事务原理
事务:数据库操作的最小原子单位
1)通过ACID测试的处理系统才可称为事务(独立的工作单元):
| 要素 | 说明 |
|---|---|
| 原子性 (Atomicity) | 事务必须被视为一个不可分割的最小工作单元 (要么全部提交,要么全部失败回滚) |
| 一致性 (Consistency) | 数据库总从一个一致性状态转换到另一个一致性状态 |
| 隔离性 (Isolation) | 一个事务所作的修改在最终提交前,其他事务不可干预 |
| 持久性 (Durability) | 事务提交后,其所作的修改会永久保存至数据库 |
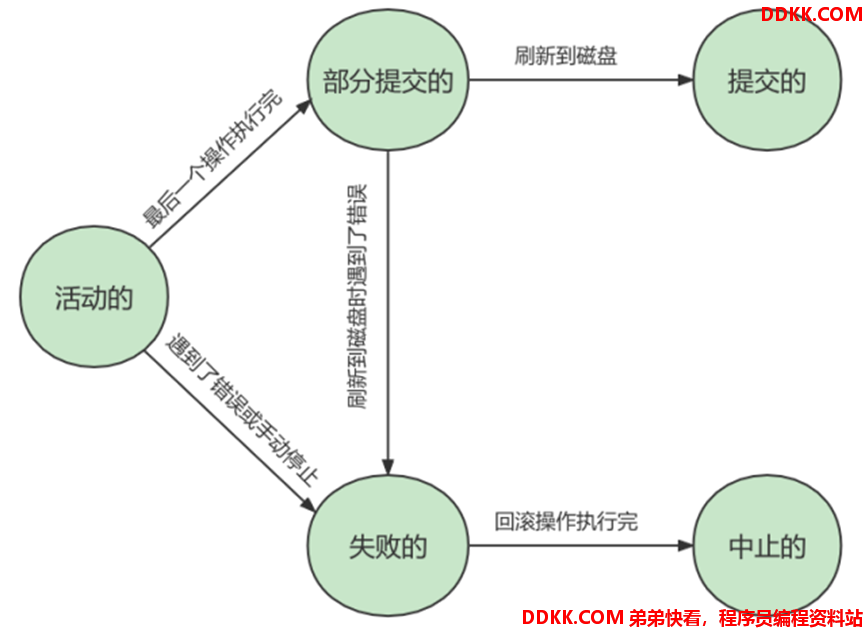
事务状态有以下5种:
1)活动(Active):事务对应的数据操作正在执行过程中;
2)部分提交(Partially Committed):事务提交并执行后,未全刷新到磁盘;
3)失败(Failed):事务无法继续,或人为停止事务;
4)中止(Aborted):撤销事务执行的操作(回滚);
5)提交(Committed):事务提交并执行后,且全部刷新到磁盘;
如:事务状态之间相互转换的关系
隔离级别
隔离级别:解决事务并发问题
1)查看当前隔离级别:SELECT @@transaction_isolation;
2)设置隔离级别:SET GLOBAL TRANSACTION_ISOLATION=‘隔离级别’;
//可将GLOBAL替换为SESSION(仅限制当前会话的隔离级别)
//新设置的隔离界别仅对于后续开启事务的影响(正在进行的无效)
(1)未提交读:READ-UNCOMMITTED
1)说明:事务中的修改在未提交时,对其他事务也是可见的;
(2)提交读:READ-COMMITTED
1)说明:事务从开始到提交前,所作的任何修改对其他事务均不可见;
2)且每个事务只能看到已提交过的事务的影响;
(3)可重复读:REPEATABLE-READ
1)说明:事务多次读取同样记录的结果是一致的;
2)MySQL默认的事务隔离级别
(4)串行化:SERIALIZABLE
1)说明:强制事务串行执行(最高隔离级别,无并发性);
2)SERIALIZABLE会在读取的每一行数据上都加锁;
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 加锁读 |
|---|---|---|---|---|
