1. 连接查询的本质
数据准备:
create table t1(
m1 int,
n1 char(1)
);
create table t2(
m2 int,
n2 char(1)
);
insert into t1 values(1,'a'),(2,'b'),(3,'c');
insert into t2 values(2,'b'),(3,'c'),(4,'d');
mysql> select * from t1,t2;
+------+------+------+------+
| m1 | n1 | m2 | n2 |
+------+------+------+------+
| 3 | c | 2 | b |
| 2 | b | 2 | b |
| 1 | a | 2 | b |
| 3 | c | 3 | c |
| 2 | b | 3 | c |
| 1 | a | 3 | c |
| 3 | c | 4 | d |
| 2 | b | 4 | d |
| 1 | a | 4 | d |
+------+------+------+------+
如果连接查询的结果集中包含一个表中的每一条记录和另一表中的每一条记录相互匹配的组合,那么这样的结果集称为笛卡尔积。如果不过滤任何条件,这些表连接起来产生的笛卡尔积可能是非常巨大的,所以连接时过滤掉特定的记录组合是有必要的。
select * from t1,t2 where t1.m1>1 and t1.m1=t2.m2 and t2.n2<'d';
步骤1:首先确定第一要要查询的表,这个表称为驱动表:
假设使用t1表作为驱动表,那么就需要查找满足t1.m1>1的记录
mysql> select * from t1 where t1.m1>1;
+------+------+
| m1 | n1 |
+------+------+
| 2 | b |
| 3 | c |
+------+------+
步骤2:步骤1中从驱动表每获取到一条记录,都需要到t2表中查找匹配的记录:
因为是根据t1表中的记录去查找t2表中的记录,所以t2表被称为被驱动表。步骤1从驱动表中得到了2条记录,也就意味着需要查询2次t2表。
t1.m1=2时,到t2表中根据t2.m2=2,t2.n2<'d'过滤条件执行单表查询。
select * from t2 where t2.m2=2 and t2.n2<'d';
t1.m1=3时,到t2表中根据t2.m2=3,t2.n2<'d'过滤条件执行单表查询。
select * from t2 where t2.m2=3 and t2.n2<'d';
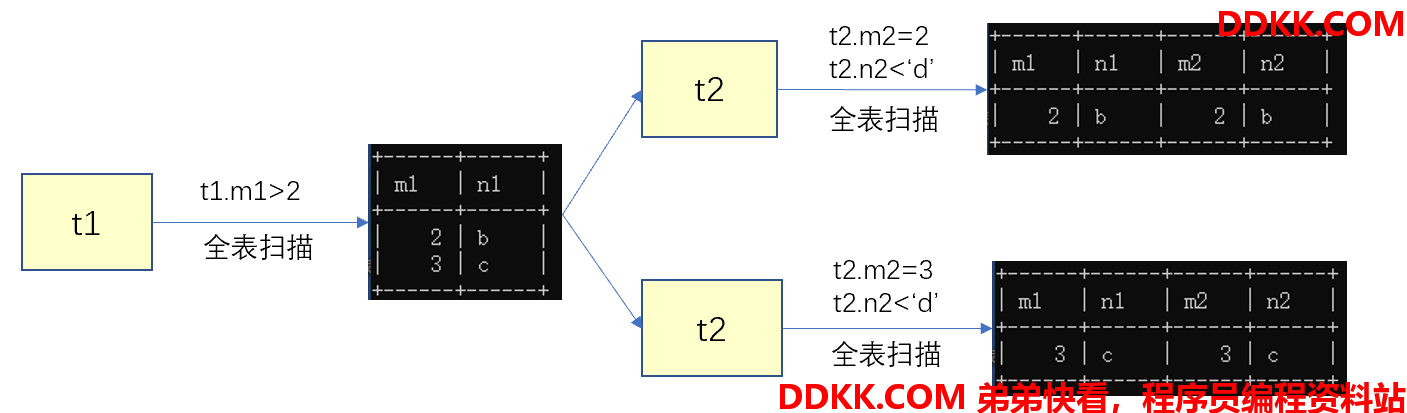
我们需要查询1次t1表,2次t2表,也就是说在连接查询时,驱动表需要访问1次,被驱动表需要访问多次。
2. 内连接和外连接
对于内连接的两个表,若驱动表中的记录在被驱动表中找不到匹配的记录,则该记录不会加入到最后的结果集。
对于外连接的两个表,即使驱动表中的记录在白驱动表中没有匹配的记录,也仍然需要加入到最后的结果集中。
对于左外连接,选取左侧的表为驱动表。
对于右外连接,选取右侧的表为驱动表。
3. 连接查询的原理
在MySQL中连接查询中,驱动表
1、 嵌套循环连接:;
驱动表只访问一次,但是被驱动表却可能访问多次,且访问次数取决于驱动表执行单表查询后的结果集中有多少记录的连接方式称为嵌套循环连接。这是最简单也是最笨拙的一种连接查询算法。
2、 使用索引加快连接速度:;
select * from t1,t2 where t1.m1>1 and t1.m1=t2.m2 and t2.n2<'d';
在嵌套循环连接中可能需要访问多次被驱动表。如果访问被驱动表的方式都是全表扫描,那就得扫描好多次,但是查询t2表其实就相当于一次单表查询,我们可以利用索引来加快查询速度。
当没有建立索引时,访问t1表的访问方法是all(全表扫描),访问t2表的访问方法也是all(全表扫描),即嵌套循环连接算法:
t1的条件已经确定的条件下,我们只需要优化t2表的查询即可:
在m2列上建立索引:
create index idx_m2 on t2(m2);
explain select * from t1,t2 where t1.m1>1 and t1.m1=t2.m2 and t2.n2<'d';

