注:本系列主要注重并发编程这块儿,JVM内容很多,会另外开专栏总结,此系列可能只是会稍微提及
一、跨平台和JVM
经过前面几篇博文的介绍,我们知道,任何编程语言编写的程序要想被计算机执行,都必须被翻译成运行环境的CPU所能识别的一系列指令。这就导致了一个现象:通常情况下,我们的程序被编译后,只能在对应系列的CPU架构上运行。如果想要在其它不同架构的CPU上运行,则需要根据对应的CPU指令集重新对源码进行编译。这个局限性就比较大了,特别是上个世纪末,互联网的迅速发展使这一局限性进一步放大,人们急需一种能够跨平台执行、可移植性强的语言。SUN公司看准时机,拾起了之前被搁置的Oak语言,推出了可以嵌入网页并且可以随同网页在网络上传输的Applet,并将Oak更名为Java,然后在极短的时间内“席卷”IT界。它之所以成功,则主要归功于其跨平台性,而其跨平台性又依赖于JVM(Java虚拟机)。
Applet“包含”在HTML中,使用
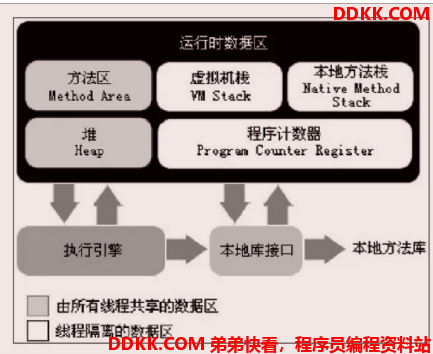
JVM是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。其运行时内存划分为如下图中的几个区域(图片来源于百度(1.7)):
二、CPU和缓存一致性
由于CPU运算速度要比内存读写速度快的多,所以如果CPU每每执行指令都直接和内存交互的话,则会花费大量的时间等待数据读取和数据写入,在等待的过程中我们的CPU资源则处于“浪费”状态,俗话说浪费可耻,于是乎,CPU高速缓存出现了。高速缓存位于CPU寄存器组和内存之间,它的速度远高于内存但是也比不上CPU内部的寄存器组。如果我们引入了缓存,那么当CPU要使用数据的时候,可以先从缓存中获取,从而加快读取速度。如果缓存没有数据再从内存加载,然后写入缓存,方便后面使用,但是缓存中的一些数据可能过一段时间就不那么常用了,所以需要一定的算法淘汰这些缓存数据,以清理空间。就这样,我们在很大的程度上解决了CPU运算速度与内存读写速度不匹配的矛盾。(这和我们平时项目中在数据库和应用之间加入类似于redis的缓存是一个道理)
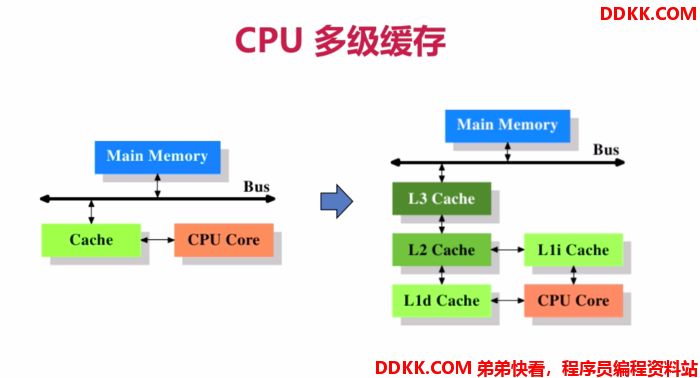
按照数据读取顺序和与CPU结合的紧密程度,CPU缓存还可以进一步分为一级缓存、二级缓存、三级缓存等。当CPU要读取一个数据时,首先从一级缓存中查找,如果没有找到再从二级缓存中查找,如果还是没有找到就从三级缓存或内存中查找。
有了多级缓存之后,CPU对于数据的读取和存储都会经过高速缓存,CPU与高速缓存有一条特殊的快速通道相连,而主存与高速缓存都连在系统总线上(当然,这条总线还会用于其他组件的通信),如下图所示(网图):
CPU执行指令的时候如果涉及到数据的读写操作,会将运算需要的数据从主存(内存)复制一份到我们上面提到的高速缓存当中,接下来CPU计算时就可以直接在它的高速缓存上进行数据的读写,当运算结束之后,再将数据从高速缓存刷新到主存当中。比如:i = i + 1;(当然,CPU看见的语句可不是这个样子哈)
