索引原理
索引:存储引擎用于快速查找值的数据结构
1)本质:存储引擎在索引中找到值,根据索引返回数据行或直接返回索引;
2)索引是在存储引擎层实现,所以不同存储引擎的索引工作方式不同;
3)表可拥有索引数量不受限制,但索引需占用磁盘空间和维护成本;
//过多索引还会导致每次更新数据时的性能(维护成本过高)
索引优点:
1)提高数据检索效率(目录),降低数据库的IO成本(随机IO变顺序IO);
2)减少查询中分组和排序的时间(降低CPU消耗);
3)保证表中的数据唯一性(唯一索引);
4)减少扫描数据时被锁定的数据;
5)加速表和表之间的连接;
//InnoDB访问聚簇索引使用写锁,访问二级索引使用读锁
索引缺点:
1)创建/维护索引需占用磁盘空间;
2)降低表的更新速度;
三星系统(Three-Star System):优秀的索引系统
1)将查询语句相关的索引相邻(或足够靠近);
2)索引列顺序和查询语句的排序顺序相同;
3)索引列中包含查询语句中所需的全部列;
索引基础
设计概念
MySQL中数据通过以下结构存储数据(简化版)
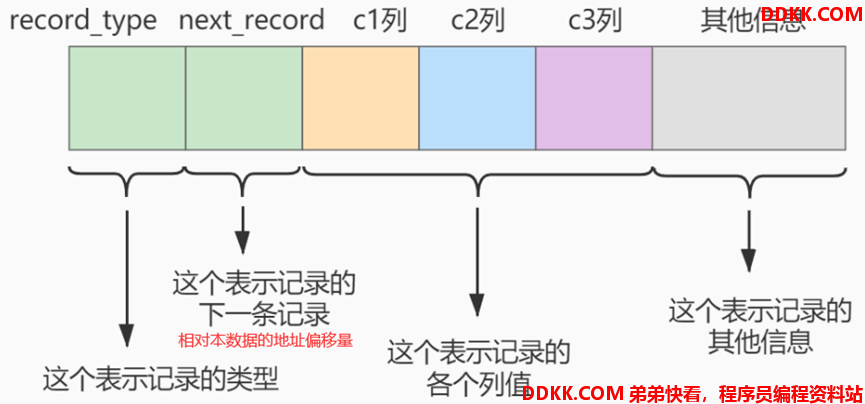
1)record_type:以不同数值表示该数据的类型
| 数值 | 含义 |
|---|---|
| 0 | 普通数据 |
| 1 | 目录数据 |
| 2 | 最小数据 |
| 3 | 最大数据 |
如:通过B+树检索数据流程
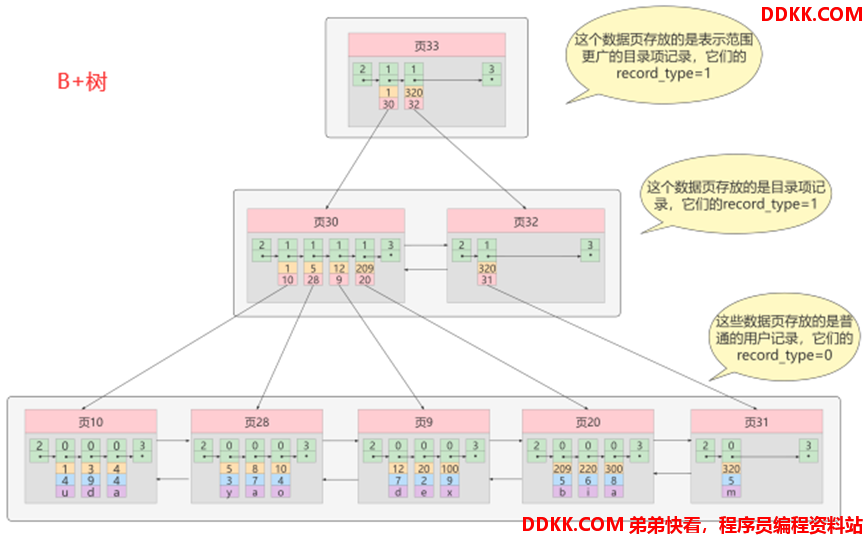
当查找数据20时,其检索路线如下:
1)确定目录项记录页为30(1 < 20 < 320);
2)确定数据项记录页为9(12 < 20 < 209);
3)遍历该页以检索到20;
B+树页面特性:
1)页内的数据按照主键排序成单向链表
2)各个数据页按照页内最小的主键排序成双向链表
3)目录页分为不同层次,相同层次的目录页根据最小的主键排序成双向链表
管理索引
创建索引分为:创建表时、后续添加
(1)创建表时创建索引
索引类型 INDEX [索引名](列1, 列N[长度N]) [ASC | DESC]
1)索引类型分为以下(不指定则默认普通索引):
| 索引类型 | 含义 |
|---|---|
| PRIMARY KEY | 主键 |
| UNIQUE | 唯一索引 |
| SPATIAL | 空间索引 |
| FULLTEXT | 全文索引 |
2)INDEX关键词和KEY关键词同理;
3)若不指定索引名,则默认以指定列组合成索引名;
4)可指定列的长度(仅为字符类型的列可被指定长度);
5)ASC和DESC指定以升序或降序的索引值存储;
//创建组合索引时不能指定索引类型(指定多个列即可)
(2)创建表后添加索引:
1)ALTER TABLE语句:
ALTER TABLE 表名
ADD 索引类型 INDEX [索引名](列1, 列N[长度N])[ASC|DESC]
2)CREATE INDEX语句
CREATE 索引类型 INDEX [索引名](列1, 列N[长度N])[ASC|DESC]
删除索引分为:ALTER语句、DROP语句
