一条SQL查询语句在执行前需要确定查询执行计划,如果存在多种执行计划的话,mysql会计算每个执行计划所需要的成本,从中选择成本最小的一个作为最终执行的执行计划。如果我们想要查看某条SQL语句的查询成本,可以在执行完这条SQL语句之后,通过查看会话当中的last_query_cost变量值来得到当前查询的成本。它也是我们评价一个查询的执行效率的常用指标。这个查询成本代表执行SQL语句需要读取的页的数量。
示例1:
// 查询id=900001的记录,可以直接在聚簇索引上进行查找
select * from student_info where id=900001;
// 查看查询优化器的成本
show status like 'last_query_cost';
实际上我们只需要检索一个页即可:
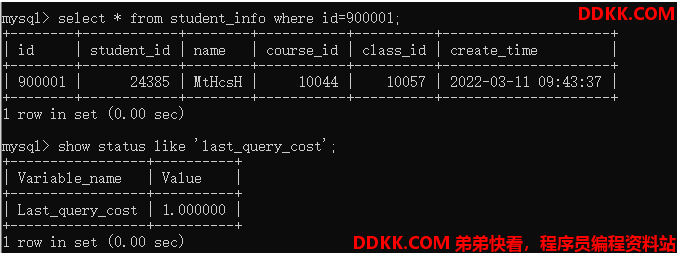
为什么只需要加载1个页?不是应该至少2个页码?很多人可能会疑惑。假如B+树有3层,那么从根节点到叶子节点,至少需要加载3个页,也就是3次IO,假如B+树有2层,那么从跟节点到叶子节点,至少需要加载2个页。那么这里为什么只需要1个页?
实际上这是InnoDB规定的,当查询走聚簇索引,并且又是精确查询的话,那么只需要一次IO操作!!!
面试题:走主键索引,假如表中有2000万个数据,你能计算出来mysql需要进行几次IO吗?1次。
// 查询 id 在 900001 到 9000100 之间的学生记录
select * from student_info where id between 900001 and 900100;
// 查看查询优化器的成本
show status like 'last_query_cost';
大概需要进行 40 个页的查询:

你能看到从磁盘加载页的数量是刚才的 40 倍,但是查询的效率并没有明显的变化,都是花费了0.00s时间,实际上这两个 SQL 查询的时间基本上一样,就是因为采用了顺序读取的方式将页面一次性加载到缓冲池中,然后再进行查找。虽然页数量增加了不少 ,但是通过缓冲池的机制,并没有增加多少查询时间 。
示例2:
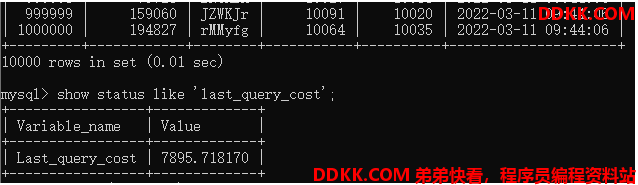
select * from student_info where id>990000;
show status like 'last_query_cost';
大概需要进行7895个页的查询,耗费时间0.01s:
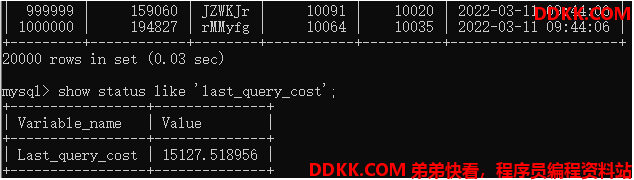
select * from student_info where id>980000;
show status like 'last_query_cost';
大概需要进行15127个页的查询,耗费时间0.03s:
使用场景:它对于比较开销是非常有用的,特别是我们有好几种查询方式可选的时候。