| READ-UNCOMMITTED | Y | Y | Y | N |
| READ-COMMITTED | N | Y | Y | N |
| REPEATABLE-READ | N | N | Y | N |
| SERIALIZABLE | N | N | N | Y |
//MySQL在可重复读的隔离界别下就解决的幻读(基于MVCC实现)
事务并发问题(以同时进行的事务A和事务B进行举例)
1)脏写(Dirty Write):事务A修改未提交事务B的数据
2)脏读(Dirty Read):事务A读取未提交事务B的数据
3)不可重复度(Non-Repeatable Read):事务A多次相同读取返回不同数据
4)幻读(Phantom):事务A多次相同读取时,数据发生新增/删除的变化
事务日志
Redo
Redo(重做日志):记录数据库物理级别的页修改操作
1)作用:事务的持久性、降低刷盘频率
2)Redo由存储引擎层实现和产生
//数据与依赖于WAL技术实现事务的持久性和低刷盘
WAL(Write-Ahead Logging):先写Redo,后刷盘
1)Redo写入成功就代表事务提交成功;
2)事务中每执行条语句就可能产生若干条Redo,而Redo按产生顺序刷盘;
实现原理
Redo的由两部分组成:
(1)重做日志的缓冲(Redo Log Buffer)
1)存储于内存中,默认16M(数据库启动时回申请大片连续内存空间作为)
2)Redo Log Buffer由多个Redo Log Block构成(每个为512字节)
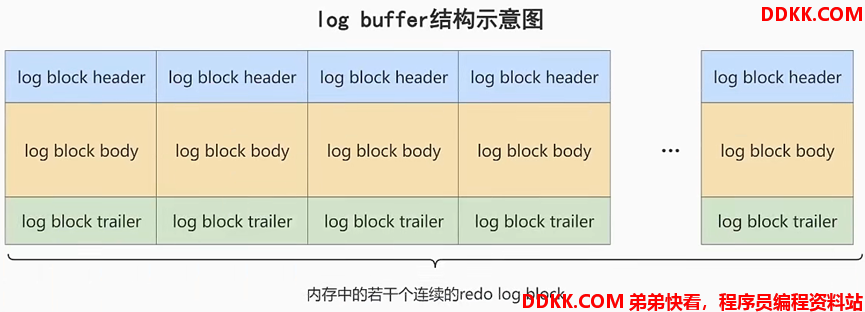
//可通过“innodb_log_buffer_size”设置Redo Log Buffer(最大4096,最小1)
(2)重做日志文件(Redo Log File)
1)存储于磁盘中,默认命名格式“ib_logfile数字”
//数字默认从0开始,每增加个重做日志文件就增大次
如:当事务提交后生成Redo的流程
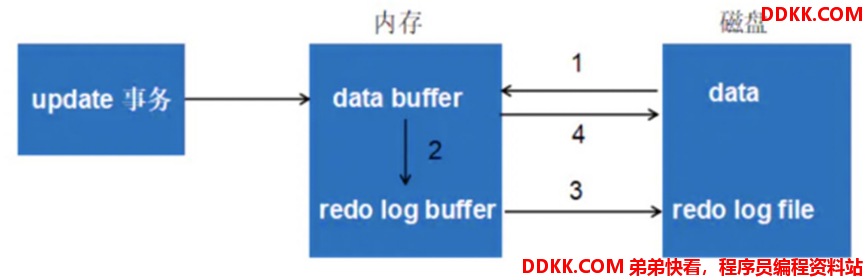
1)从磁盘中读取数据库数据至内存中,并修改数据的内存拷贝;
2)生成条Redo并写入Redo Log Buffer(记录数据修改后的值);
3)事务提交后根据刷盘策略将Redo Log Buffer以追加形式写入Redo Log File;
