查询优化
查询优化:通过各种方案使SQL查询更高效
1)查询优化分为:逻辑优化(重写SQL)、物理优化(索引)
2)查询优化本质:降低查询语句所需的开销
查询开销指标:响应时间、扫描行数、返回行数
1)响应时间:排队时间和执行时间
2)扫描行数:为完成查询扫描数据行的总数
3)返回行数:真实返回数据行的总数
//尽量使返回行数接近于扫描行数,且行的访问代价并不一定相等
查询开销高的基本原因是:访问数据过多
1)重写查询:使用更优化的查询语句;
2)覆盖索引:将使用的列均设为索引,以避免回表;
3)修改表结构:修改表结构以增高查询效率(或添加辅助表);
查询流程
查询流程:客户端与MySQL服务器连接后,查询语句的执行流程
查询流程如下:
1)客户端发送查询语句请求至MySQL服务器;
2)检查是否命中缓存,命中则直接返回结果并结束查询;
3)对查询语句进行语法和语义分析,并解析成解析树并传递给预处理器优化;
4)优化器根据解析树生成优化后的执行计划,并传递给查询执行引擎;
5)查询执行引擎调用存储引擎API执行查询,并返回结果;
//MySQL 8.0之后的版本删除命中缓存查询(功能过于鸡肋)
如:MySQL服务器接收到客户端查询语句请求后的流程
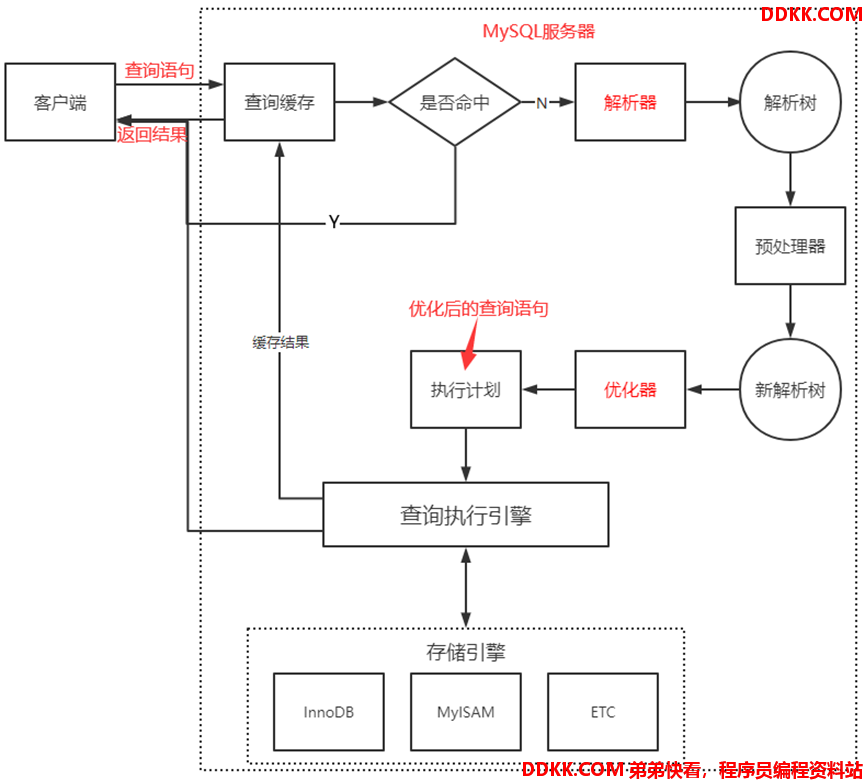
//实际查询流程中可能并不按此线性流程执行(可能部分模块同时执行)
MySQL客户端和服务器之间通信协议为半双工
1)客户端只能用单个数据包将查询语句传递给服务器;
2)服务器用多个数据包将结果返回给客户端,且客户端必须完整接收结果;
//在客户端接收结果时,MySQL会对所有查询所使用的资源上锁
MySQL客户端通过线程连接服务器,服务器每刻都处于以下状态之一:
| 线程状态 | 说明 |
|---|---|
| Sleep | 等待客户端请求 |
| Query | 正在执行查询 正在将结果发送给客户端 |
| Locked | 等待锁 (锁的类型由存储引擎决定) |
| Analyzing and statistics | 生成查询执行计划 (根据存储引擎统计信息) |
| Copying to tmp table [on disk] | 正在执行查询 并将结果集复制到临时表 |
| Sorting result | 正在对结果集进行排序 |
| Sending data | 正在传送数据 正在生成结果集 正在将结果发送给客户端 |
查询缓存
查询缓存(Query Cache):将查询结果缓存并在其他查询流程开始前检测
1)查询缓存会在不同客户端之间共享;
2)本质:基于对大小写敏感的哈希查找实现;
3)查询命中查询缓存会直接返回缓存,但会再检查次用户权限;
//MySQL 8.X删除查询缓存(功能过于鸡肋)
查询缓存限制(失效):
1)查询语句必须完全相同:包括注释、大小写和空格数量;
2)不能包含函数和变量:无法确定其结果;
3)不适用频繁更新的表:缓存命中率较低;
解析器
解析器(Parser):通过关键词对查询语句进行语法/语义分析以生成解析树
1)语法分析:根据MySQL语法规则检测查询语句是否合法;
2)语义分析:根据MySQL关键词分析查询语句的语法;
3)解析树:承载查询语句以便后续优化和执行
预处理器会根据解析树做进一步处理:
1)预处理器根据MySQL规则检测解析树是否合法,并进行优化;
2)预处理器再次检测用户权限;
优化器
优化器(Optimizer):根据解析树生成执行计划
1)生成执行计划的同时会优化执行语句(逻辑优化,保证成本最小)
2)优化器决定的执行计划未必是最优的(优化器存在误判)
3)优化器分为:静态优化(编译时)、动态优化(运行时)
//SHOW STATUS LIKE ‘Last_query_cost’;可查最后一次查询成本
//优化器的估计成本并不一定是实际执行成本
优化器在以下情况会误判查询成本:
1)存在缓存:优化器不考虑任何层面的缓存;
2)并发查询:优化器不考虑任何并发执行的查询;
3)乐观评估:优化器不考虑任何不受控制的操作成本
4)统计信息不准确:优化器依靠存储引擎统计信息评估各查询成本;
常用场景
(1)重定义表的关联顺序
1)场景:表的实际关联顺序并总是按照查询语句指定的顺序进行;
2)优化:优化器会选择小表作为驱动表(减少外层循环次数);
(2)外连接变为内连接
