一、背景
大家都知道volatile作为一个“轻量级”的关键字,它能够保证可见性、有序性,但是不能保证原子性。那么它到底是怎么保证可见性和有序性的呢?为什么不能保证原子性呢?我们该如何正确使用volatile呢?下面我们一一进行解释。
二、volatile之可见性
对于可见性,我们在前面的博文已经介绍过了,这里直接出一个实际的例子:
public class Test {
public static boolean stoped = false;
public static void say() {
while (!stoped) {
}
System.out.println("stoped");
}
public static void stop() {
System.out.println("stop");
stoped = true;
}
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
say();
}
});
t1.start();
//睡眠1s
Thread.sleep(1000L);
//设置closed为true
stop();
//等待t1线程结束
t1.join();
}
}
在上述代码中,Test类有一个普通的静态布尔类型的stoped属性,默认为false;say方法主要执行一个while循环,循环的跳出条件是stoped==true;而stop方法会将stoped设置为true。
然后在main方法中,我们先启动一个线程t1去执行say方法,接着在睡眠1s之后再在主线程中调用close方法。原意是在stop()方法的调用之后,closed==true,这样t1线程执行的say方法也就会跳出while循环了,然后整个程序就执行完毕了。
但是运行该代码,我们发现在stop()方法调用之后,程序并没有结束运行,而是处于一种死循环的状态之中。这就是一个典型的由于可见性引发的一个线程安全问题。
分析:
基于我们前面说的主内存和工作内存的理论,closed变量是一个共享变量。线程t1先执行say()方法,会从主内存拷贝一份closed变量到自己的工作内存,然后使用本地副本进行while操作,此时closed==false,所以会一直循环;然后睡眠1秒之后,在主线程中调用close()方法,主线程也会从主内存拷贝一份closed变量到自己的工作内存作为本地副本,然后将副本值设置为true。但是,主线程工作内存中的closed变量的最新值(true)并没有及时同步回主内存,而即使我们将其同步回了主内存,也不能保证t1线程会马上从主内存获取最新的closed值。简单的说就是主线程对closed变量更新操作的结果,并没有及时反映到t1线程中。所以就出现了我们上面的死循环情况。
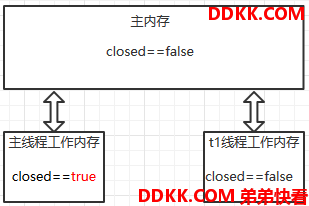
而我们前面的博文也讲了,Java内存模型对volatile定义了一些特殊的访问规则,它能保证修改后的最新值能立即同步到主存,并且每次使用都会从主存获取。这正好解决了我们上述主线程操作的结果没有及时反映到t1线程的问题。那么它是怎么实现这些规则的呢?我们来看一下有volatile修饰和没有volatile修饰的代码,反映到汇编是一个什么样的情况(关于如何查看JIT的汇编代码请参考JIT生成代码反汇编(HSDIS))。由于汇编代码太多,我这里只截取我们关注的点:设置closed变量。
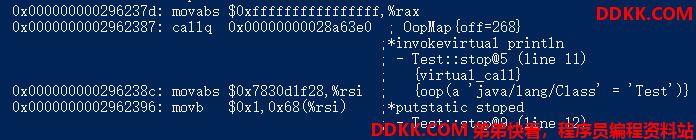
无volatile修饰:
有volatile修饰:
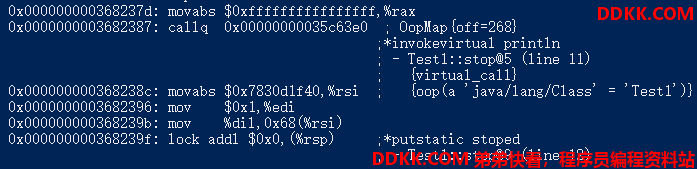
我们不用关心赋值指令,但通过对比我们发现,如果变量有volatile修饰,那么在变量的赋值操作之后会执行一个lock addl $0x0,(%rsp)操作。而addl $0x0,(%rsp) 就是简单的把RSP寄存器(博主为64位环境)的值加0,这显然是一个“空操作”,之所以这样处理是因为lock前缀不允许配合nop指令使用。而这里我们更应该关注lock前缀,它的作用是使本CPU的Cache写入内存,且该操作会使其他CPU(内核)内的Cache转换为无效(Invalid)状态(回想一下前面提到的CPU缓存一致性协议)。所以通过这种方式就能使得volatile修饰的变量对其它CPU立即可见,也就解决了我们上面的可见性问题。
注:我们在计算机基础相关的博文中已经提过了汇编,如果要明确对应的汇编指令的具体描述,读者需要自行寻找实际运行环境CPU架构相关的开发手册查询。
这会儿我们来再看一个“有趣”的问题,还是上面的代码,我们稍微改造一下say()方法:在while循环体中加一条输出语句,如下所示:
public static void say() {
while (!stoped) {
System.out.println("saying");
}
System.out.println("stoped");
}
然后我们发现,这时候即使stoped变量没有被volatile修饰,程序也会按照预期结束,这是为什么呢?其实原因就在于System.out.println()。println方法是包含synchronized关键字的,其源码如下所示:
public void println(String x) {
synchronized (this) {
print(x);
newLine();
}
}
关键就在于这个synchronized,我们先在这里把这点抛出来,后面在总结synchronized关键字的时候,再详细解释。
三、volatile之有序性
