一、数据准备
hive> create database if not exists myhive;
hive> use myhive;
hive> drop table if exists student;
hive> create table student(
> stuid int,stuname string,stuage int,department string
> )
> row format delimited fields terminated by ' ';
hive> select * from student;
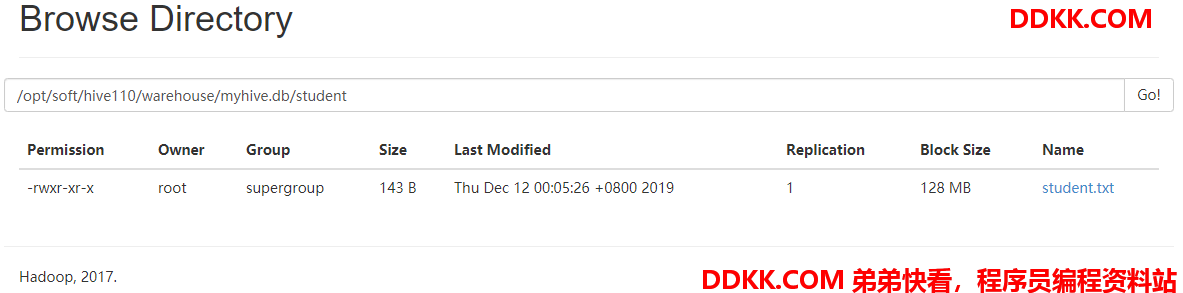
student.txt 内容如下:
1 tokgo 33 AA
2 chirs 44 CC
3 lucy 55 BB
4 tom 66 DD
5 jack 77 AA
6 john 44 BB
7 alis 77 CC
8 tony 33 CC
9 lelisy 99 DD
10 chery 88 AA
二、分区
hive表就是hdfs的上的一个目录
hive表中的数据,其实就是对应了HDFS上的一个目录下的数据
概念:对hive表的数据做分区管理
创建分区表
create table student_ptn(stuid int,stuname string)
partitioned by(stuage int,department string)
row format delimited fields terminated by ' ';
添加分区
// 添加一个分区
alter table student_ptn add partition(stuage=33,department="CC");
// 同时添加多个分区
alter table student_ptn add partition(stuage=77,department="AA") partition(stuage=66,department="DD");
// 添加成功,但是我们可以看到分区字段的顺序是在创建分区表的时候决定的
alter table student_ptn add partition(department="CC",stuage=44);
// 添加分区时,指定分区的数据存储目录
alter table student_ptn add partition(stuage=88,department="AA") location "/ptn_input1" partition(age=99,department="DD") location "/ptn_input2";
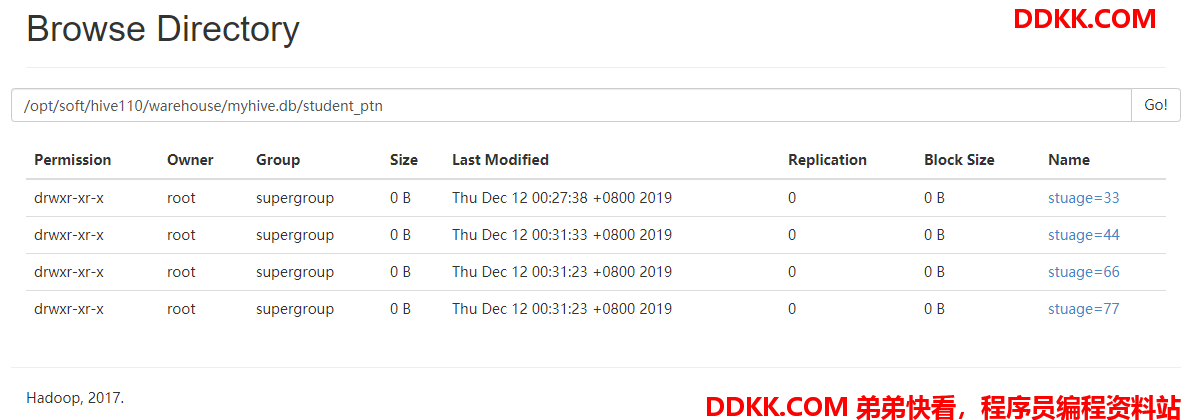
查询分区
show partitions student_ptn;
OK
stuage=33/department=CC
stuage=44/department=CC
stuage=66/department=DD
stuage=77/department=AA
修改分区
alter table student_ptn partition(age=44,department="AA") set location "hdfs://hadoop01:9000/ptn_input3";
// 往某个特定的分区导入数据
load data local inpath "/opt/soft/student.txt" into table student_ptn partition(age=55,department="BB");
// 不能直接往分区表导入数据
load data local inpath "/opt/soft/student.txt" into table student_ptn; //XXXXX
删除分区
alter table student_ptn drop partition(age=44,department="AA");
// 删除分区的时候,包括分区的元数据信息和分区的数据及目录
// 清空分区表的时候,分区还在,数据被清空
导入数据,大体上说,总共有三种方式:
1、 hadoopfs;
2、 load;
3、 insert…select…;
// 使用insert....values... 的方法是导入数据,主要用于测试
insert into table student_ptn values (101,"ning");
insert into table student_ptn partition(stuage=33,department="CC") values (101,"ning");
