94 94 79 79 50
八、窗口函数中的序列函数
主要序列函数是不支持window子句的。
hive中常用的序列函数有下面几个😀:
ntile
- NTILE(n),用于将分组数据按照顺序切分成n片,返回当前切片值
- NTILE不支持ROWS BETWEEN,
比如 NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING - AND CURRENT ROW) - 如果切片不均匀,默认增加第一个切片的分布
这个函数用什么应用场景呢?假如我们想要每位顾客购买金额前1/3的交易记录,我们便可以使用这个函数。
select name,orderdate,cost,
ntile(3) over() as sample1 , -- 全局数据切片
ntile(3) over(partition by name), -- 按照name进行分组,在分组内将数据切成3份
ntile(3) over(order by cost),-- 全局按照cost升序排列,数据切成3份
ntile(3) over(partition by name order by cost ) -- 按照name分组,在分组内按照cost升序排列,数据切成3份
from order
得到的数据如下:
jack 2015-01-01 10 3 1 1 1
jack 2015-02-03 23 3 2 1 1
jack 2015-04-03 23 3 3 1 2
jack 2015-04-06 42 2 1 2 2
jack 2015-01-05 46 2 3 2 3
jack 2015-01-08 55 2 2 2 3
mart 2015-04-08 62 2 1 3 1
mart 2015-04-09 68 1 2 3 1
mart 2015-04-11 75 1 3 3 2
mart 2015-04-13 94 1 1 3 3
neil 2015-05-10 12 1 2 1 1
neil 2015-06-12 80 1 1 3 2
tony 2015-01-02 15 3 2 1 1
tony 2015-01-04 29 3 1 2 2
tony 2015-01-07 50 2 3 2 3
如上述数据,我们去sample4 = 1的那部分数据就是我们要的结果
row_number
用途非常广泛,排序最好用它,它会为查询出来的每一行记录生成一个序号,依次排序且不会重复,注意使用row_number函数时必须要用over子句选择对某一列进行排序才能生成序号。
rank
函数用于返回结果集的分区内每行的排名,行的排名是相关行之前的排名数加一。简单来说rank函数就是对查询出来的记录进行排名,与row_number函数不同的是,rank函数考虑到了over子句中排序字段值相同的情况,如果使用rank函数来生成序号,over子句中排序字段值相同的序号是一样的,后面字段值不相同的序号将跳过相同的排名号排下一个,也就是相关行之前的排名数加一,可以理解为根据当前的记录数生成序号,后面的记录依此类推。
dense_rank
函数的功能与rank函数类似,dense_rank函数在生成序号时是连续的,而rank函数生成的序号有可能不连续。dense_rank函数出现相同排名时,将不跳过相同排名号,rank值紧接上一次的rank值。在各个分组内,rank()是跳跃排序,有两个第一名时接下来就是第三名,dense_rank()是连续排序,有两个第一名时仍然跟着第二名。
这三个窗口函数的使用场景非常多
- row_number():从1开始,按照顺序,生成分组内记录的序列,row_number()的值不会存在重复,当排序的值相同时,按照表中记录的顺序进行排列
- rank() :生成数据项在分组中的排名,排名相等会在名次中留下空位
- dense_rank() :生成数据项在分组中的排名,排名相等会在名次中不会留下空位
注意:
rank和dense_rank的区别在于排名相等时会不会留下空位
select name,orderdate,cost,
row_number() over(partition by name order by cost) as rn1,
rank() over(partition by name order by cost) as rn2,
dense_rank() over(partition by name order by cost) as rn3
from order;
jack 2015-01-01 10 1 1 1
jack 2015-02-03 23 2 2 2
jack 2015-04-03 23 3 2 2
jack 2015-04-06 42 4 4 3
jack 2015-01-05 46 5 5 4
jack 2015-01-08 55 6 6 5
mart 2015-04-08 62 1 1 1
mart 2015-04-09 68 2 2 2
mart 2015-04-11 75 3 3 3
mart 2015-04-13 94 4 4 4
neil 2015-05-10 12 1 1 1
neil 2015-06-12 80 2 2 2
tony 2015-01-02 15 1 1 1
tony 2015-01-04 29 2 2 2
tony 2015-01-07 50 3 3 3
lag 和 lead
这两个函数为常用的窗口函数,可以返回上下数据行的数据.
