问题01:什么是Hash索引?
答案:
哈希索引基于哈希表实现,只有精确匹配索引列的查询才有效,对于每一行数据,存储引擎都会对索引列计算一个哈希码,不同行计算出来的哈希码不一样,哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。
create table testhash(
fname varchar(50) not null,
lname varchar(50) not null,
key using hash(fname)
) ENGINE=MEMORY;
mysql> select * from testhash;
+-------+---------+
| fname | lname |
+-------+---------+
| Aisa | John |
| Smith | Lisa |
| Doc | Sam |
| Dee | Sandra |
+-------+---------+
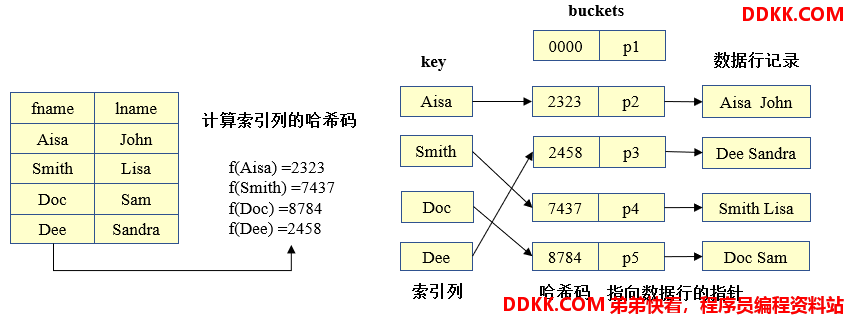
从上图可见,索引列在磁盘上本来是顺序存储的,建立hash索引后,哈希码是顺序的,但数据行此时已经不是按顺序存储的了。
select lname from testhash where fname='Aisa';
先计算Aisa的哈希码,并使用该值寻找对应的记录指针,因为f(Aisa) =2323,所以在hash索引中查找2323,可以找到指向第1行的指针,然后比较第1行的数据记录是否为Aisa,以确保就是要查找的行。
问题02:Hash索引和B+树有什么区别? 你在设计索引是怎么抉择的?
答案:
hash索引相对于B+树的优点:因为索引自身只需存储对应的哈希值,所以索引的结构非常紧凑,这也让哈希索引查找的速度非常快。
hash索引相对于B+树的缺点:
(1)哈希索引只包括哈希值和行指针,而不存储字段值,所以不能使用索引的值来避免读取行,不过,访问内存中的行的速度非常快,所以大部分情况下这一点对性能的影响并不明显;
(2)哈希索引数据并不是按照索引值顺序存储的,所以就无法用于排序;
(3)哈希索引也不支持部分索引列匹配查找,因为哈希索引始终是使用索引列的全部内容来计算哈希值的;例如,在数据列(A,B)上建立哈希索引,如果查询只有数据列A,则无法使用该索引。
(4)哈希索引只支持等值比较查询,包括=、in()、!=,也不支持任何范围查询,例如where a>10;
(5)访问哈希索引的数据非常快,除非有很多哈希冲突,当出现哈希冲突的时候,存储引擎必须遍历链表中所有的行指针,逐行进行比较,直到找到所有符合条件的行;
(6)如果哈希冲突很多的话,一些索引维护操作的代价也会很高;例如在某个哈希冲突很多的列上建立哈希索引,那么从表中删除一行时,存储引擎需要遍历对应哈希值的链表中的每一行,找到并删除对应行的引用,冲突越多,代价越大。
InnoDB存储引擎默认的索引是B+树,MyISAM存储引擎默认的索引是Hash索引,InnoDB存储引擎也支持Hash索引,即自适应Hash索引。
问题03:索引为什么要用B+树而不是二叉树?