4)按刷盘策略将内存中修改的数据刷新到磁盘中;
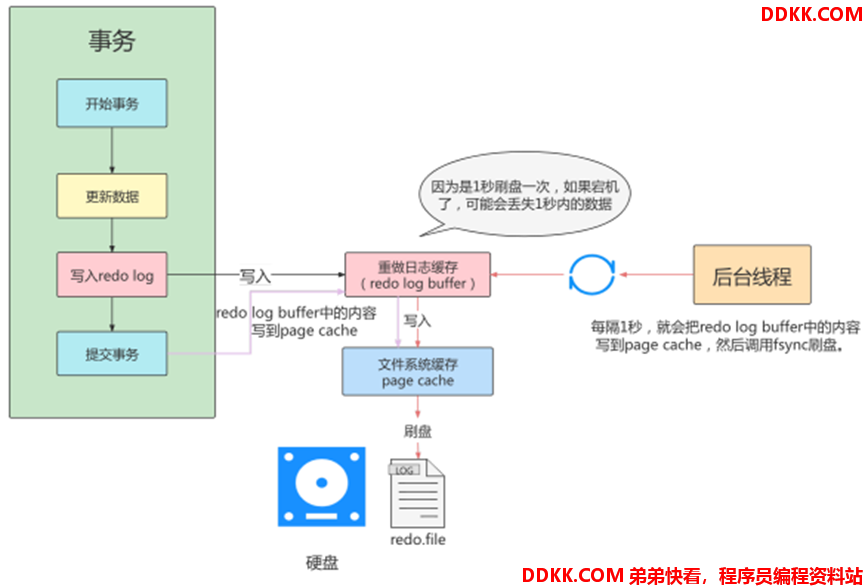
刷盘策略:Redo Log Bufer写入磁盘的方式和时间
1)由参数“innodb_flush_log_at_trx_commit”控制,支持以下3种策略:
| 策略 | 说明 |
|---|---|
| 0 | 每次事务提交后交由后台线程管理 (默认Master Thread每隔1s进行次刷盘) |
| 1 | 每次事务提交后立刻进行刷盘操作 (默认值) |
| 2 | 每次事务提交先将Redo Log Buffer写入Page Cache 由OS决定何时将Page Cache刷盘 |
策略0:效率和持久性间于策略1和策略2(可能存在丢失1秒事务)
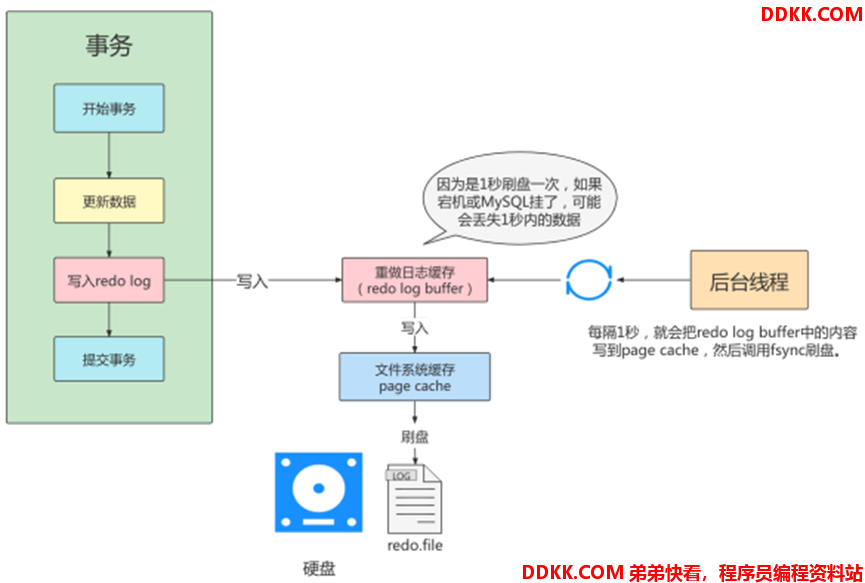
策略1:最高成度保证事务的持久性(事务提交后,Redo就记录在硬盘中)
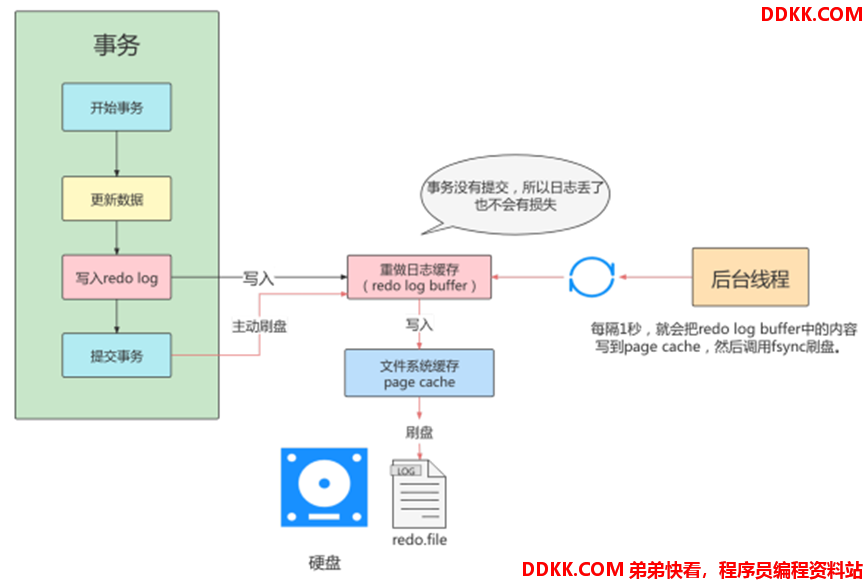
策略2:效率最高(系统宕机时可能存在丢失1秒内的数据)
Redo Log File相关参数:
| 参数 | 配置 |
|---|---|
| innodb_log_group_home_dir | 指定Redo Log File的存储路径 (默认值为数据库的数据目录) |
| innodb_log_files_in_group | 指定Redo Log File的个数 (默认2个,最大100个) |
| innodb_log_file_size | 指定单个Redo Log File的文件大小 (默认值48M) |
1)数据库的数据目录为:var/lib/mysql
2)所有Redo Log File文件大小的总和大小不能超过512G
3)当最后一个Redo Log File写满时,会重新从首个Redo Log File进行写
4)checkpoint机制:数据库会自动清空已加载的Redo,防止进行覆盖写
//数据库还会阻塞服务以加载和清空Redo,以防止覆盖写
Undo
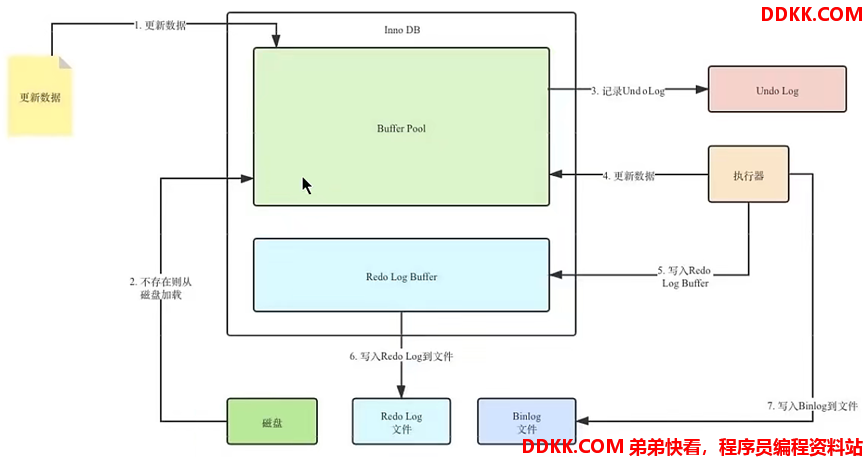
Undo(回滚日志):记录数据库逻辑相反的操作
1)作用:事务的原子性、一致性非锁定读(MVCC)
2)Undo由存储引擎层实现和产生
3)不会对查询语句进行记录
4)Undo会导致Redo的产生
事务提交后不会立刻删除Undo
