1. 子查询优化
MySQL从4.1版本开始支持子查询,使用子查询可以进行SELECT语句的嵌套查询,即一个SELECT查询的结 果作为另一个SELECT语句的条件。
子查询可以一次性完成很多逻辑上需要多个步骤才能完成的SQL操作 。 子查询是 MySQL 的一项重要的功能,可以帮助我们通过一个 SQL 语句实现比较复杂的查询。但是,子 查询的执行效率不高。原因:
- 执行子查询时,MySQL需要为内层查询语句的查询结果 建立一个临时表 ,然后外层查询语句从临时表 中查询记录。查询完毕后,再 撤销这些临时表 。这样会消耗过多的CPU和IO资源,产生大量的慢查询。
- 子查询的结果集存储的临时表,不论是内存临时表还是磁盘临时表都 不会存在索引 ,所以查询性能会 受到一定的影响。
- 对于返回结果集比较大的子查询,其对查询性能的影响也就越大。
在MySQL中,可以使用连接查询来替代子查询。连接查询 不需要建立临时表 ,其 速度比子查询 要快 ,如果查询中使用索引的话,性能就会更好。
2. 排序(order by)优化
问题:在 WHERE 条件字段上加索引,但是为什么在 ORDER BY 字段上还要加索引呢?
我们在编写查询语句时,经常需要使用order by子句对查询出来的记录按照某种规则进行排序。在一般情况下,我们只能把记录加载到内存中,然后再用一些排序算法在内存中对这些记录进行排序。有时查询的结果集可能太大以至于在内存中无法进行排序,此时就需要暂时借助磁盘的空间来存放中间结果,在排序操作完成后再把排序的结果返回给客户端。
在MySQL中,这种在内存中或者磁盘中进行排序的方式称为文件排序,但是如果order by子句中使用了索引列,就有可能省去在内存或磁盘中排序的步骤。
优化建议:
- 可以在 WHERE 子句和 ORDER BY 子句中使用索引,目的是在 WHERE 子句中避免全表扫 描 ,在 ORDER BY 子句避免使用 FileSort 排序 。当然,某些情况下全表扫描,或者 FileSort 排 序不一定比索引慢。但总的来说,我们还是要避免,以提高查询效率。
- 尽量使用 Index 完成 ORDER BY 排序。如果 WHERE 和 ORDER BY 后面是相同的列就使用单索引列; 如果不同就使用联合索引。
- 无法使用 Index 时,需要对 FileSort 方式进行调优。
1、案例演示
数据见博客:https://blog.csdn.net/qq_42764468/article/details/123570297?spm=1001.2014.3001.5501
①没有索引时:
// 删除所有索引后,执行
explain select sql_no_cache * from student order by age,classId;

②添加索引后:
create index idx_age_classId on student(age,classId);
explain select sql_no_cache * from student order by age,classId;

为什么加了索引后仍然没有使用索引进行排序?
查询优化器会计算使用全表扫描执行查询的成本,使用二级索引+回表执行查询的成本,然后选择使用哪种方式。需要执行回表操作的记录数越多,使用二级索引进行查询的性能也就越低,某些查询宁愿使用全表扫描也不使用二级索引。如果需要执行回表操作的记录数越多,就越倾向于使用全表扫描,反之倾向于使用二级索引+回表的方式。
一般情况下,可以给查询语句指定limit子句来限定查询返回的记录数,这可能会让查询优化器倾向于选择二级索引+回表的方式进行查询,原因是回表的记录越少,性能提升就越高,比如,上面的查询语句就可以改写成下面的形式:
explain select sql_no_cache * from student order by age,classId limit 10;

问题:extra为null和extra为using where的区别?
extra值为null:这个查询将会使用二级索引,但是由于查询条件是*,存储引擎需要根据二级索引记录执行回表操作,并将完整的用户记录返回给server层。
extra值为using where:这个查询将会使用二级索引,但是由于查询条件是*,存储引擎需要根据二级索引记录执行回表操作,并将完整的用户记录返回给server层之后,再判断某个搜索条件是否成立。
explain select sql_no_cache * from student where name='abc'order by age,classId limit 10;

需要在server层判断name='abc’条件是否成立,所以出现了using where。
③使用覆盖索引:
explain select sql_no_cache age,classId from student order by age,classId limit 10;