使用单重或者多重模式进去插入
from student
insert … select …
insert … select …
from student
insert into table student_ptn partition(stuage=18,department="AA") select id,name where age = 18
insert into table student_ptn partition(stuage=18,department="BB") select id,name where age = 19;
// 验证多重分区的插入是否成功
select id, name from student_ptn where stuage= 18 and department = "AA";
select id, name from student_ptn where stuage= 18 and department = "BB";
关于静态分区和动态分区,可以参考我的这篇博客,里面例子非常详细,这里就不再赘述:
【Hive】(五)Hive 中动态分区与静态分区详解
动态分区的效果:
按照动态分区的字段的值做划分,一个值就是一个分区
该studnet表当中的分区字段department有多少个值,就有多少个分区
每个分区就存一个分区字段值的所有数据
三、分桶
概念:对分区的进一步的 更细粒度的划分,与分区类似。
分桶的核心思想跟 MR程序的默认分区组件HashParititioner的原理一致
原理:根据key的hash值去模除以reduceTask的个数/mapreduce的分区个数/hive表的分桶个数
分桶的原理:
对分桶字段的值进行hash,然后模除以桶的个数,得到一个余数,该余数就是分桶的编号000000_0
MR 分区 mapper的outKey reduceTask的个数
hive 分桶 分桶字段的值 分桶的个数
分桶的效果:
分桶字段的值经过分桶逻辑计算之后得到的余数相同的都在同一个分桶文件中
一个分桶文件可能存在分桶字段的多个值
一个分桶文件也可能存在没有任何数据
表现形式上:
如果没有分区,那么分桶的目录就是表目录的下一级
如果有分区,那么分桶的目录在分区目录的下一级
分桶的操作:
create table student_bucket(stuid int,stuname string,stuage int,department string)
clustered by(stuage)
sorted by(stuage desc,stuid asc)
into 2 buckets
row format delimited fields terminated by " ";
往分桶表导入数据:
下面三种不可取!!
load data local inpath "/opt/soft/student.txt" into table student_bucket;
注意:往分桶表导入数据,不能使用load方式 XXXXXXXXXXXX
insert .... values ....
insert into table student_bucket values (101,"anni",22,"MM");
insert into table student_bucket values (102,"zuoyi",33,"NN");
// insert ....values... XXXXXXXXXXXX
// insert into .... select.....
// XXXXXXXXXXXX
insert into table student_bucket select id,name,sex,age,department from student;
正确的打开方式如下:
// 使用注意:打开分桶的开关,设置对应的reduceTask的个数要跟桶数匹配
set hive.enforce.bucketing = true;
set mapred.reduce.tasks = 2; / set mapreduce.job.reduces = 2;
hive> insert into table student_bucket select stuid,stuname,stuage,department from student distribute by stuage sort by stuage desc,stuid asc;
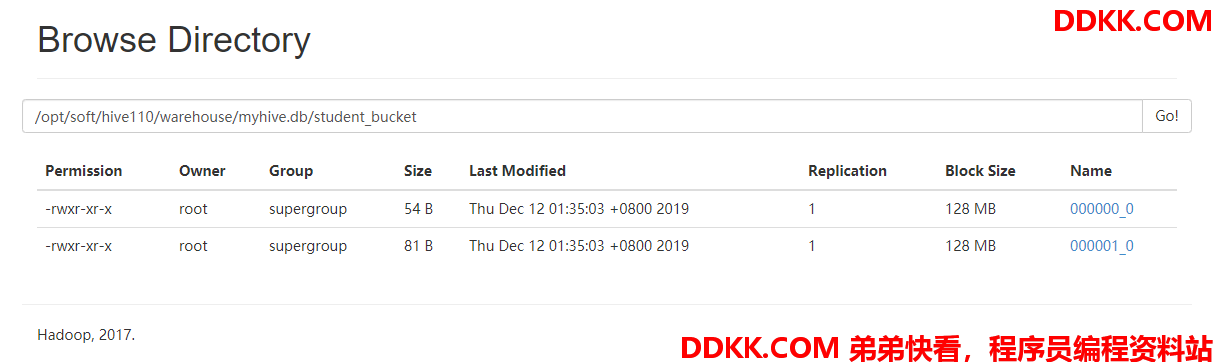
最后验证是否排序
注意:创建分桶时指定的分桶和排序等等的信息都不能在数据插入的时候起作用
数据到底有没有分桶是根据插入数据的HQL语句决定