当CPU执行这个语句时,会先从主存(内存)中读取 i 当前的值,然后将其复制一份到高速缓存,这时相当于高速缓存中有了 i 的一个副本,接下来对该副本进行加 1 操作,加法完成后将结果写入高速缓存,最后再将高速缓存中的值刷新到主存。
在以前的单核单CPU时代,所谓的多线程都不是真正意义上的多线程,因为一个CPU内核在同一个时间点只能执行一个任务,这个时候的多线程是通过分配CPU时间片实现的,执行一个任务的时候,其它任务则等待,只是等待的时间很短,这让我们看起来像是多个线程在同时运行。可是随着制造工艺的发展,现在多核CPU已经成为常态,什么双核、四核等等随处可见。在多核多CPU的场景下,可以实现真正意义的多线程操作,比如两个线程可以运行于一个CPU内的两个不同的内核(这里我们不用在意多CPU或者多核CPU),它们相互独立。
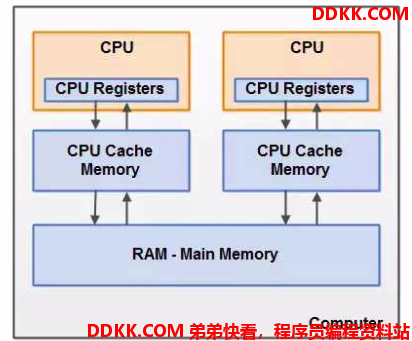
我们现在要注意前面说到的高速缓存,一级缓存就在CPU内核旁边和其紧密相连,是内核独享的,但是二级缓存和三级缓存等则根据CPU的设计,可能是多核共享的。但这并不是我们现在考虑的重点。以下为网图:
虽然多线程很爽,但是又不可避免的引出了一个问题,我们以上面 i = i + 1;的例子说明。这条语句乍一看,在单线程下是没有问题的,但是在多线程的情况下则可能变得不一样了。我们设 i 的初始为 1,如果我们有A、B两个线程同时执行这行代码,那么每个线程都会发生上述的计算流程。这个时候可能会出现一个情况(当然还有其它情况会导致类似的结果):
1>A线程和B线程都从主存中读取了i的值,并且缓存到各自的高速缓存中,此时两个副本都为1;
2>然后A线程进行加1操作,副本值变成了2,最后回写到主存中,主存中的值为2;
3>此时B线程的副本值还是1,加1操作的结果还是为2,然后将其回写到主存;
4>最终主存的值为:2。
但是我们的预期应该是3才对,因为毕竟执行了两次加1操作嘛。这个就是我们通常说的缓存一致性问题了,在主存中的值可以被所有线程访问,所以我们称之为共享变量,高速缓存中的副本值只能自己访问,所以称之为共享变量的私有拷贝(我们要明确,不论是单核还是多核还是多CPU,涉及到多线程处理,都可能会出问题)。
缓存一致性的问题归根结底是由多个线程同时操作一个共享变量导致的,所以要解决这个问题其实很“简单”:只需要保证共享变量在被某一个线程操作的时候,其它线程都不能对其操作即可。对应到上面的例子也就是:如果A线程先处理共享变量 i 的值,B线程就只有等待A线程处理,并且A线程将最新的值更新到主存之后,B线程才能获取变量 i,再进行操作,这样就能保证结果不会有问题啦。
而我们前面讲了,主存和高速缓存连在系统总线(Bus)上,它们通过总线进行通信。所以我们可以通过在总线上加锁(LOCK)的方式达到目的。比如A和B要从主存中获取变量 i 的时候,先在总线上发起LOCK信号,如果LOCK成功才能获取变量 i 的值,否则只能等待LOCK被释放才能从其内存地址获取值。