1)场景:外连接并不总是按查询语句指定的方式连接;
2)优化:优化器会尽量使用内连接代替外连接,并优化内连接顺序;
(3)简化并规范表达式
1)场景:查询语句的表达式不简化和规范时
2)优化:优化器会使用等价的简化且规范表达式替换查询语句的表达式;
(4)转化为常数
1)场景:将查询语句中部分转化为常数
2)优化:优化器检测查询语句中表达式和语句是否可转换为常数;
(5)覆盖索引
1)场景:判断是否可调用覆盖索引
2)优化:优化器判断当前查询语句的列是否被索引列包含;
(6)转化子查询
1)场景:子查询并不总按照子查询方式进行
2)优化:优化器常使用等价的关联查询替代子查询
//子查询使用临时表存储数据,但临时表无法创建/使用索引(成本高)
(7)提前终止查询
1)场景:查询能提前终止
2)优化:优化器发现满足查询语句需求时,可立刻终止查询
(8)等值传播
1)场景:关联查询时列可互相获得对方WHERE条件
2)优化:优化器在等值关联时,将列的WHERE条件传递给其他列
HINT
优化器提示(HINT):控制优化器是否启用部分功能
(1)HIGH_PRIORITY和LOW_PRIORITY
1)功能:指定语句的优先级(仅对使用表锁的存储引擎)
2)可用于SELECT、INSERT、UPDATE和DELETE语句
(2)DELAYED
1)功能:结果立刻返回客户端,将插入放入缓冲区(表空闲时再插入)
2)可用于INSERT和REPLACE语句
//会导致LAST_INSERT_ID()函数失效
(3)STRAIGHT_JOIN
1)功能1:查询语句中表只按照指定顺序关联(用于SELECT)
2)功能2:表的关联顺序不用被优化(用于JOIN)
3)可用于:SELECT和JOIN语句
(4)SQL_SMALL_RESULT和SQL_BIG_RESULT
1)功能:告知优化器是否将结果集放在内存的临时表中
2)可用于SELECT语句
(5)SQL_BUFFER_RESULT
1)功能:将结果集放入到内存的临时中再返回至客户端(尽快释放锁)
2)可用于SELECT语句
(6)SQL_CACHE和SQL_NO_CACHE
1)功能:是否将结果存储至查询缓存
2)可用于SELECT语句
(7)SQL_CALC_FOUND_ROWS
1)功能:使结果集尽可能包含更多的信息
2)可用于SELECT语句
(8)IGNORE INDEX和FORCE INDEX
1)功能:强制使用/不适用索引
2)可用于FROM语句
性能分析
EXPLAIN
EXPLAIN:分析指定语句以返回其执行计划
1)仅模拟执行指定语句,并非实际执行;
2)EXPLAIN不考虑缓存、优化器、触发器和存储过程的存在;
EXPLAIN分析格式:EXPLAIN 执行语句\G
1)也可使用“;”作为结束符,但\G增加可读性;
2)可在EXPLAIN后指定“FROMAT=JSON”获取更多信息;
分析返回的分析数据字段含义如下:
| 字段 | 含义 |
|---|---|
| id | 执行语句的唯一ID |
| select_type | 查询类型 |
| table | 作用于的表名 |
| partitions | 匹配的分区信息 |
| type | 针对单表的访问方法 |
| possible_keys | 可能使用的索引 |
| key | 实际使用的索引 |
| key_len | 实际使用的索引长度 |
| ref | 与索引进行等值匹配的对象信息 |
| rows | 估计读取的记录条数 |
| filtered | 条件过滤剩余数据的百分比 |
| Extra | 额外信息 |
(1)id:执行语句的唯一ID
1)若id相同则为同组,且执行顺序从上往下;
2)不同组中,id值越大其执行越优先;
//id应尽量少,代替其执行次数少
(2)select_type:查询类型
| 查询类型 | 说明 |
|---|---|
| SIMPLE | 简单查询 (未使用UNION) |
| PRIMARY | 外层查询 |
| UNION RESULT | 结果集用于联结 |
| UNION | UNION的结果集 |
| DEPENDENT UNION | 依赖其他查询的延迟查询 |
| UNCACHEABLE UNION | 延迟查询且不缓存 |
| SUBQUERY | 子查询中首查询 |
| DEPENDENT SUBQUERY | 子查询中延迟查询 (依赖于其他查询) |