以我们的订单表为例,假如我们想要查看顾客上次的购买时间可以这样去查询
hive> select name,orderdate,cost,lag(orderdate,1,'1996-09-09')
over(partition by name order by orderdate ) as time1 from order;
select name,orderdate,cost,lag(orderdate,4)
over(partition by name order by orderdate ) as time2 from order;
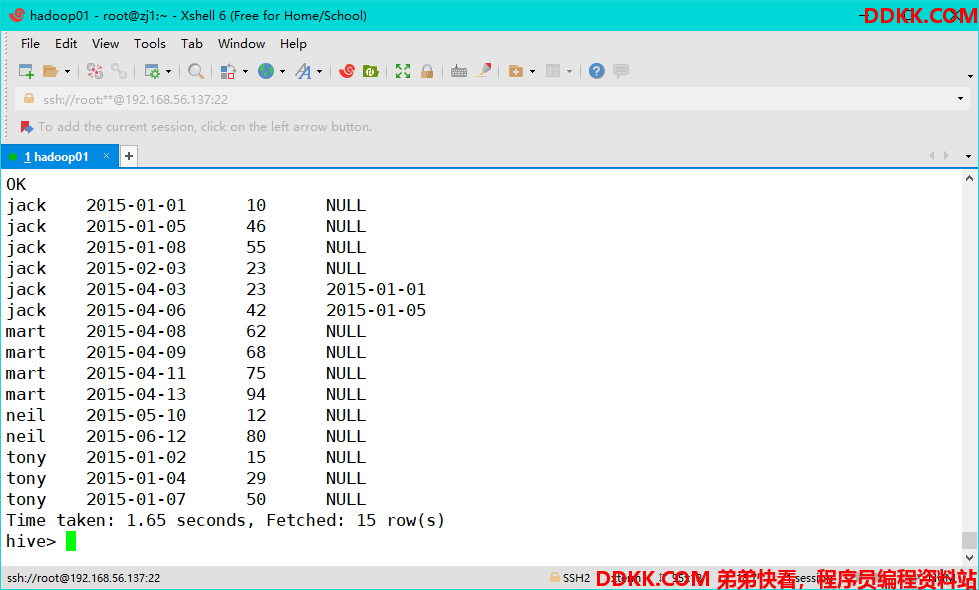
time1取的为按照name进行分组,分组内升序排列,取上一行数据的值。
time2取的为按照name进行分组,分组内升序排列,取上面4行的数据的值,注意当lag函数未设置行数值时,默认为1行.设定取不到时的默认值时,取null值。
lead函数与lag函数方向相反,取向下的数据,这里我就不再举例辣😂。
first_value 和 last_value
first_value取分组内排序后,截止到当前行,第一个值
last_value取分组内排序后,截止到当前行,最后一个值
select name,orderdate,cost,
first_value(orderdate) over(partition by name order by orderdate) as time1,
last_value(orderdate) over(partition by name order by orderdate) as time2
from order
查询结果如下:
name orderdate cost time1 time2
jack 2015-01-01 10 2015-01-01 2015-01-01
jack 2015-01-05 46 2015-01-01 2015-01-05
jack 2015-01-08 55 2015-01-01 2015-01-08
jack 2015-02-03 23 2015-01-01 2015-02-03
jack 2015-04-06 42 2015-01-01 2015-04-06
mart 2015-04-08 62 2015-04-08 2015-04-08
mart 2015-04-09 68 2015-04-08 2015-04-09
mart 2015-04-11 75 2015-04-08 2015-04-11
mart 2015-04-13 94 2015-04-08 2015-04-13
neil 2015-05-10 12 2015-05-10 2015-05-10
neil 2015-06-12 80 2015-05-10 2015-06-12
tony 2015-01-02 15 2015-01-02 2015-01-02
tony 2015-01-04 29 2015-01-02 2015-01-04
tony 2015-01-07 50 2015-01-02 2015-01-07