当使用覆盖索引的方式执行查询时就会出现using index。
2、案例演示
// 删除所有索引后执行
CALL proc_drop_index("atguigudb1","student");
create index idx_age_classId_name_stuno on student(age,classId,stuno);
create index idx_age_classId_name_name on student(age,classId,name);
// 缺少age列,索引失效
explain select * from student order by classId limit 10;
// 缺少age列,索引失效
explain select * from student order by classId,name limit 10;
explain select * from student order by age,classId,name limit 10;
// 索引失效,字段排序方式不一致
explain select * from student order by age desc,classId asc limit 10;
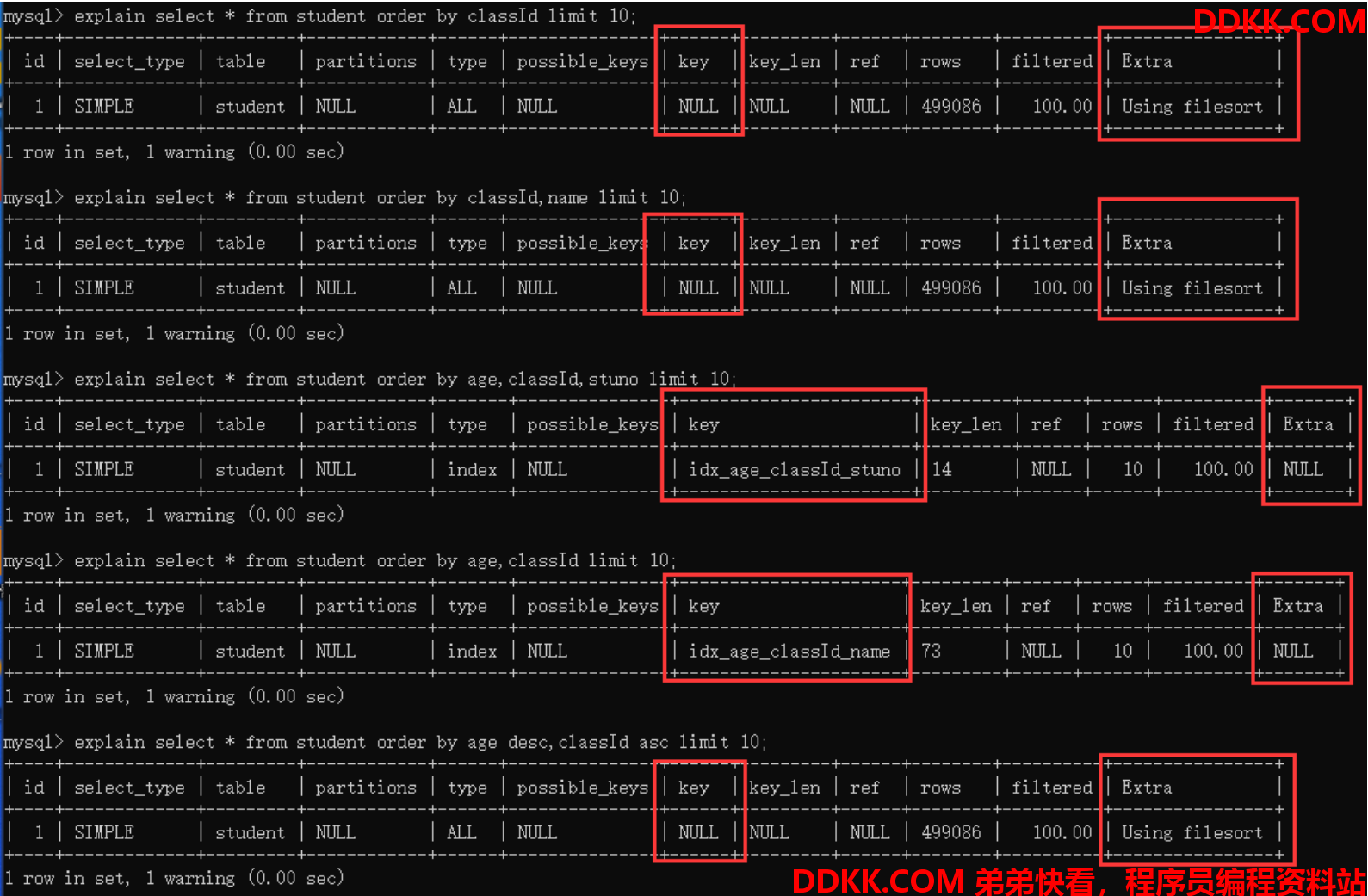
// 索引失效
// 如果使用全表扫描的方式对某个表执行查询时,执行计划的rows列就代表该表的估计行数
// 如果使用索引来执行查询,执行计划的rows列就代表预计扫描的索引记录行数
// rows的值为499086,说明该表的估计行数有499086条
// 因为回表的记录数太多,因此使用了全表扫描方式进行查询
explain select * from student where classId=45 order by age;
// limit可以限制返回的记录数,从而避免全表扫描