1)ALTER语句:
ALTER TABLE 表名
DROP INDEX 索引名
2)DROP语句:
DROP INDEX 索引名 ON 表名
隐藏索引:优化器不可调用该索引(使用FORCE INDEX也不可)
1)MySQL 8.X以上的版本才支持该功能;
2)实现方式:在创建/添加索引的最后处添加“INVISIBLE”关键词;
//该为“VISIBLE”关键词则为可见(默认为VISIBLE)
//索引被隐藏后仍会被维护
设计原则
适用场景
(1)具有唯一性限制的列
1)可明显提高检索速度(维护成本可忽略);
(2)频繁作为WHERE条件的列
1)不仅是查询语句的WHERE条件(UPDATE和DELETE);
(3)常用于GROUP BY和ORDER BY的列
1)仅索引列顺序和ORDER BY指定顺序且排序方向一致,才能使用索引排序
2)若查询关联多张表,仅ORDER BY指定列全为第一张表时能使用索引排序
3)其他排序需满足最左前缀从可使用索引排序
(4)常用DISTINCT去重的列
1)对去重的索引列创建普通索引即可提高检索效率;
(5)关联查询的WHERE条件和连接列
1)WHERE条件创建索引可提高对数据的过滤;
2)关联条件列需保持数据类型一致(否则导致索引失效);
不适用场景
(1)数据量小时不建议使用索引
1)优化应遵循:小全扫、中索引、大分区
(2)WHERE条件中使用不到的列
1)非绝对性,对于特殊场景仍可建立索引;
(3)大量重复数据的列
1)重复率高于10%时,就无须创建索引;
(4)频繁更新和存储无序值的列
1)维护成本过高;
(5)尽量避免重复/冗余索引(会导致DML速度降慢)
1)冗余索引:其他索引可替代的索引
2)重复索引:在相同列上按照相同顺序创建的相同类型的索引
3)MySQL唯一限制(UNIQUE)和主键限制(PRIMARY)均通过索引实现
4)查表看各索引使用频率:INFORMATION_SCHEMA.INDEX_STATISTICS
//若该表无数据,可将系统变量userstate置为1
索引类型
B-Tree
B-Tree:基于B+树存储索引
1)每次检索均从根节点开始,且每个叶子页到根的距离相同
2)每个索引都需建立个B+树,B+树的每个节点都是数据页(16KB)
3)树的深度和表的大小相关,B-Tree一般不会超过4层(足够记录数据)
//根页面位置不变,页至少存储2条数据
B-Tree适用查询:
1)全值匹配:检索数据的列均为索引列(且为精确匹配)
2)匹配范围/顺序值:B-Tree所有数据都是按顺序存储的
3)精确匹配和范围匹配混用:先精确匹配后范围匹配
4)匹配列前缀:仅使用索引列数据的前部分
5)匹配最左前缀:仅使用索引的前几列
6)仅访问索引:检索的数据同时为索引
//索引对多个值排序是依据定义表时索引列的顺序
B-Tree限制:
1)必须从最左列开始,否则索引失效;
2)不能略过索引直接调用其后续索引;
3)使用范围查询的索引列,后续列无法使用索引;
//限制均可通过更改索引列的顺序解决(定义索引时需严格考虑其顺序)
哈希
哈希:基于哈希表存储索引
