子查询
子查询:在一个查询里嵌套了其他的若干查询(没有数量限制)
1)SELECT语句的WHERE或HAVING或FROM子句中包含另一个SELECT
2)凡是分步实现的查询都可以考虑用子查询来实现
父查询:包含的SELECT语句为外层查询
子查询:被包含的SELECT语句为内层查询,包括相关子查询和不相关子查询
//内层查询必须用小括号括起来,并且与父查询嵌套式用相应的运算符
不相关子查询:子查询的查询条件不依赖于父查询(由内向外逐层处理)
1)本质:先执行子查询,再将子查询的结果用于建立父查询的检索条件进行逐层检索
相关子查询:子查询的查询条件依赖于父查询(由外向内再向外)
1)指定字段时,必须使用完全限定列名
2)子查询执行次数取决于父查询中的数据
3)本质:先取父查询表中第一个数据,根据其与内层查询的相关数据处理;再将内层查询后的查询结果代入外层查询进行查询,得到真正检索结果;以此类推,直至将父查询表中的数据全部带入
完全限定的列名:同时指定列的表名和列名,格式“表名.字段名”
1)原因:不同表中的列名可能存在重复问题
SELECT子查询格式:
SELECT 其他字段,(子查询)[AS] 别名
1)子查询的结果通常为显示字段,必须取别名
FROM子查询格式:
FROM (子查询)[AS] 别名
1)子查询的结果通常为多行多列(当做临时表处理),必须取别名
WHERE子查询格式:
WHERE 表达式 运算符
(子查询);
1)表达式是用于比较的,通常为字段名
2)子查询返回的字段数量必须与WHERE指定的字段/表达式数量相同
运算符子:对表达式的值和子查询返回的值进行比较运算
| 运算符 | 语法格式 | 说明 | 适用情况 |
|---|---|---|---|
| 比较运算符 | <表达式> {=|<|>| >=|<= |< > |!=} <子查询> | 包括=、>、<、>=、<= 、<> 主要用于对表达式的值和子查询返回的值进行比较运算 | 子查询返回单行(单行单列或者单行多列)时使用 |
| [NOT] IN | <表达式> [NOT] IN <子查询> | 主要用于判断表达式的值是否存在于子查询的结果集中 | 子查询返回多值(多行单列,包括单行)时使用 |