这的确从根源上解决了缓存不一致的问题。但继而又引出了另一个问题:在LOCK总线的期间,其它线程都只能等待,不能访问该内存区域,导致了效率低下,又特别是对共享变量根本就只有读操作,不存在写操作的时候,更加让人不能忍受,于是乎,就出现了缓存一致性协议。最出名的也就是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。它的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其它的CPU中存在该变量的副本,会发出信号通知其它CPU将该变量的缓存行置为无效状态,然后当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,它就会从内存重新读取。下面简单介绍一下MESI。
Modified(M):已修改。说明变量已经被持有它的处理器修改,如果一个段处于该状态,那么它在其他处理器缓存中的拷贝马上会变成“失效”(Invalid)状态。另外,已修改缓存段如果被丢弃或标记为失效,那么先要把它的内容回写到内存中。
Exclusive(E):独占。只能被一个处理器持有该状态,一旦一个处理器持有了该状态的缓存段,那其它处理器就不能同时持有它。如果其他处理器本就持有了同一缓存段,那么它会马上变成“失效”(Invalid)状态。
Shared(S):共享。这种状态下的缓存段只能被读取,不能被写入。
Invalid(I):失效。如果缓存段为该状态,就相当于它从来没被加载到过缓存中一样。
只有当缓存段处于Modified或Exclusive状态时,处理器才算真正“持有”它,才能对其发起写操作,如果它没有持有该缓存段,又想要对其发起写操作,就需要先向总线发出申请:我想要写数据啦,可以不?只有当申请通过后才能执行写操作,同时如果其它处理器存有该变量的私有拷贝, 那么总线会通知它们:这个东西已经被某某持有啦,你们的缓存段即将失效!即处于Invalid状态。这时,该共享变量仅仅在持有它的处理器中有效,所以就不会有问题了。另外如果其它处理器要读取该缓存段,那么Exclusive或Modified状态的缓存段必须变为Shared状态,如果是Modified状态,则还需要将更新后的数据写回主存。
根据MESI协议,当某一个变量被某一个处理器独占时,其不会出现在其它处理器的有效缓存中,另外,它能保证数据如果被更新,然后被写回主存后,所有处理器的缓存段内容的有效值都和主存中的最新值对应。这就解决了上面的缓存不一致的问题。
注:其实在内核和缓存之间还存在一个区域叫做存储缓存(Store Buffer),缓存和总线之间还存在一个区域叫做失效队列(Invalid Queue),这两部分区域主要要解决的问题是内核发起通知等待响应导致自身阻塞的问题。它们的存在为指令重排提供了支撑,也正是由于他们的存在,MESI实现的缓存一致性其实是最终一致性,详见Java并发编程(八):volatile使用和原理详解。
三、JMM
JMM即Java Memory Model(Java内存模型),是一种内存访问规范,定义了程序中共享变量的访问规则(私有变量为线程私有,所以不会有并发问题,比如局部变量等等)。它提出的最初目的是为了支持多线程程序设计,Java也有必要保证Java程序能够屏蔽各种硬件和操作系统的内存访问差异,实现在不同的平台下都能支持正确的并发操作,当然在单核情况下依然有效。