1)原因:可能存在其他事务通过Undo读取之前版本的数据
2)处理方式:将Undo放入链表中,由Undo所在页的Purge线程管理
//INSET相关语句可直接删除(其仅能由本事务可见,其他事务不可见)
如:开启Undo后数据库的部分语句执行流程
实现原理
回滚段(Rollback Segment):InnoDB管理Undo的方式
1)每个回滚段记录1024个Undo Log Segment(且在其中进行Undo页申请);
2)Undo页:记录Undo的最小单位(默认16K,且可被重用)
3)若Undo页的3/4未使用,则该Undo页会被重用(不回收)
回滚段须知:
1)事务进行时对数据进行修改,会将所有原生数据记录到回滚段;
2)每个事务仅能使用一个回滚段,但一个回滚段可服务于多个事务;
3)回滚段中事务会不断填充其所属磁盘,直到事务结束或无可用空间;
4)回滚段存储于Undo表空间中,数据库可同时存在多个Undo表空间;
//同一时刻只能使用一个Undo表空间(最少存在2个Undo表空间)
每行数据除数据本身外,还存在以下3个隐藏列(实现Undo):
1)DB_ROW_ID:当不存在显示主键或唯一索引时,自动添加的隐藏主键;
2)DB_TRX_ID:每个事务都具有的事务ID(数据被改变时记录该ID);
3)DB_ROLL_PTR:回滚指针(指向特定Undo的指针);
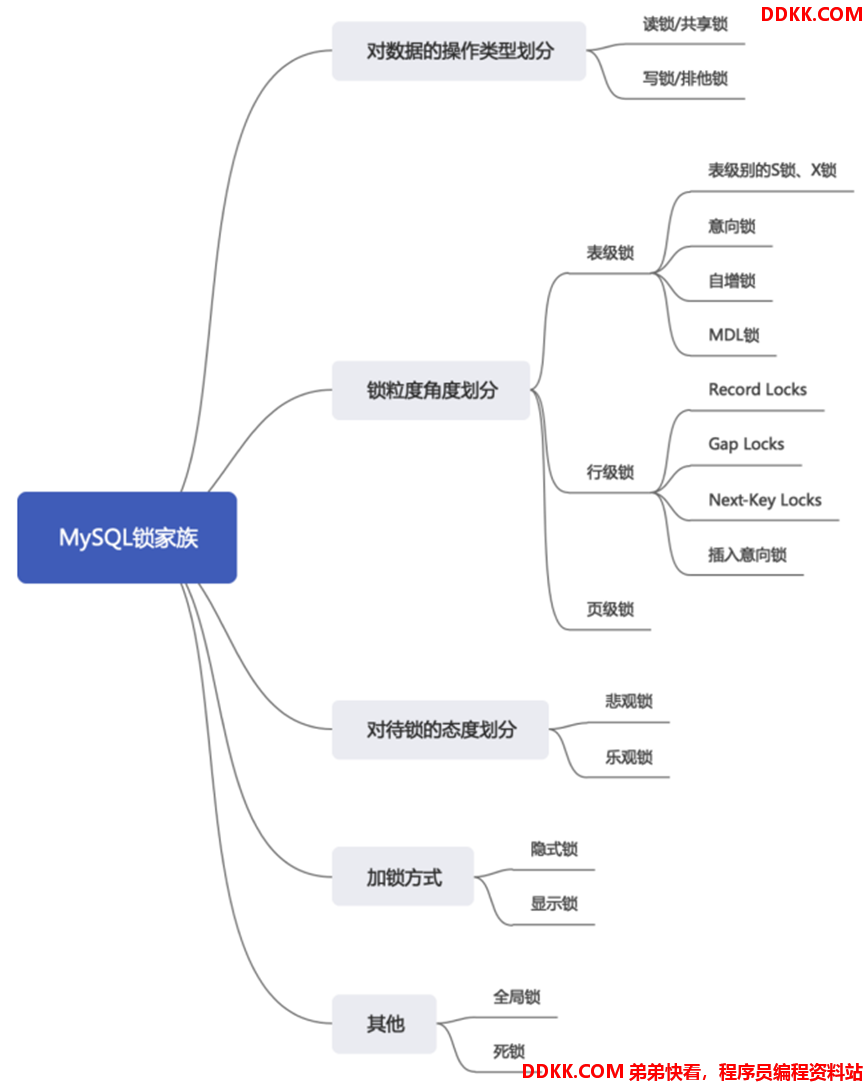
数据锁
数据锁:保证数据的完整性和一致性的前提下,提高数据的并发能力
1)数据锁为隔离界别的实现的基础;
2)数据锁的范围越小越好(最大程度提高并发);
3)常用MVCC提供数据并发,但部分场景下仅能由数据锁提供;
通过数据库的环境变量“innodb_row_lock”可观察数据锁的争夺情况:

1)Innodb_row_lock_current_waits:正在等待锁释放的语句数量;
2)Innodb_row_lock_time:从数据库启动到现在锁的总时间;
3)Innodb_row_lock_time_avg:每次锁等待的平均时间;
4)Innodb_row_lock_time_max:锁等待最长的时间;
5)Innodb_row_lock_waits:锁总共等待的次数;
如:数据库中不同数据锁的分类
1)使用悲观锁时必须使用索引,否则会进行全表扫描进而导致上升为表级锁;