| ANY|SOME | <表达式> {=|<|>|>=|<=|< >|!=} {SOME|ANY} <子查询> | 关键字 SOME 和 ANY 是同义的,用于表示表达式只要与子查询结果集中的某个值满足比较关系,子查询就返回 TRUE,否则返回 FALSE | 子查询返回多值(多行单列)时使用; 使用时必须同时使用比较运算符 |
| ALL | <表达式> {=|<|>| >=|<= |< > |!=} ALL <子查询> | 用于表示表达式需要与子查询结果集中的每个值都进行比较,当表达式与每个值都满足比较关系时,会返回 TRUE,否则返回 FALSE | 子查询返回多值(多行单列)时使用; 使用时必须同时使用比较运算符 |
| [NOT] EXISTS | [NOT] EXIST <子查询> | 主要用于判断子查询的结果集是否为空。若子查询的结果集不为空,则返回 TRUE;否则返回 FALSE。NOT EXISTS与之相反 | 子查询返回逻辑值时使用 都是相关子查询 |
| 组合 | 说明 | 对应关系 |
|---|---|---|
| > ANY | 大于子查询结果中的某个值 | >MIN() |
| < ANY | 小于子查询结果中的某个值 | <MAX() |
| >= ANY | 大于等于子查询结果中的某个值 | >=MIN() |
| <= ANY | 小于等于子查询结果中的某个值 | <=MAX() |
| = ANY | 等于子查询结果中的某个值 | IN |
| <>ANY | 不等于子查询结果中的某个值 | 无 |
//表中的所有ANY都可用SOME替换
//ANY|SOME本质就是IN和运算符的结合(通过运算符判断是否符合)
| 组合 | 说明 | 对应关系 |
|---|---|---|
| > ALL | 大于子查询结果中的所有值 | >MAX() |
| < ALL | 小于子查询结果中的所有值 | <MIN() |
| >= ALL | 大于等于子查询结果中的所有值 | >=MAX() |
| <= ALL | 小于等于子查询结果中的所有值 | <=MIN() |
| =ALL | 等于子查询结果中的所有值 (通常没有实际意义) | 无 |