1)通过所有索引列计算哈希码,将哈希码存储在索引中(索引结构十分紧凑)
2)哈希索引仅支持精确匹配(使用所有索引列的查询才有效)
3)哈希表中存储哈希码和指针的映射(指向每个数据行)
哈希索引查找流程:
1)计算数据哈希值,根据哈希值在哈希表中查找指针;
2)根据指针查找到数据行;
3)核验;
哈希限制:
1)哈希索引只包含哈希值;
2)哈希索引是无须存储的(无法用于排序);
3)当发生哈希碰撞时,存储引擎会遍历链表中所有指针;
4)哈希索引仅支持等值比较查询(不支持模糊或范围查询);
5)哈希索引不支持部分索引列匹配查找(哈希值通过全部索引列计算);
哈希碰撞:数据通过哈希函数后映射到相同位置
1)数据库通过链接法解决碰撞(将碰撞的元素放在同一链表中)
2)尽量避免哈希碰撞(选择较多的列或更复杂的哈希函数)
InnoDB不支持哈希索引,仅支持自适应哈希(Adaptive Hash Index)
1)本质:当索引值使用频繁时,在内存中基于B-Tree索引创建个哈希索引;
2)需在查询时指定哈希函数(检索时通过哈希值进行查找);
3)该功能仅由InnoDB自动实现(不可手动调用);
//当B+树比较深时,自适应哈希可明显提高效率
//建议使用自定义哈希函数(返回值为正整数以节省时间和空间)
索引策略
索引策略:通过不同标准建立适用于不同场景的索引以提高性能
聚簇索引
聚簇索引:特殊的索引数据存储方式(索引即数据)
1)表中仅能有一个聚簇索引(数据行无法存储于两个不同的位置);
2)聚簇数据能明显提高IO密集型应用的性能;
3)创建主键时会同时为其创建聚簇索引;
InnoDB要求定义的聚簇索引的表必须有主键
1)若没显示指定,MySQL会自动选择个非空且唯一标识符列为主键
2)若不存在该种列,MySQL为表生成个隐式字段作为主键(6个字节长整型)
//若无主键,建议创建代理主键(和应用无关,限制常为AUTO_INCREMENT)
//主键尽量为正整数,否则导致大量随机IO和频繁页分裂
聚簇索引的B-Tree页特性:
1)叶子节点存储数据行的全部数据(目录页只存储索引列);
2)叶子节点同时存储事物ID和MVCC的回滚指针;
优点:
1)数据访问快:索引和数据保存在同一个B+树中(索引即数据)
2)排序/范围查找快:索引默认被排序(代表数据也被排序)
3)覆盖索引扫描可直接使用页节点中的主键值;
缺点:
1)插入速度依赖于插入顺序:按主键顺序插入最快(否则可能出现页分裂)
2)二级索引访问需进行两次索引查找:查主键和根据主键查行数据
3)全表扫面变慢:行比较稀疏或页分裂导致数据存储不连续
4)更新索引列的代价高:更新会导致新的行移动
二级索引
二级索引(非聚簇索引):非主键类型的索引(普通索引)
1)二级索引的叶子节点存储的行的主键值(而非指向行的指针)
2)二级索引通常存在回表影响其性能;
//回表:根据索引查找到主键后,返回原表根据主键查找行数据
覆盖索引
覆盖索引:索引包含查询语句所需的所有列(不仅WHERE语句)
1)覆盖索引必须存储索引列的值(仅B-Tree实现);
2)覆盖索引通常会导致索引冗余
//优化器会在执行前判断索引是否全包含依次判断是否使用覆盖索引