2)全局锁通过命令“FLUSH TABLES WITH READ LOCK”(全部仅可读);
3)发生死锁时,InnoDB将选择Undo最小的事务进行回滚;
4)为避免发生死锁现象,应尽量避免显示加锁;
//合理设计索引、优化SQL执行顺序和降低隔离级别等均能有效减少死锁现象
(1)读锁(共享锁,S):多个事务可同时处理同一数据,且不互相影响/阻塞
1)SELECT语句后加“LOCK IN SHARE MODE”即可加S锁
2)加锁后无法获取锁的事务会阻塞指定时间等待(超时后返回失败)
3)MySQL8.0可设置无锁时直接返回:NOWAIT 或SKIP LOCKED
//NOWAIT会立即报错返回,SKIP LOCKED返回的结果集中无加锁的行
(2)写锁(互斥锁,X):数据在特定时间内仅能由持有X锁的事务处理
1)SELECT语句后加“FOR UPDATE”即可加X锁
2)加锁后无法获取锁的事务会阻塞指定时间等待(超时后返回失败)
3)MySQL8.0可设置跳过等待锁时间:NOWAIT或 SKIP LOCKED
//NOWAIT会立即报错返回,SKIP LOCKED返回的结果集中无加锁的行
//加X锁的查询语句可有效解决脏读、不可重复和幻读
| S锁 | X锁 | |
|---|---|---|
| S锁 | 兼容 | 不兼容 |
| X锁 | 不兼容 | 不兼容 |
//不论任何其他粒度/方式的锁在进行加锁时,均通过以上两种方式
表级锁
表级锁:锁定事务相关的所有表
1)MySQL中基础锁策略,且不依赖于存储引擎;
2)表锁的开销最小,但争用率较大(锁粒度越小,其开销越大);
普通表级锁上锁方式:
1)显式上锁:LOCK TABLES 表名 锁类型;
3)显示释放锁:UNLOCK TABLES 表名;
3)隐式上锁:服务器在查询过程中会隐式地锁住表(隐式锁会相互阻塞)
IS/IX锁
IS/IX锁:用户手动锁定表的方式
1)通常不会使用表级的IS/IX锁(崩溃恢复时会使用);
2)应尽量避免使用表级的IS/IX锁,而选择行级的IS/IX锁(提高并发度);
3)InnoDB不会自动为任何表添加IS/IX锁(MyISAM查询时自动添加IS锁);
表加S锁:LOCK TABLES 表名 READ
表加X锁:LOCK TABLES 表名 WRITE
意向锁
意向锁(Intention Lock):协调表级锁和行级锁之间的关系