| <>ALL | 不等于子查询结果中的任何一个值 | NOT IN |
//ALL和ANY/SOME是两个极端(一个是所有都需满足,一个是其中有一个满足即可)
不相关子查询
不相关子查询:子查询的查询条件不依赖于父查询(由内向外逐层处理)
如:检索数据库中proid_id字段值为TNT2的cust_id字段
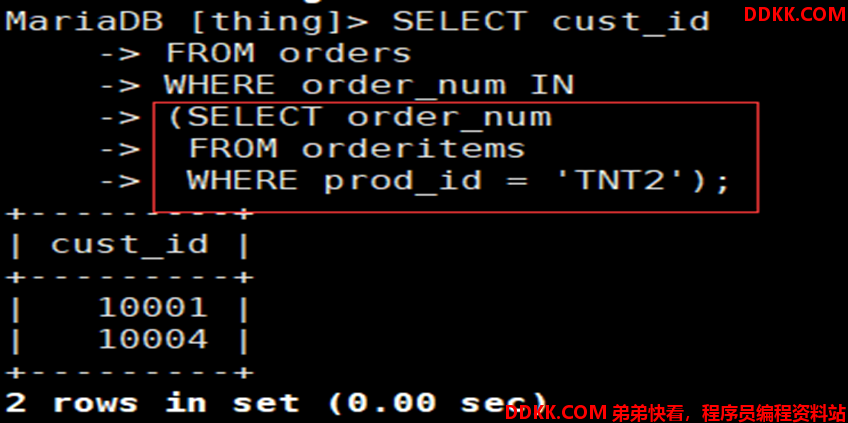
1)先检索子查询中prod_id为TNT2的order_num,并将结果返回至父查询
2)父查询自己的order_num和子查询返回的order_num进行IN运算
3)显示order_num成功匹配的cust_id
如:检索数据库中proid字段值为TNT的cust_name和cust_contact字段
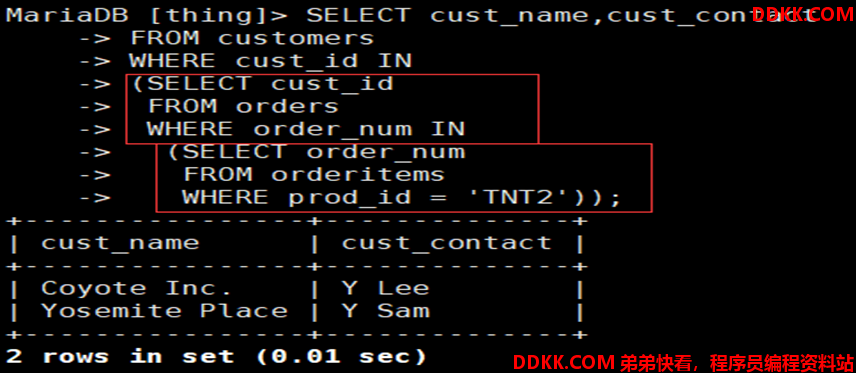
1)先检索子子查询中prod_id为TNT2的order_num,并将结果返回至子查询
2)子查询自己的order_num和子子查询返回的order_num进行IN运算
3)子查询将order_num匹配成功的cust_id结果返回值父查询
4)父查询自己的cust_id和子查询返回的cust_id进行IN运算
5)显示cust_id成功匹配的cust_name和cust_contact
相关子查询
相关子查询:子查询的查询条件依赖于父查询(由外向内再向外)
1)指定字段时,必须使用完全限定列名
如:检索数据库中每个customers字段在orders的行数个数
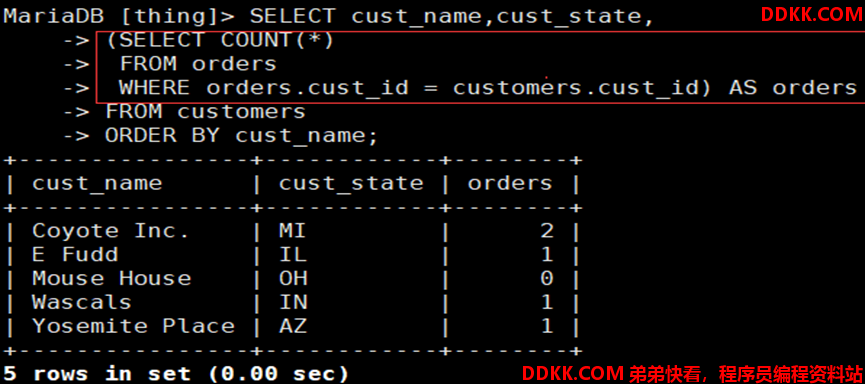
1)先读取父查询中customers表中的cust_id字段值
2)代入子查询,与子查询中的cust_id字段值匹配
3)匹配成功后,调用聚合COUNT()函数计算行数个数
4)并将结果返回至父查询,再调用父查询中customers表中的cust_id字段的值
5)以此类推,直至父查询中customers表中cust_id字段值都带入一次
调用[NOT]EXISTS的子查询是相关子查询(子字段列名通常都用*)
1)EXISTS用于检查子查询是否至少会返回一行数据(实际上子查询并不返回任何数据,而是返回True或False)