| UNCACHEABLE SUBQUERY | 子查询且不缓存 |
| DERIVED | 临时表查询 |
| MATERIALIZED | IN条件的子查询 |
(3)table/type:作用于的表明、针对单表的访问方法
1)无论执行语句中包含多少表,其最终都为对单表的访问;
2)访问方法有以下12种(性能依次降低):
| 访问方法 | 含义 |
|---|---|
| system | 系统数据 (常通过内存获取) |
| const | 常量数据 |
| eq_ref | 主键或非空唯一索引等值扫描 |
| ref | 非主键且非唯一的等值扫描 |
| fulltext | 全文索引扫描 |
| ref_or_null | 主键或唯一索引等值扫描 |
| index_merge | 合并索引扫描 |
| unique_subquery | 唯一索引子查询 |
| index_subquery | 索引子查询 |
| range | 范围扫描 |
| index | 索引树扫描 |
| ALL | 全表扫描 |
(4)Extra:额外信息
| 额外信息 | 说明 |
|---|---|
| Using filesort | 数据进行文件排序(FileSort) |
| Using temporary | 使用临时表存储中间结果 |
| Using where | 使用WHERE过滤数据 |
| Using index | 使用覆盖索引 |
| Using index condition | 部分数据命中索引进行IPC |
| NOT EXISTS | NOT EXISTS替代IS NULL |
| Zero limit | LIMIT 0时 |
| Using join buffer(Block Nested Loop) | 子或关联查询时使用缓存优化 |
PROFILE
PROFILE:将MySQL上所有的执行语句相关信息记录到临时表
1)临时表按照执行顺序排序存储各个执行语句;
1)开启PROFILE记录(默认关闭):SET profiling='ON';
//可查询该变量验证是否开启
2)查看PROFILE记录:SHOW profiles;
//默认仅返回所有执行语句的总开销
3)查看最近一次查询的各个阶段的开销:SHOW profile 资源;
| 资源 | 说明 |
|---|---|
| ALL | 全部显示 |
| CPU | 仅显示CPU相关 |
| IPC | 仅显示接收/发送数据 |
| SWAPS | 仅限交换次数 |
| MEMORY | 仅显示内存 |
| BLOCK IO | 仅显示IO |
| PAGE FAULTS | 仅显示页面错误 |
| CONTEXT SWITCHES | 仅显示上下文切换 |
//若省略资源,则仅显示各个阶段的总开销
//可在最后添加“FOR QUERY 数值N”以显示多个查询开销
慢查询
慢查询:将执行超过指定时间的操作记录到日志文件
1)慢查询日志的开销可忽略不计,但长期开启需部署日志轮转工具;
常用命令如下:
1)开启慢查询(默认关闭,临时)
SET GLOBAL slow_query_log='ON';
//也可通过修改配置文件slow_query_log实现永久开启
2)指定慢查询限定时间为N秒(可为小数)
SET GLOBAL long_query_time=数值N
//查看该变量可得知慢查询限定时间(默认10秒)
3)指定慢查询日志文件路径
SET GLOBAL long_query_time=数值N
//查看该变量可得知慢查询日志文件路径
4)返回已记录慢查询总数
SHOW STATUS LIKE 'slow_queries';
5)记录未使用索引的查询
SET GLOBAL log_queries_not_using_indexes='ON';
mysqldumpslow命令:分支慢查询日志文件
指令格式:mysqldumpslow 选项 慢查询日志文件路径
| 选项 | 含义 |
|---|---|
| -s | 以指定方式排序慢查询 |
| -t N | 返回前N条慢查询 |
| -g 正则表达式 | 正则表达式匹配含特定关键词的慢查询 |
-s选项有以下种排序方式:
| 排序方式 | 说明 |
|---|---|
| c | 访问次数 |