1)InnoDB默认支持多粒度锁(Multiple Granularity Locking):表/行级锁共存;
2)意向锁虽然是表级锁,但其不与行级锁冲突(但与表级的IS/IX锁冲突);
3)作用:表明事务对表中的部分行有意向去加S/X锁;
4)意向锁由存储引擎管理和维护(无法手动锁定);
//意向锁中也存在S锁和X锁(IS锁和S锁兼容)
意向锁可有效减少事务对锁检查的次数,如:
1)当事务A对某行数据添加X锁时,存储引擎会自动在表级上加意向X锁;
2)当事务B需获取该表的表级X锁时,无须检查每行数据的锁;
3)事务B通过意向锁即可得知该表中是否有行被加X锁;
//每次进行加锁操作时,存储引擎都会在该锁的更高一层级上添加对应的意向锁
自增锁
自增锁(AUTO-INC):维护具有自增约束的字段在插入数据时的正确性
1)自增锁的插入模式分为:简单插入、批量插入、混合插入
2)通过“innodb_autoinc_lock_mode”参数指定自增锁的插入模式
自增锁的插入模式区别:
(1)简单插入(Simple Inserts,参数为0)
1)INSERT语句执行前会获得自增锁;
(2)批量插入(Bulk Insets,参数为1)
1)INSET…SELECT和REPLACE…SELECT语句执行前会获得自增锁;
2)分配时间内仅能由一个语句持有自增锁(无法确定插入行数);
3)自增锁会在确定插入行数后立刻释放(非语句执行完);
4)MySQL 8.0之前默认模式(可能导致Binlog不安全);
(3)混合插入(Mixed-mode Inserts)
1)INSERT语句中部分指定数据,其他数据由自增锁添加;
2)能够保证在并发执行时都会获得唯一且单调递增值;
3)MySQL 8.0之后默认模式(可能递增存在间隙);
元数据锁
元数据锁(Metadata Locks,MDL):保证事务执行时,表结构不会发生改变
1)作用:对表CURD时加MDL的S锁,改变表结构时加MDL的X锁;
2)MDL的S锁之间不互斥,但MDL的X锁之间且和S锁互斥;
3)MDL锁由存储引擎管理和维护(无法手动锁定);
行级锁
行锁(Row Lock,记录锁):仅锁定事务相关的行
1)MySQL中粒度最小的锁,且依赖于存储引擎实现;
2)行锁的开销较大,且加锁较慢(容易出现死锁的情况);
记录锁
记录锁(Record Locks):对指定行的数据上锁
1)某行的记录锁不会对其周围行产生影响;
2)记录锁也分为S锁和X锁(其兼容性同普通S/X锁);