为什么这么说呢?我们现在单单从多线程程序设计而言,像C语言这种程序语言,它直接依赖计算机操作系统的内存模型来实现并发操作,而对于不同的平台,其内存模型可能会有差异,所以这会导致同样的多线程程序在不同的宿主平台会有不同的表现,要想准确无误就可能需要针对不同的平台来编写程序。而Java号称“一次编译,到处运行”,现在已经有了JVM,所以也需要定义一套自己的内存模型,来保证在多线程程序设计也能在不同的宿主平台达成一致的并发效果。(Java内存模型和JVM运行时内存区域划分是两码事,后面会说明)
**注:**无论是JVM规范还是JMM(JMM是JVM规范的一个内容),都只是一些标准,最终会交给实现JVM的厂商自己去具体实现,而不同的厂商实现也可能不一样。所以规范和模型的定制既要严谨,又不能死板,需要给厂商留下足够的发挥空间。
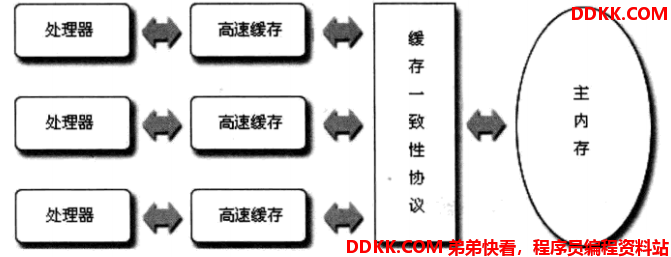
JMM作为虚拟机规范的一部分内容,规定了:每个线程都有自己的工作内存,工作内存中的“共享变量”只是主存共享变量在本地的私有拷贝,对数据的操作都只能在工作内存中进行,更新之后需要同步回主存,而不同的线程之间无法访问其它线程工作内存里的变量,线程之间值的传递必须通过主存来完成等等。如下图所示(网图):
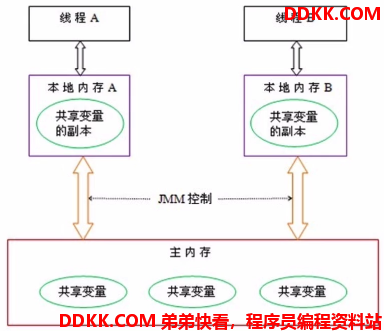
上图中的本地内存A、B就是线程各自的工作内存,要注意这个工作内存只是一个抽象的概念,可以把它们理解为CPU中的寄存器组、高速缓存等等的一种抽象描述,目标代码最终还是会被CPU所执行,JVM也是一个应用程序,而程序只是通过指令调用这些硬件完成对应的功能而已,不同的JVM厂商可以有自己的实现;而主存可以和我们的计算机内存类比,但是并不等同,它只是表示JVM使用的内存中的一部分而已。
按照这个模型,如果线程要操作一个共享变量,它就必须把变量拷贝到自己的工作内存中,更新之后再写回主内存,其它线程也只能从主内存中读取变量到自己的工作内存。我们发现,这个和前面说的CPU内核+高速缓存+内存的操作流程是一样的,所以在多线程的情况下,这里也会出现一样的缓存一致性问题。我们的CPU有MESI协议,同样,JMM也有自己的协议来保证缓存一致性。JMM定义了8种操作和一些规则,下面依次介绍。
1、lock:锁定;
目标:主内存的变量
功能:把某一个共享变量标记为某线程独占的状态
2、unlock:解锁;
目标:主内存的变量
功能:解锁一个处于lock状态的变量,unlock后的变量才能被其他线程lock
3、read:读取;
目标:主内存的变量
功能:把一个变量从主内存传输到线程的工作内存中
4、load:载入;
目标:工作内存的变量
功能:它把read操作从主内存中得到的变量值放入工作内存的本地变量副本中
5、use:使用;
目标:工作内存的变量
功能:把工作内存中的一个变量值传递给执行引擎,执行引擎遇到需要使用变量的值的指令的时候会触发此操作,比如i=i+1,需要先将i的值传递给执行引擎