2)根据EXISTS查询结果判断:将父查询表的指定行,代入子查询进行匹配
//如果子查询返回结果为非空,则EXISTS返回True(且这一行可作为父查询的结果行,不能作为结果)
如:查询选修了全部课程的学生姓名(EXISTS子查询)
SELECT SName
FROM Student S
WHERE NOT EXISTS
(SELECT *
FROM course C
WHERE NOT EXISTS
(SELECT *
FROM register R
WHERE S.SId=R.SId AND C.CId=R.Cid));
//“选修全部课程”等价于“不存在一门课程没有选修”
//EXISTS查询本质就是父查询与子查询的笛卡尔积后再进行数据匹配
连接查询
连接查询:实现多表查询(表与表之间通过外码约束相互关联)
1)关系数据库模型的主要特点(区别于其他类型数据库管理系统的一个标志)
如:连接查询有以下方式
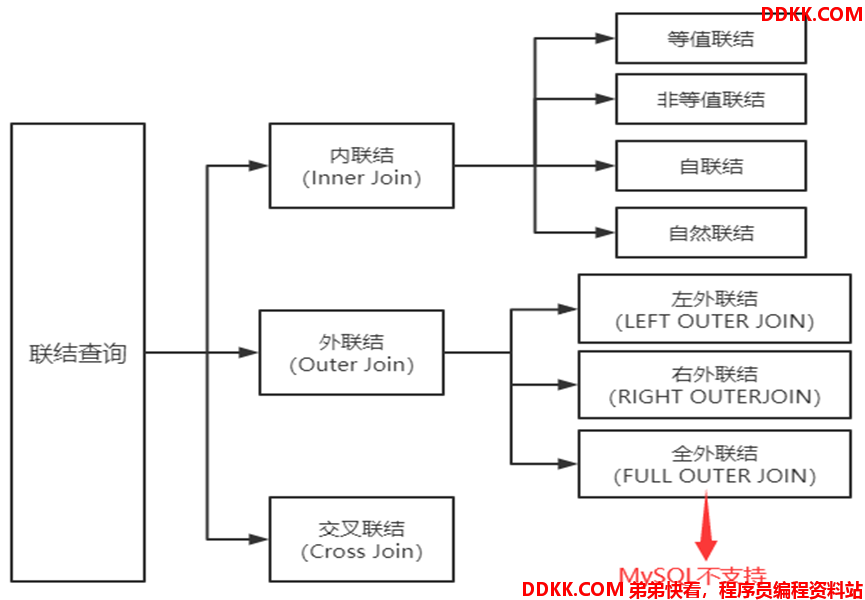
内连接
内连接(INNER JOIN):根据连接条件将多个表中的字段组合成新的表
| 连接方式 | 说明 |
|---|---|
| 等值连接 | 连接条件中使用“=”运算符比较连接字段上的取值 (查询结果包括重复列) |
| 非等值连接 | 连接条件中使用运算符比较连接字段上的取值 (>、>=、<=、<、<>) |
| 自连接 | 表与表自身连接 |
| 自然连接 | 特殊的等值连接 (查询结果去掉重复的列) |
连接条件的设置(内连接的关键之处):
[表名1.]字段1 <比较运算符> <表名2>.<字段2\>
1)字段1和字段2为连接字段
2)连接字段为同名字段,必须使用完全限定列名
3)两个表若没有连接条件进行连接,则会成两个表的笛卡尔积表
//可给表名设置别名,但其他子句也需同样要使用别名
等值(非等值)连接格式1:
FROM 表名1,表名2
WHERE 连接条件;
1)连接和筛选条件统一写在WHERE子句后,用AND进行连接
2)连接条件一般都选择外键(连接条件不一定都是外键)
如:连接vendors和products表