explain select * from student where classId=45 order by age limit 10;
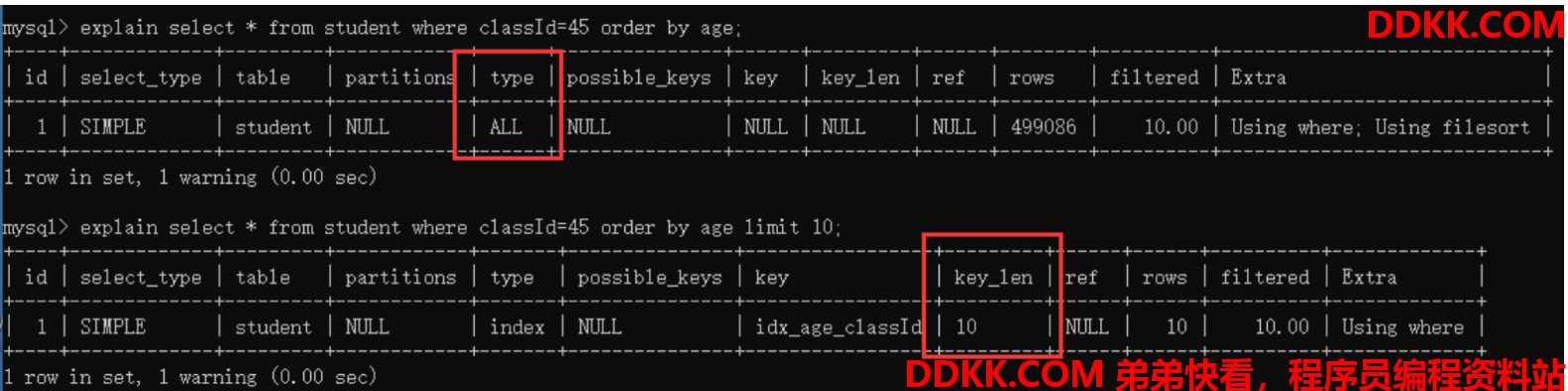
// key_len是为了让我们在使用联合索引查询时,能知道优化器具体使用了索引的多少个列的搜索条件
// key_len的值为5,说明只使用了索引的age列的搜索条件
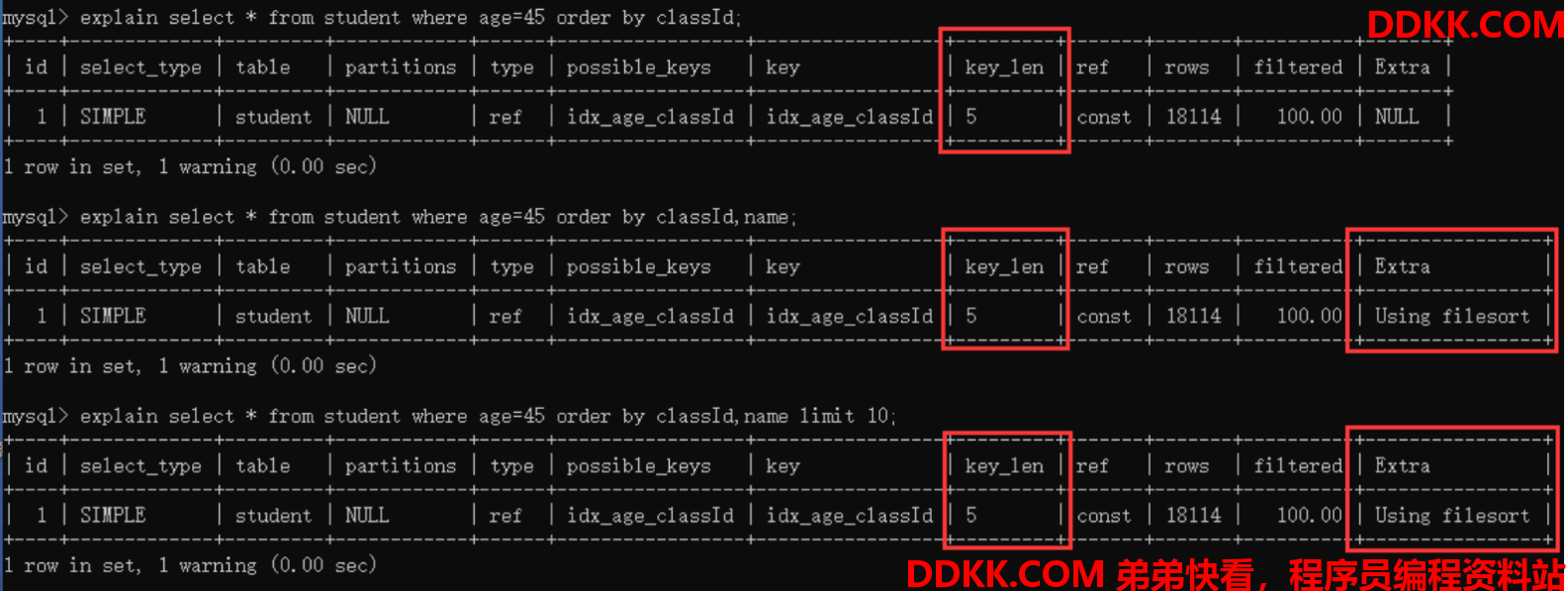
explain select * from student where age=45 order by classId;
explain select * from student where age=45 order by classId limit 10;
explain select * from student where age=45 order by classId,name;
当where和order by同时使用时,能不能使用索引列进行排序是由查询优化器决定的,因为age列使用了索引进行过滤后,返回的记录数已经很少了,可以直接在内存中对记录进行排序,说明这种成本更低。
总结:
INDEX a_b_c(a,b,c)
order by 能使用索引最左前缀
- ORDER BY a
- ORDER BY a,b
- ORDER BY a,b,c
- ORDER BY a DESC,b DESC,c DESC
如果WHERE使用索引的最左前缀定义为常量,则order by 能使用索引
- WHERE a = const ORDER BY b,c
- WHERE a = const AND b = const ORDER BY c
- WHERE a = const ORDER BY b,c
- WHERE a = const AND b > const ORDER BY b,c