3)记录锁由存储引擎管理和维护(无法手动锁定和解锁);
间隙锁
间隙锁(Gap Locks):查询数据时对指定行范围上锁
1)作用:Gap锁可有效防止因其他事务插入数据而导致本事务的幻读;
2)其他事务若对上Gap锁的行范围插入数据会被阻塞,直到锁方式或超时;
3)Gap锁分为S锁和X锁,但Gap锁之间互相兼容(同时兼容记录锁);
4)Gap锁由存储引擎管理和维护(无法手动锁定和解锁);
5)仅在可重复读隔离界别时从会自动加Gap锁;
//Gap锁之间互相持有对方的范围(可能导致死锁)
临键锁
临键锁(Next-Key Locks):记录锁和Gap锁的合体
1)临键锁可锁定某行的同时,保证该行前的范围数据不会被改变;
2)临键锁分为S锁和X锁(其兼容性同普通S/X锁);
3)MySQL默认的行锁,其范围是前开后闭;
插入意向锁
插入意向锁(Insert Intention Locks):特殊的Gap锁(插入数据时)
1)作用:表明INSERT语句等待Gap锁的释放;
2)插入意向锁互不排斥(多个事务在范围内可同时执行);
3)主键或唯一索引冲突时,则插入意向锁也会冲突(事务阻塞);
4)插入意向锁不会阻止别的事务继续获取该行上的其他类型的锁;
实现原理
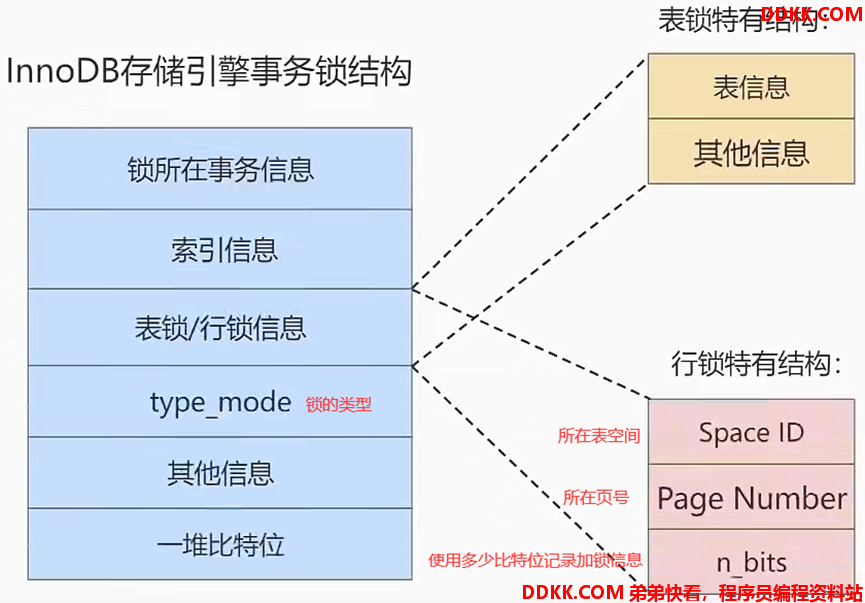
锁结构:数据锁在内存中存放锁信息的方式
1)通常每个锁在内存中单独对应个锁结构,特殊情况是:
| 仅满足以下4个条件时,多个锁信息会存储于一个锁结构中 |
|---|
| 被加锁的数据处于同一个数据页 |
| 在同一个事务中进行加锁 |
| 加锁的类型是相同的 |
| 锁等待状态是相同的 |
如:锁结构在内存中的构成
MVCC
MVCC(Multiversion Concurrency Control):多版本并发控制
1)本质:通过管理数据行的多个版本实现数据库的并发访问(保证一致性读)
2)不同数据库实现MVCC的方式不同(常用的依赖于InnoDB实现)
3)MVCC通过快照读实现不加锁读、非阻塞并发读(乐观锁)
快照读(一致性读):数据通过数据快照获取
1)不加锁的简单SELECT查询均属于快照读;
2)快照读不能保证数据是最新版本(可能读取旧数据);
3)若隔离级别是可串行化,则快照读会退化为“当前读”;
当前读:仅获取最新数据
1)数据库中所有操作执行时都会上锁(防止其他并发事务影响);
2)当前读的并发性较低;