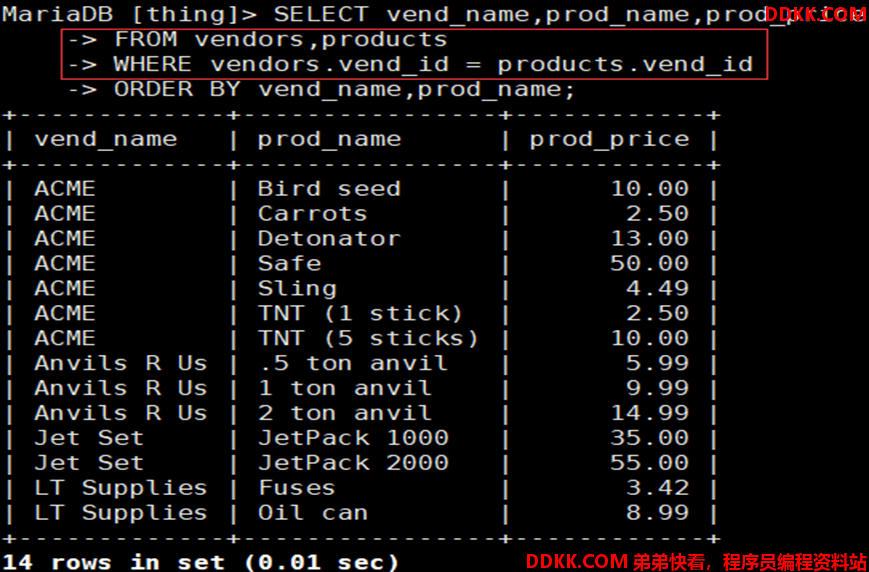
等值(非等值)连接格式2:
FROM 表名 1 [INNER] JOIN 表名 2 ON 连接条件;
1)JOIN ON子句是成对出现的,可以连续使用JOIN ON实现多个表内连接
2)内连接是系统默认的表连接,所以FROM子句后可以省略INNER
//连接条件常选择外键(连接条件不一定都是外键)
如:连接orderitem、products和vendors表
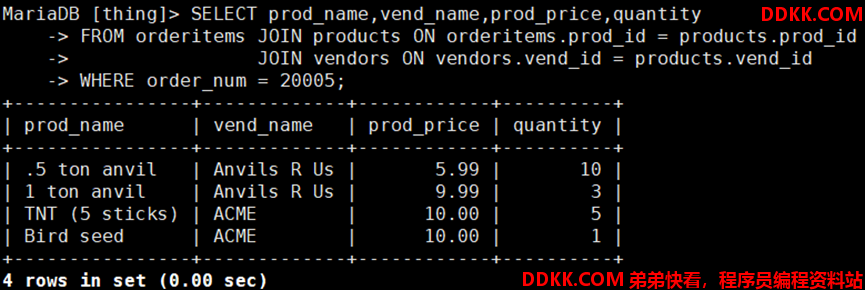
自连接格式:
FROM 表名1 别名1 JOIN 表名1 别名2 ON 连接条件;
1)自连接一定要有别名(相同的表有一样的属性不利于操作)
2)自连接可代替所有从相同表检索数据的子查询
//也可使用类似等值连接格式1进行连接
如:检索products表中和prid_id为DTNTR具相同vend_id字段值的其他字段
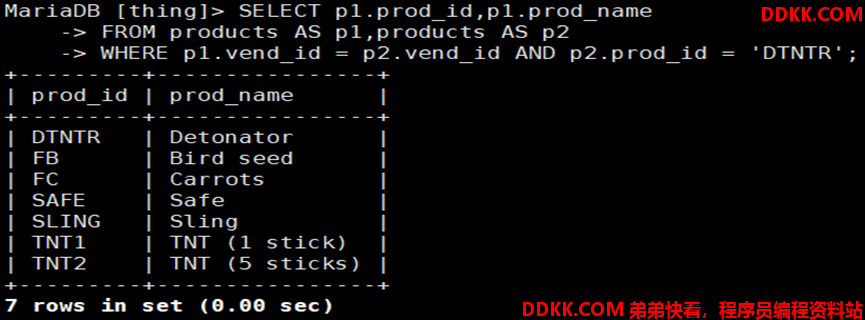
自然连接格式:
FROM 表名1 NATURAL JOIN 表名2 连接条件;
1)进行连接的必须是相同的字段名,且无须添加连接条件
2)结果会自动去掉重复的列,与DISTINCT不同(去掉重复的行)
如:自然连接customers和orders表(两者均有cust_id字段)
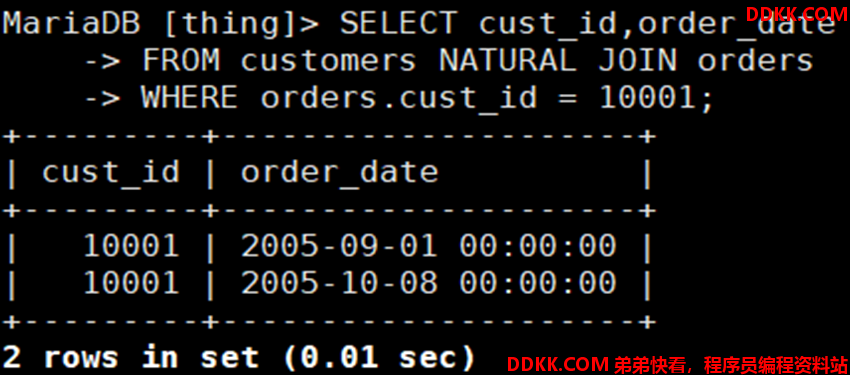
外连接
外连接:表连接时把一方表要舍弃的行保留下,另一方对应的字段上填NULL
| 连接方式 | 说明 |
|---|---|
| 左外连接 | 把左表要舍弃的行保留下,右表对应的字段上填NULL |
| 右外连接 | 把右表要舍弃的行保留下,左表对应的字段上填NULL |
| 全外连接 | 把左表和右表要舍弃的行都保留下,相对应的列字段填NULL |
外连接格式:
FROM 表名1 LEFT/RIGHT [OUTER] JOIN 表名2 ON 连接条件;
1)左外连接和右外连接可以相互转换
2)多个表进行连接时,若存在外连接需要考虑是否连续使用外连接
//不能第一个使用外连接后面就不使用了,会导致前面得到数据丢失