| l | 锁定时间 |
| r | 返回记录 |
| t | 查询时间 |
| al | 平均锁定时间 |
| ar | 平均返回记录数 |
| at | 平均查询时间 (默认方式) |
| ac | 平均查询次数 |
优化方案
关联优化
关联查询的执行流程:
1)先在一个表中循环取出单条数据;
2)使用该单条数据到下个表中寻找匹配的数据行(嵌套循环执行该步骤);
3)根据各个表匹配的数据行,返回查询语句中所需的列;
4)在最后一个表中找所有匹配的数据行(找到则结束);
5)依次返回上层表尝试找到更多匹配的数据行;
尽量避免使用关联查询,单表查询获取结果集后在应用层中再进行关联
1)高扩展:更易对数据库做拆分
2)查询效率高:单表查询效率远高于关联查询
3)减少锁竞争:单表查询对锁的持有时间很短;
4)缓存效率高:避免部分表发生更新时缓存的失效;
5)减少冗余查询:应用层再关联可避免重复访问数据;
6)易实现哈希关联:避免使用MySQL的嵌套循环关联;
关联查询优化方案:
(1)左外连接时应选择小表作为驱动表,大表作为被驱动表
1)原因:减少外层循环次数
2)MySQL底层将所有右外连接改为等价的左外连接执行
(2)内连接时会自动将小结果集的表选为驱动表
1)原因:减少外层循环次数
(3)用含索引的字段作为连接字段
1)原因:保证数据检索时可使用索引
2)常在关联顺序中的第二个表的列上创建索引
(4)GROUP BY和ORDER BY语句只涉及一个表中的列
1)原因:保证可使用索引
排序优化
尽量避免进行排序(或避免对大量数据进行排序)
1)大量数据排序常会导致索引失效,只能进行FileSort
2)常需排序的数据可使用索引进行存储
FileSort:在磁盘中对数据进行排序
1)FileSort的排序方式分为:双路排序、单路排序
2)MySQL默认的排序方式为内存排序(只能用于小数据)
双路排序(慢):随机IO(两次IO)
1)扫描磁盘获取指针和ORDER BY列,并进行排序
2)根据排序结果集再次扫描磁盘获取数据
单路排序(快):顺序IO(一次IO)
1)从磁盘中读取所有列到内存中
2)根据ORDER BY列进行排序,依次输出数据;
排序优化方案:
(1)使用索引排序
1)避免WHERE语句使用全表扫描
2)避免ORDER BY语句使用FileSort排序
3)无法使用索引排序时,也需对FileSort调优
//提高sort_buffer_size和max_length_for_sort_data
(2)WHERE和ORDER BY使用的列相同时
1)使用单列索引(反之,多列索引)
(3)关联查询排序时避免ORDER BY语句的列全部来自第一个表
1)全部来自第一个表时,会在处理第一个表就进行FileSort
2)默认关联结果存储至临时表中,最后进行FileSort
//关联查询进行排序时无法使用索引排序(关联结果在临时表中)
其他优化
(1)查询仅返回需要的列
1)原因:避免返回全部列(无法使用覆盖索引)
2)强烈建议禁止SELECT *
(2)将重复查询的数据添加至缓存
1)原因:避免重复多次进行相同查询流程
(3)选择WHERE而非HAVING
1)原因:WHERE效率远高于HAVING
(4)WHERE条件中使用EXISTS()代替IN()进行子查询
1)原因:每增加一个IN()条件,优化器需做的组合将以指数形式增加
(5)UNION连接需排序/过滤时,先排序/过滤再合并
1)原因:合并使用的临时表无法使用索引(效率低)
(6)尽量使用UNION ALL进行关联
1)原因:对临时表做唯一性限制的代价过高
(7)GROUP BY语句避免WITH ROLLUP进行汇总
1)原因:导致使用FileSort或临时表(无法使用索引优化)
2)尽可能在应用层使用对结果集的汇总
(8)常用LIMIT语句限制返回数据
1)避免返回数据中过多无用数据和减少扫描的数据行
(9)关联查询代替子查询
1)原因:子查询使用临时表存储数据,但临时表无法创建/使用索引
//子查询可完成逻辑尚多个步骤的操作,但效率较低(避免使用)
(10)返回结果中只有一个表中的列时才使用关联子查询
1)原因:关联子查询的成本较高,只在特殊情况下使用;
(11)将大的DELETE语句切分成多个较小的
1)原因:尽可能较小地影响MySQL性能,同时减少MySQL复制的延迟
//且每次删除后暂停段时间(减少删除时锁的持有时间)