6、assign:赋值;
目标:工作内存的变量
功能:它把一个从执行引擎接收到的值赋给工作内存的变量,当执行引擎对变量做出更新后,执行赋值操作指令的时候会触发操作,比如i=i+1,需要把i+1的结果赋值给i
7、store:存储;
目标:工作内存的变量
功能:把工作内存中的一个变量的值传送到主内存中,以便接下来的write的操作
8、write:写入;
目标:工作内存的变量
功能:它把store操作从工作内存中获取的一个变量的值覆盖到主内存的对应变量中
在说晦涩的规则之前,我们先举个例子来理解一下上面的八个操作,当然这例子并不是特别贴切:
还记得<<武林外传>>莫小贝捏泥人儿那集吗?有张飞、有岳飞、有王菲... 小贝捏的泥人很形象,但是我们总感觉一些泥人儿差那么一点儿感觉。比如,如果张飞的耳朵的轮廓在多一点儿的话应该会更逼真一点儿。所以我们邀请三个小伙伴(当然我是其中之一)组成了一个团队来检查这些泥人儿,负责给它们补眼、补嘴、补耳等等,好在小贝也乐于配合我们,把她的所有作品都拿了出来放在了桌子上。为了检查补偿工作能够有条不紊的进行,我们让小贝将她的泥人儿们编上号,比如A、B、C等等,然后放在一个大圆桌上,我们三个小伙伴每个人都搬一个小桌子围在大圆桌的周围,同时为了防止发生争抢(如果大家都想给王菲补补眼影的话~~),我们商量,泥人只能由小贝送到我们自己的小桌子上,我们只需要告诉小贝想要哪个泥人即可,而小贝就凭她先听到谁喊的为准咯。同时,补偿工作完成后,新泥人也只能通过小贝重新放回桌子上。另外,小贝为了防止我们乱涂乱画,弄废了她的作品,要求我们如果要改泥人儿,必须先照着泥人捏一个一模一样的,然后在新涅的泥人上涂画,最后她检查没问题才能替换掉之前的泥人儿。规定好之后,我们就开干啦!(假设组员包括我、小明、小华,而我们每个人都有一个御用“整形师”,来负责给泥人修整)
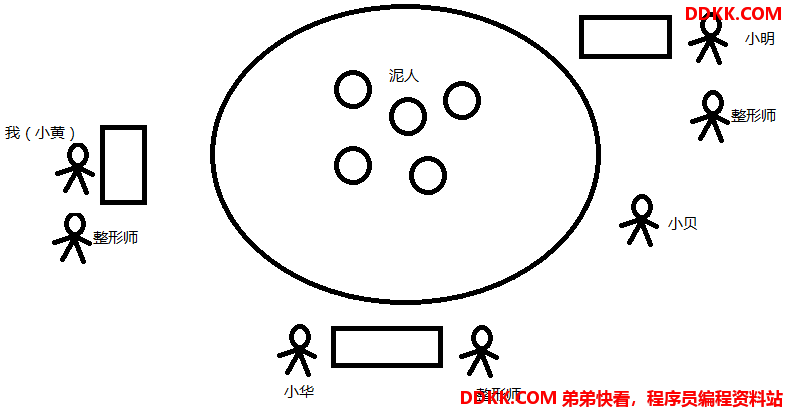
工作刚开始,我大吼一声,小贝我要A号(因为我看到A号是王菲^_^),小贝看了我一眼,点了点头,此时A就处于被我独占(lock)的状态了,突然,小明却比我吼的更大声:小贝,我也要A号!小贝看了他一样,表示无可奈何:现在A已经被小黄预定(独占)了,除非人家不再用(unlock)A了,我才能给你哦,你声音再大也没用。但是我可没那么傻,好不容易动作快抢到了,咋会放弃呢?所以很顺利的,小贝将A号王菲从大圆桌(主内存)上送(read)到了我的小桌子(工作内存)上,因为我早就想好了要给王菲画画眼影,所以到我手里之后我马上就要开干,碍于小贝的要求,我无奈的拿出一大块儿泥土,在我的桌子(工作内存)上照着王菲重新捏(load)了一个王菲二号(副本)。捏好王菲二号之后,就要准备开始画眼影了,我需要把王菲二号交给(use)我的御用“整形师”,整形师听了我的要求,兢兢业业的给王菲二号画上了眼影,然后交给(assign)了我。我瞅了瞅还是比较满意,然后就叫来了小贝:小贝,我这里修整完毕了!