如:检索数据库中cust_id字段所对应的order_num字段
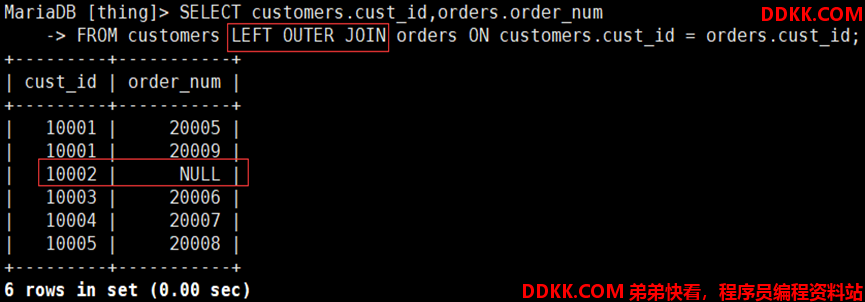
**交叉连接:**不带连接条件的查询,返回被连接的表所有数据行的笛卡尔积
1)检索结果的行数是左表的行数乘以右表的行数
2)不用添加连接条件
3)交叉连接格式:
FROM 表名1 CROSS JOIN 表名2;
//没有实际意义,通常用于测试所有可能的情况
联合查询
联合查询(UNION):将多个检索结果合并成一个检索结果显示
1)任何WHERE子句具有多个条件表达式的查询都可用联合查询代替
使用联合查询的有以下两种情况:
1)在单个查询中从不同的表返回类似结构的数据;
2)对单个表执行多个查询,并按单个查询返回数据;
MySQL不支持INTERSECT(交操作),EXCEPT或MINUS(差操作)
| 区别 | UNION | OR |
|---|---|---|
| 操作对象 | 连接结果集 | 连接表达式 |
联合查询格式:
SELECT查询语句1
UNION [ALL]
SELECT查询语句2
1)联合查询中每个查询必须包含相同的列、表达式或聚合函数
2)数据类型可不完全相同,但必须兼容(系统可自动转换类型输出)
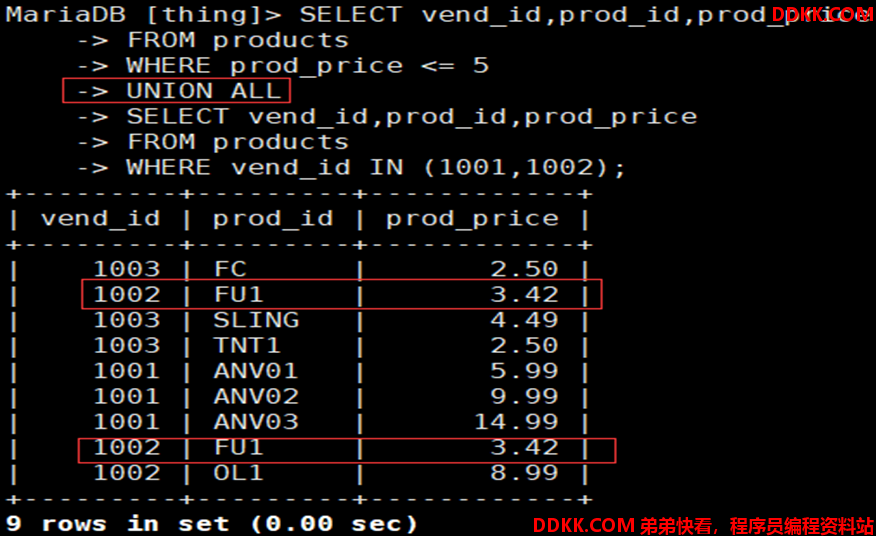
3)联合联系的UNION结果默认去除重复的行,若显示全部行UNION ALL
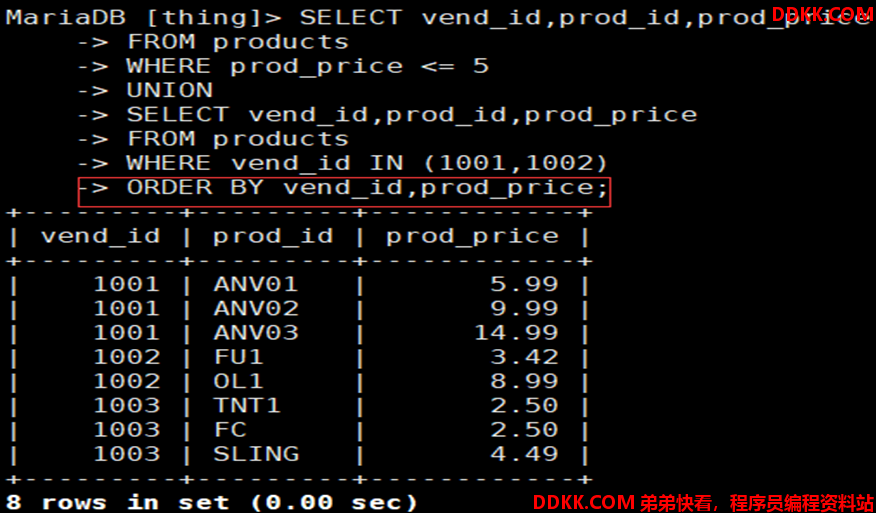
4)联合查询中只能调用一次ORDER BY进行排序
//若结果集的列名不一致,默认第一条查出来的列名作为显示列名
//ORDER BY语句必须在最后一个查询语句,针对合并后检索结果进行排序
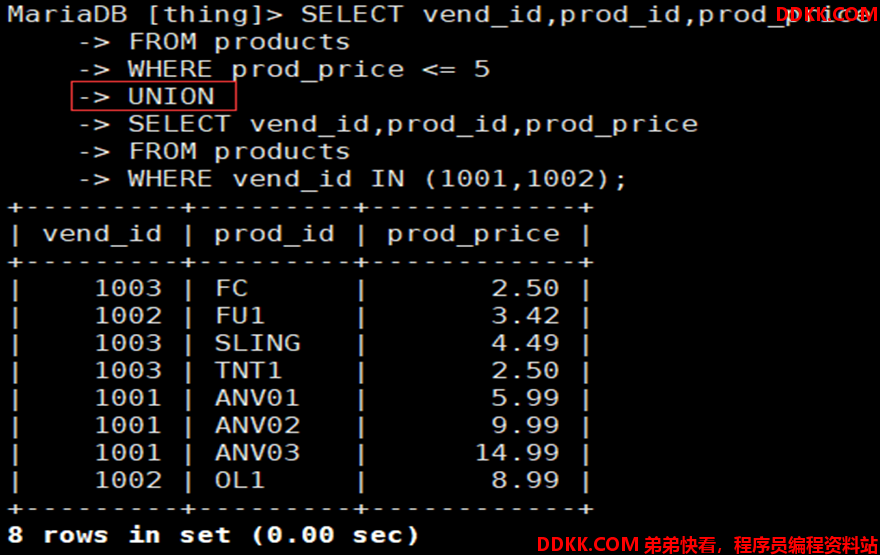
如:检索products表中prod_price小于等于5或vend_id为1001或1002的行
如:续上,且包含重复行显示
如:续上,且对合并后的结果进行排序
CASE表达式
CASE表达式:不是完整的SQL语句(不能单独执行,作为表达式使用)
1)CASE表达式分为简单CASE和搜索CASE
2)CASE后跟的字段名必须是SELECT检索的字段