实现原理
MVCC实现依赖于:Undo、隐藏字段、ReadView
1)通过Undo实现Undo版本链,以获取数据各个版本的历史快照;
2)数据行被CURD时都会记录以下2个隐藏字段:
| 隐藏字段 | 说明 |
|---|---|
| trx_id | 执行该操作的事务ID |
| roll_pointer | 指向数据历史的最近次Undo (Undo版本链通过多个该指针形成) |
ReadView
ReadView:事务使用MVCC进行快照读时产生的读视图
1)每个事务启动,数据库都会生成当前数据快照供事务使用;
2)不同隔离级别下,ReadView的生成时机也不同;
| 隔离级别 | ReadView |
|---|---|
| 未提交读 | 不生成 (可读取未提交的事务,所以直接读取最新数据) |
| 提交读 | 每次SELECT执行前都会生成个ReadView |
| 可重复读 | 仅在首次SELECT执行前生成个ReadView,后续重复使用 |
| 串行化 | 不生成 (通过加锁方式访问数据) |
ReadView的4主要组成:
| 组成 | 含义 |
|---|---|
| creator_trx_id | 创建该ReadView的事务ID (只读事务中默认为0) |
| trx_ids | 生成ReadView时数据库中活跃的事务ID列表 |
| up_limit_id | 活跃事务列表中最小事务ID (未提交的) |
| low_limit_id | 数据库事务列表中最大事务ID (已提交的) |
事务通过MVCC的ReadView判断是否可读数据的流程:
1)隐藏字段trx_id和creator_trx_id是否相等(是否属于本事务);
2)若trx_id小于up_limit_id,表明生成该ReadView的事务已提交;
3)若trx_id大/等于low_limit_id,表明生成该ReadView的事务未提交;
4)若trx_id位于up_limit_id和low_limit_id之间,需判断其是否在trx_ids中:
| 是否在trx_ids中 | 说明 |
|---|---|
| 是 | 生成该ReadView的事务未提交 |
| 否 | 生成该ReadView的事务已提交 |
//本质:事务仍可获得其他数据,但通过数据的隐藏字段trx_id判断是否可用
//若无法从ReadView中获取,则需从Undo版本链中获取所需数据快照