然后我将画完眼影的王菲二号交给小贝,小贝瞅了瞅,也还比较满意,就收下(store)我的王菲二号啦,然后就将我提供的王菲二号打上了(write)A号的标签,之前的王菲只有可怜的被丢弃(覆盖)咯~ 当然,我不会在修整王菲了,所以告诉小贝:贝啊,我不用(unlock)A号了哈!小贝点了点头,表示明白。这时候如果小明还想给王菲再涂涂口红的话,他可以去问小贝要(lock)A号了,而这个A号已经被我画上了眼影。当然如果他动作太慢的话还是“危险”哦。像这样,小组内的每个人都按照我给王菲画眼影的这个流程在有条不紊的工作着,直到所有泥人都修整完毕。
讲了上面的例子,我们再来从规范的角度来说说这些基本操作。
>read和load操作,store和write操作,必须按顺序执行。也就是只有先read了才能load,只有先store了才能write。
类比上面的例子:只有小贝把泥人儿给我们了,我们才能照着泥人儿捏一个新的泥人儿,同时也只有我们把最新的泥人儿给小贝了,小贝才能将其和旧泥人做替换。
**>read和load操作,store和write操作,虽然有顺序要求,但是并不要求必须连续执行,它们之间可以插入其它操作。**比如访问两个共享变量:read a,read b,load a, load b,回写同理。
类比上面的例子:我既想给王菲画眼影,又想给张飞加胡子,可以先让小贝把王菲和张飞的泥人儿都给我,我再一个一个的照着捏新泥人儿,并不要求我必须先把王菲二号弄好了,才去让小贝给我拿张飞。
**read和load操作,store和write操作,不允许单一出现。**也就是不允许一个变量从主内存读取了,但是工作内存不接受,或者从工作内存发起了向主内存的回写操作,但是主内存不接受的情况。
类比上面的例子:
我:小贝,我要改王菲! (read)
小贝:好的!
我:小贝,我又不想要了...(不执行load)
小贝:我刀呢......
----------
我:小贝,我改好了!
小贝:嗯,我看看...嗯 可以!(store)
我:好的!
小贝:等等,不行!!太丑了!(不执行write)
我:我刀呢......
>不允许一个线程丢弃它的最近的assign操作,也就是如果变量在工作内存发生了变更,则必须更新回主内存。
类比上面的例子:
我:师傅,给她加个眼影!
师傅:好的,没问题!%&*¥#... 好了,加好了!
我:好的,给我吧(assign)!嗯... 算了,感觉不好看,扔了算了(丢弃assign操作)
师傅:我刀呢......
**>不允许一个线程无原因地把数据从工作内存同步回主内存。**也就是一个数据如果没有发生assign操作,不允许回写到主存。
类比上面的例子:
我:小贝,我要改王菲!
小贝:好的,给你!
我:小贝,我又不想弄了,你放回去吧......(不触发assign,直接回写回主存)
小贝:玩儿我呢?我刀呢......
但是我们的确不想改怎么办呢?可以这样操作:
我:小贝,我要改王菲!
小贝:好的,给你!
我:哎,不想改了啊... 哎,师傅,泥人给你,你摸摸就可以了,等会儿在给我,不准问为什么!
师傅:额(⊙o⊙)… 好吧。¥%& 给你...(assign)
我:嗯,可以。小贝,改好了!
小贝:嗯,好......