3)CASE函数一般直接跟在SELECT语句后
//CASE函数本质就是对查询到的值进行一种转换(使用另外一种形式表达)
简单CASE函数:只做数据匹配(不进行比较运算和逻辑运算)
CASE 字段名
WHEN 值1 THEN 转换值1
WHEN 值2 THEN 转换值2
ELSE 转换值n
END [[AS] 别名]
搜索CASE函数:进行更为复杂的数据转换
CASE
WHEN 布尔表达式1 THEN 转换值1
WHEN 布尔表达式2 THEN 转换值2
END [[AS] 别名]
全文本搜索
全文本搜索:调用Match()和Against()函数对长文本进行良好程度搜索
1)Match()指定索引的字段,Against()指定搜索的表达式
2)MyISAM存储引擎才具有的功能(Innodb存储引擎不支持)
//优点:快速高效地搜索指定列,而且能提供一种智能化的结果
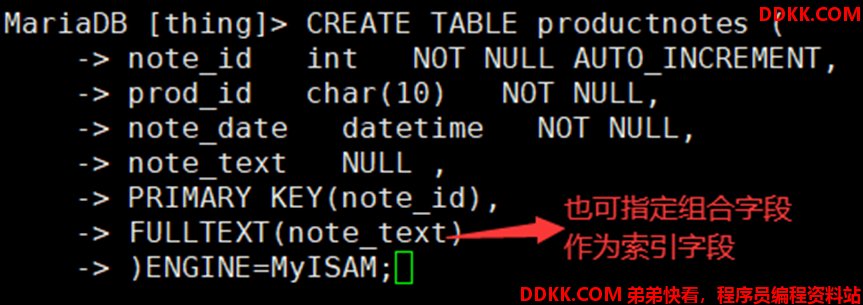
表支持全文本搜索需在其创建时指定其接受FULLTEXT子句
1)已创建或导入数据后也可修改表使其接受FULLTEXT子句(但所有数据需进行索引,占用较长时间)
2)设置完成后,后续系统会自动维护/更新该表的索引
//使用全文本搜索的前提是表支持进行全文本搜索
如:创建productnotes表,并使其支持全文本搜索
如:使用全文本搜索productnotes表中含有rabbit词的行
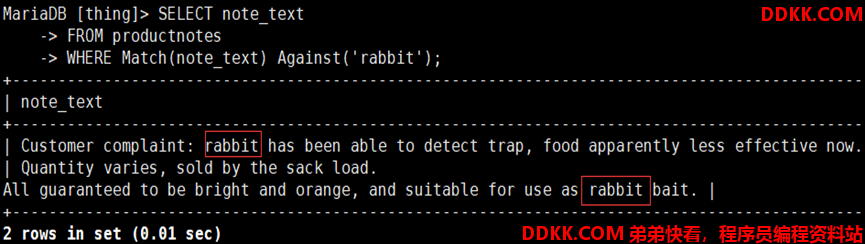
1)传递给Match()的参数必须是配置FULLTEXT时指定的字段/组合字段
2)其结果默认按降序等级排序显示
全文本搜索等级:由该行词的数目、唯一词的数目、索引中词的总数和词位于该行的位置计算得出
//以上符合则给该行加等级,最后排序等级为0的行再进行显示
全文本搜索由以下规定:
1)索引全文本数据时,短词被忽略且从索引中去除
2)MySQL中有内建的非用词(StopWord),这些词在索引中被排除
3)50%规则:若一个词出现频率大于50%,则将其视为非用词忽略
4)表中的行数若少于3行,则全文本搜索不反回结果(50%规则)
5)忽略词中的单引号(如:don’t索引为dont)