答案:
磁盘的IO操作次数对索引的使用效率至关重要,如果索引的数据结构能尽量减少磁盘的IO操作次数,所消耗的时间也就越小,因此磁盘IO操作次数是决定索引选择何种数据结构的重要因素。
InnoDB将表中的数据存储在磁盘上,想要从表中查询某些数据时,并不是一条一条的将记录从磁盘中读取到内存,而是以页作为磁盘和内存之间交互的基本单位,页的大小一般为16KB,根据磁盘的局部性原理,为了尽量减少磁盘IO,磁盘往往不是严格按需读取,而是每次都会进行磁盘预读,即使只需要查询一条记录,磁盘也会读取一页的数据。
如果用树作为索引的数据结构,每查找一次数据就会从磁盘中读取树的一个节点,而二叉树的每个节点只存储一条数据(key+data)且不能占满页的存储空间,如果存储海量数据,二叉树的节点就会变得很多,高度变得很高,磁盘IO次数也会增加。但如果树每层的节点数和每个节点包含的关键字越多,则树的高度越矮,就能减少磁盘IO操作次数。
为了提高查询效率,就需要减少磁盘IO数 。为了减少磁盘IO的次数,就需要尽量降低树的高度 ,需要把原来“瘦高”的树结构变的“矮胖”,树的每层的分叉越多越好。
解读:
create table user(
id int,
name varchar,
primary key(id)
) ROW_FORMAT=COMPACT;
inset into user valus(10,'zs'),(7,'ls'),(13'cc'),(5,'zl'),(8,'xy'),(12,'xm'),(17,'dy');
假如我们使用二叉搜索树对表中的用户记录建立索引:
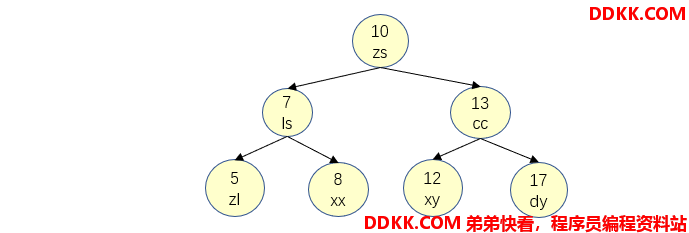
二叉树的每个页只存储一条数据(主键key+数据data),并不能填满一页的存储空间,那多余的存储空间岂不是要浪费了?为了解决二叉平衡搜索树的这个弊端,我们应该寻找一种单个节点可以存储更多数据(主键key+数据data)的数据结构,也就是B+树。
问题04:索引为什么要用B+树而不是B树?
答案:
多路搜索树通过增加每层节点的个数和在每个节点存放更多的数据从而降低树的高度,在数据查找时减少磁盘访问次数。在B树中,每个节点都是一个磁盘块。每个非叶子节点存放了关键字和指向儿子树的指针,具体数量为:M阶的B树,每个非叶子节点存放了M-1个关键字和M个指向子树的指针。如图为5阶B树结构的示意图:
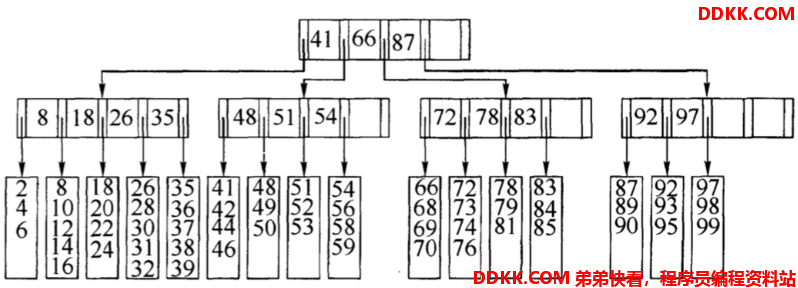
B树结构示意图:
B树相对于平衡二叉树,增加了每层节点的个数,并且每个节点存放了更多的数据从而降低树的高度。
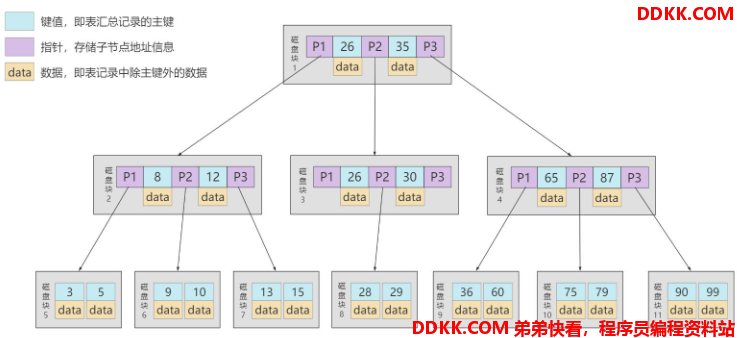
B+树结构示意图:
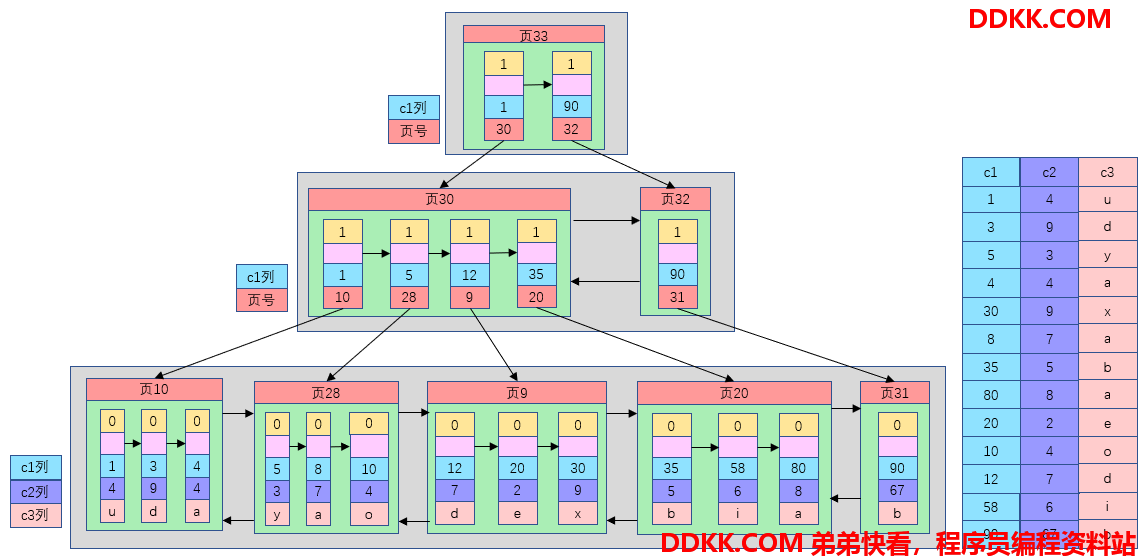
在B-Tree中,每个节点中不仅包含数据的key值,还有data值。而每一个页的存储空间是有限的,如果data数据较大时将会导致每个节点能存储的key的数量变少,当表中的数据量很大时同样会导致B-Tree的深度较大,增大查询时的磁盘I/O次数,进而影响查询效率。
在B+Tree中,非叶子节点仅存储了key值而没有存储data值,从而每个节点就可以存储更多的key,非叶子节点就可以有更多的子节点,树会变得更矮更胖,从而减少了磁盘IO的次数,查询效率更快。
在B+Tree中,所有的数据记录都存放在叶子节点中, 各节点按照索引列的大小通过双向链表连接,页内的节点按照索引列的大小通过单向链表连接, 通过这种方式可以找到表中的所有数据。
B+Tree使得范围查找,排序查找,分组查找效率更高。而B-Tree中的节点仅仅是按照索引列顺序存放的,并没有使用链表连接,数据分散在各个节点。
问题05:B树和B+树的区别?
(1)B+树的非叶子节点的子树指针与关键字个数相同,而B树的非叶子节点的子树指针=关键字个数+1;
(2)B+树的节点与节点之间是按照索引列的大小通过双向链表连接的,节点内的数据是按照索引列的大小通过单向链表连接的;
(3)B+树的非叶子节点仅用于索引,不保存数据记录,跟记录有关的信息都放在叶子节点中。而B树中, 非
叶子节点既保存索引,也保存数据记录 ;