>一个新的共享变量只能在主存中产生,不允许在工作内存中使用一个未被初始化(load或assign)的变量。也就是一个变量在实施use和store操作之前,必须先经历过load和assign操作。
类比上面的例子:我们只能先捏一个王菲二号,然后将二号交给整形师处理,同时交给小贝的泥人儿必须是被“处理”过的。
**>一个变量在同一时刻只允许一个线程对其进行lock操作,但是lock操作可以被同一个线程重复执行多次,多次执行lock后,必须要执行相同次数的unlock操作,变量才会被解除锁定。**这个比较直白,就不类比了哈
>如果一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前,需要重新执行load或assign操作初始化变量的值。
类比上面的例子:比如我们仿制泥人儿失败了,我们可以重新告诉小贝,要求再次修整,这时会把我们当前的成果都清空掉,重头来过
>如果一个变量没有被lock,则不允许对其执行unlock操作,也不允许去unlock一个被其它线程lock的变量。
类比上面的例子:你如果没有持有王菲泥人的锁定,却告诉小贝说你要解锁,怕会被以为是傻子哦~
>对一个变量执行unlock之前,必须将该变量同步回主存中(执行store和write操作)。
类比上面的例子:如果我们处理了泥人,不交给小贝不是白忙活了么~~
注:JMM虽然要求上述的8个操作都保持原子性,但是基于我们上面所说的规范不能太过死板,这里的原子性也有一些例外:对于64位的数据类型(long和double),如果没有被volatile关键字(后面会单独讲volatile)修饰,则可以将对其的读写操作划分为两次32位的操作来进行。也就是不强制要求read、load、store、write对于它们的原子性,这就是long和double的“非原子性协议”。
你可能会想到,难道多线程操作long和double会有并发问题吗?毕竟如果分为两次32位的操作来进行的话,不论几率多小,我们还是有可能会遇到“一半的值”。我们要知道,虽然规范里没有强制要求其为原子操作,但是官方也建议JVM厂商将它们实现为原子操作,而且现在我们所熟知的商用虚拟机基本上还是都选择将其作为原子操作对待。所以对于long和double的非原子性协议,做个了解就可以了。
四、JVM内存模型和JMM
JMM和JVM内存模型是位于不同层面的定义,他们描述的并不是同一个目标,并不能混为一谈。JVM内存模型是模拟计算机,在逻辑上将JVM使用的内存区域做了一个划分,像堆、栈、程序计数器等等(JVM篇章会详细总结)。而JMM可以认为是一种内存使用规范,它是为了多线程程序设计而生的,JVM在实现一些Java提供的关键字,比如synchronized、volatile,需要遵循这些规则。按照JMM的定义,每个线程都有自己的工作内存,线程私有,从逻辑上勉强可以对应JVM中的栈、程序计数器等,但是实际上为了速度,实际上使用的可能是寄存器和高速缓存等等,前面提到了,规范在这里定义的比较宽松,JVM厂商可以自己选择如何去利用计算机硬件资源。而JMM定义中的主存从功能上也勉强可以看做是JVM堆中的实例数据(包括方法区等),但要从JMM的角度看的话,其实对应的就是内存。总的来说JVM内存模型是一种内存划分规范,而JMM更像是一种行为规范。站在JVM内存划分的角度,我们的精力可能在于对象如何分配存放;而站在JMM的角度,我们注重的是如何操作这些对象。
五、总结
像这种主存和工作内存的模式,在我们的日常学习工作中也经常都能遇到。比如使用像git这样的的版本管理软件时,分支是存储在远端(主存)的,每个人都可以访问这些远端分支(不考虑权限),如果一个人(线程)要更新分支内容,只能将分支克隆到本地(工作内存),生成一个本地分支(私有拷贝),而每个人不能访问非自己工作内存的本地分支。如果要想把修改的内容同步给其它人,只能先将内容从本地分支同步到远端分支(push),然后其他人再从远端获取(pull)。另外,每个人将自己修改的内容同步到远端的时候,需要保证自己本地分支的内容是最新,不然会有冲突产生。如果所有人都可以直接在远端分支操作的话,同时操作的时候是会乱套的。是不是感觉和上面提到的流程差不多?
参考:<<深入理解Java虚拟机>>
注:本文是博主的个人理解,如果有错误的地方,希望大家不吝指出,谢谢