不能使用索引进行排序
- ORDER BY a ASC,b DESC,c DESC /* 排序不一致 */
- WHERE g = const ORDER BY b,c /*丢失a索引*/
- WHERE a = const ORDER BY c /*丢失b索引*/
- WHERE a = const ORDER BY a,d /*d不是索引的一部分*/
- WHERE a in (...) ORDER BY b,c /*对于排序来说,多个相等条件也是范围查询*/
3. 分组(group by)优化
- 与使用B+树索引进行排序差不多,分组列的顺序页需要与索引列的顺序一致,也可以值使用索引列中左边连续的列进行分组。
- 减少使用order by,group by,distinct,这些语句较为消耗CPU,数据库的CPU资源极其宝贵
- 包含了order by,group by,distinct这些查询的语句,where条件过滤出来的结果请保持在1000行以内,否则SQL会比较慢。
4. 分页查询(limit)优化
一般分页查询时,通过创建覆盖索引能够较好的提高性能。一个常见又非常头疼的问题就是limit 2000000,10,此时需要MySQL排序前2000010记录,仅仅返回2000000-2000010的记录,其他记录丢弃,查询排序的代价非常大。

优化思路1:在索引上完成排序操作,最后根据主键关联回表查询所需要的其他列内容。
explain select * from student t,(select id from student order by id limit 2000000,10) a where t.id=a.id;

优化思路2:该方案适用于主键自增的表,可以把Limit 查询转换成某个位置的查询
EXPLAIN SELECT * FROM student WHERE id > 2000000 LIMIT 10;