//短词:默认定义具有3个或3个以下字符的词(可修改)
//50%规则不用于布尔文本搜索
查询扩展
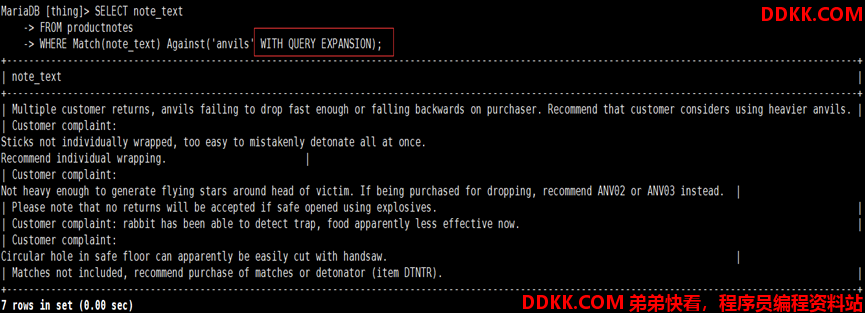
查询扩展(WITH QUERY EXPANSION):将全文本搜索结果的范围放宽
1)本质是对表进行两次全文本搜索(找出可能相关的结果,即使不能包含搜索指定的词)
查询扩展执行过程:
1)执行基本的全文本搜索,找出与搜索条件匹配的所有行,系统会检索这些匹配行并选择所有有用的词;
2)根据上次全文本搜索返回的词,再次执行全文本搜索
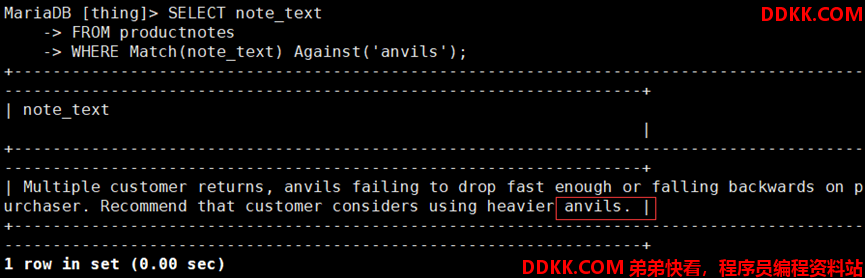
如:使用查询扩展搜索productnotes表中相关anvils词的行
1)搜索匹配的行,并检索有用的词
2)根据返回的词,再词执行全文本搜索
布尔文本搜索
布尔文本搜索(IN BOOLEAN MODE):全文本搜索的另一种形式
1)不同于全文本搜索在于其没有FULLTEXT索引也可查询
如:使用布尔文本搜索productnotes表中相关heavy词的行
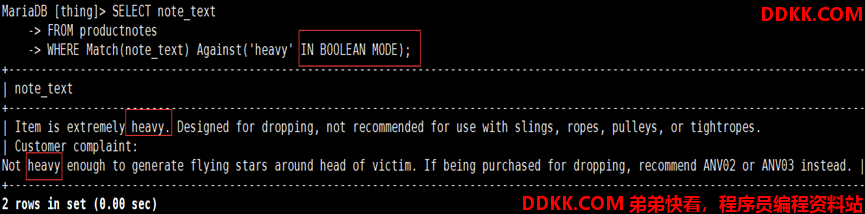
| 布尔操作符 | 说明 |
|---|---|
| + | 包含 |
| - | 不包含 |
| > | 若包含,则增加等级 |
| < | 若包含,则减少等级 |
| () | 包词组成子表达式 |
| ~ | 取消一个词的排序值 |
| * | 通配符 |
| “” | 定义一个短语 |
如:使用布尔文本搜索productnotes表中相关heavy和不包含rope开头的行
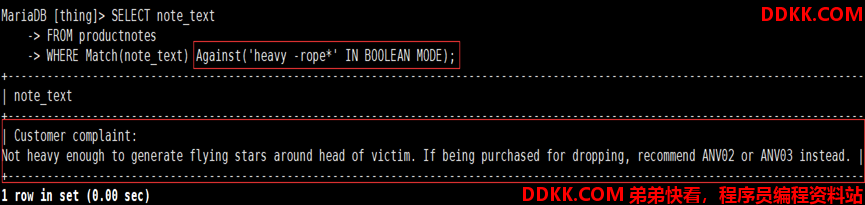
如:使用布尔文本搜索productnotes表中同时包含rabbit和bait的行

如:使用布尔文本搜索productnotes表中包含rabbit或bait的行

如:使用布尔文本搜索productnotes表中包含rabbit bait短语的行

如:使用布尔文本搜索productnotes表中包含safe和combination的行,搜索到combination则减少等级