覆盖索引的优点:
1)减少磁盘IO:只需访问内存中的缓存即可完成查询;
2)随机IO便顺序IO:利于排序/范围查询
3)避免回表:二级索引可直接返回所需数据
覆盖索引的限制:
1)索引不能过多(否则性能不如全表扫描);
2)索引中不能执行LIKE模糊查询;
多列索引
多列索引(组合索引):使用多个单列组合成索引
1)本质:同时使用多个单列索引进行检索,再将结果合并;
2)多列索引的排序顺序是根据其索引定义的顺序;
//先按照第一个索引进行排序/查找,再按照第二个索引进行排序/查找
多列索引适用场景:
1)多个单列索引联合时(常为多个OR条件);
2)多个单列索引相交时(常为多个AND条件);
//多个单列索引进行OR/AND操作时,会消耗大量系统资源
//当多个列都需创建索引时,多列索引优于单列索引
多列索引的顺序应遵循以下建议:
1)常用的列放在靠前位置(不考虑排序和分组);
2)根据运行频率高的查询语句调整索引列顺序;
前缀索引
前缀索引:仅使用数据的部分字符串作为索引
1)BLOB、TEXT和很长的VARCHAR类型的列必须使用前缀索引;
2)前缀索引需同时保证高索引选择性和较短的前缀;
索引选择性:不重复的前缀值(基数) / 数据表的记录总数(#T)
1)索引选择性越高,其查询效率也越高;
2)唯一索引的选择性是1(最好的索引选择性,性能也是最好的)
3)合适的前缀长度:用最常见的值的列和最常见的前缀列表进行比较
//索引的选择性需同时考虑最坏情况(尽量测试后再选择)
前缀索引的限制:
1)无法进行ORDER BY和GROUP BY;
2)无法做覆盖索引扫描;
索引优化
索引下推
索引下推(Index Condition Pushdown,ICP):存储引擎层优化索引方式
1)本质:存在索引列的判断条件时,同时传输该判断条件至存储引擎层;
2)ICP可显著减少存储引擎访问表和服务器从存储引擎接收数据的次数;
//在存储引擎层就对数据进行过滤(而非原本的返回数据后再过滤)
索引下推的限制:
1)ICP仅能用于二级索引;
2)覆盖索引时,ICP无法使用;
3)子查询、存储过程和触发的条件均无法下推;
索引失效
(1)未满足最左前缀(底层B+树特性)
1)指定索引的左值未确定时,索引无法使用;
(2)错误的索引使用方法
1)索引用于表达式和当作函数参数均会导致索引失效;
2)类型转换的本质也是在底层调用函数(索引当成函数参数);
(3)范围条件右侧无法使用索引
1)范围条件应尽量在最后指定(保证尽可能使用多的索引);
2)可将范围查询等价变为多个等值查询(但不可过多);
(4)不等值查询导致索引失效
1)索引默认仅支持等值查询;
(5)IS NOT NULL无法使用索引
1)可将IS NOT NULL转换为等价的IS NULL(可使用索引);
(6)左模糊或全模糊查询无法使用索引
1)左模糊或全模糊时无法确定匹配项(只能使用右模糊);
(7)OR前后存在非索引列无法使用索引
1)其可能仍需扫描全表,所以会直接扫描全表以获取数据;
(8)数据库和表的字符集未统一
1)导致数据会进行隐式转换无法使用索引;