可以看到:
(1)t1表的type值为all说明是全表扫描;
(2)t2表的type值为ref,因为是针对m2列的等值查询;
(3)t2表的extra值为using where,因为无法直接在存储引擎层判断t2.m2=2 and t2.n2<'d'这个条件是否成立,仅对m2列建立索引,需要在回表之后在server层再判断t2.n2<'d'这个条件是否成立;
(4)t2表的key值为idx_m2,说明使用到了索引;
在n2列上建立索引:
create index idx_n2 on t2(n2);
explain select * from t1,t2 where t1.m1>1 and t1.m1=t2.m2 and t2.n2<'d';

可以看到:可能使用到的索引是idx_m2和idx_n2,实际使用的索引是idx_m2,说明使用这个索引的查询成本更低。
假如我们删除idx_m2这个索引:
drop index idx_m2 on t2;
explain select * from t1,t2 where t1.m1>1 and t1.m1=t2.m2 and t2.n2<'d';

访问方法:const>ref>ref_or_null>range>index>all
extra中出现了using index condition,using where,using join buffer
using index condition:
搜索条件出现了索引列n2,但是不能充当边界条件来形成扫描区间,也就是不能减少需要扫描的记录数量。
using where :
因为回表后将所有的记录返回给server层需要再判断m2列的条件是否成立,所以出现了using where。
using join buffer :
在连接查询的执行过程中,当被驱动表不能有效李立勇索引加快访问速度时,MySQL一般会为其分配一块连接缓冲区join buffer的内存快来加快连接查询速度。
join buffer:
如果被驱动表中的数据特别多而且不能使用索引进行访问,那就相当于要从磁盘上读这个表好多次,这个IO的代价就非常大了,驱动表的结果集中有多少条记录就有可能吧被驱动表从磁盘加载到内存中多少次,所以为了尽量减少被驱动表的访问次数,可以直接把被驱动表中的记录加载到内存中,一次性的与驱动表中的多条记录进行匹配,这样就可以大大的减少重复从磁盘上加载被驱动表的代价了,因此就出现了join buffer的概念。
join buffer是在执行连接查询前申请的一块固定大小的内存,先把若干条驱动表结果集中的记录装在这个join buffer中,然后开始执行扫描被驱动表,每一条被驱动表的记录一次性的与join buffer中的多条驱动表记录进行匹配,由于匹配的过程实在内存中完成的,所以这样可以显著减少被驱动表的IO代价。
4. 关联查询的优化
数据准备:
create table book(
bookid int(10) unsinged not null auto_increment,
card int(10) unsinged not null,
primary key(bookid)
);
create table type(
id int(10) unsinged not null auto_increment,
card int(10) unsinged not null,
primary key(id)
);
// 执行20次插入
insert into book(card) values(1+(rand()*20));
// 执行20次插入
insert into type(card) values(1+(rand()*20));
4.1 外连接优化
对于左外连接,左侧的表为驱动表;对于右外连接,选取右侧的表为驱动表。
1、两个表都没有索引:
explain select sql_no_cache * from type left join book on type.card=book.card;

2、给被驱动表建立索引:
create index idx_book on book(card);
explain select sql_no_cache * from type left join book on type.card=book.card;

3、给驱动表也建立索引:
create index idx_type on type(card);
explain select sql_no_cache * from type left join book on type.card=book.card;

连接查询时主要是为了降低被驱动表的查询成本,因此需要尽量在被驱动表的连接列上建立索引,这样就可以使用ref访问方法来降低被驱动表的访问成本了,如果可以,被驱动表的连接列最好是该表的主键或者唯一二级索引列,这样就可以把访问被驱动表的成本降至更低了。
4.2 内连接优化
删除索引:
drop index idx_book on book;
drop index idx_type on type;
explain select sql_no_cache * from type inner join book on type.card=book.card;

1、给book表的card列加索引:
create index idx_book on book(card);
explain select sql_no_cache * from type inner join book on type.card=book.card;

对于内连接来说:如果表的连接条件中,只能有一个字段有索引,那么查询优化器会将有索引的字段所在的表作为被驱动表。
2、给type表的card列加索引:
create index idx_type on type(card);
explain select sql_no_cache * from type inner join book on type.card=book.card;

对于内连接来说:如果表的连接条件中,两个表的字段都有索引,由查询优化器决定哪个表作为被驱动表,从结果可以看出book表作为被驱动表,ref访问方法。
3、增加type表中的数据:
// 之前type和book表中都有20条数据,现在type表中有21条数据
insert into type(card) values(1+(rand()*20));
explain select sql_no_cache * from type inner join book on type.card=book.card;

对于内连接来说:在两个表的连接条件都存在索引的情况下,会选择表中数据少的表作为驱动表,即小表作为驱动表,小表驱动大表。此时type表时被驱动表。