这里我们着重说两点,一个是上篇博文没有详细解释的happens-before(先行发生)原则,另一个是指令重排。
3.1 happens-before
首先,happens-before是Java中“先天”的有序性,它不需要任何同步手段保证,前面我们也提到了先行发生原则和时间先后顺序是没有直接联系的,该怎么理解这句话呢?现在有如下对象:
class Obj{
private int value = 0;
public void setValue(){
this.value = 1;
}
public void getValue(){
return value;
}
}
假设我们创建了一个obj实例,现在有A和B两个线程,它们会分别执行obj实例的setValue()和getValue()方法,并且A线程先调用了obj.setValue()方法,B线程后调用obj.getValue()方法,这里的操作是线程安全的吗?换句话说,B线程获取到的value值是1吗?我们用前面提到的先行发生原则来套一下:
首先,由于obj实例的setValue和getValue方法分别在不同的线程中执行,所以程序次序规则在这里不适用;而我们也没有使用任何的加锁措施,这里也就不会发生lock和unlock操作,所以管程锁定规则同样不适用;也没有使用volatile修饰,所以volatile变量规则不适用;更是和线程启动、终止、中断规则,对象终结规则没有什么关系;也不存在传递性的情况。所以我们断定这里的操作不是线程安全的,也就是我们并不能确定线程B获取到的value值是不是1。
上述的分析是根据先行发生原则推断的理论结果,那么实际上的情况呢?其实也很好理解,即使A线程先调用的setValue()方法,但是它不一定就能立即将value的最新值通过主内存反映到B线程中,所以我们不能确定B线程获取到的value值。
要解决这个问题其实也很简单,我们可以将setValue和getValue方法定义为synchronized方法(synchorinzed在后面总结),然后就符合我们的管程锁定规则了;或者把value变量增加volatile关键字修饰,就能满足volatile规则了。这两种方式都能实现先行发生关系。当然我们现在的重点是volatile,而使用volatile能达到目的的原因其实也就是我们前面提到的内容了。
3.2 指令重排
和前面一样,我们从一个可能由指令重排引发问题的一个实际场景开始:
public class Util {
private static Util instance;
public static Util getInstance() {
if (instance == null) {
synchronized (Util.class) {
if (instance == null) {
instance = new Util();
}
}
}
return instance;
}
public static void main(String[] args) {
Util.getInstance();
}
}
上述代码是一个典型的双重检测(double-check)实现单例模式的代码,相信大家都使用过,这里我们就不详细介绍了。为了获取单例对象,同时要避免每次获取实例都执行上锁/解锁操作,我们使用了双重检测机制,如果instance已经被初始化好了,那么则直接返回。但是上述代码没问题吗?
我们前面也提到过,Java里面的运算都是非原子的操作比如i++,这里的 instance = new Util();也并不是一个原子操作。这里我们不用看对应的JIT汇编输出,只需要看看字节码就足够了(省略了部分内容):
Code:
stack=2, locals=2, args_size=0
0: getstatic 2 // Field instance:Lcom/echat/loren/Util;
3: ifnonnull 37
6: ldc 3 // class com/echat/loren/Util
8: dup
9: astore_0
10: monitorenter
11: getstatic 2 // Field instance:Lcom/echat/loren/Util;
14: ifnonnull 27
17: new 3 // class com/echat/loren/Util
20: dup
21: invokespecial4 // Method "<init>":()V
24: putstatic 2 // Field instance:Lcom/echat/loren/Util;
27: aload_0
28: monitorexit
29: goto 37
32: astore_1
33: aload_0
34: monitorexit
35: aload_1
36: athrow
37: getstatic 2 // Field instance:Lcom/echat/loren/Util;
40: areturn
Exception table:
from to target type
11 29 32 any
32 35 32 any
首先我们站在虚拟机的角度简单描述一下对象的创建:当虚拟机遇到一条new指令的时候,首先会对指令的参数进行类加载检查,检查通过之后,该对象需要多大的内存空间是可以确定的,所以接下来就可以为该对象分配内存空间了,具体如何分配我们这里暂时不去深究;空间分配好了之后,虚拟机需要将除对象头外的其它内存空间都初始化零值,然后设置对象头的信息,像元数据、哈希码、GC分代年龄等等;然后需要执行对象的
对应到我们上面贴出的字节码信息,就对应了new、dup、invokespecial等等指令。我们目前只需要了解,一个简单的instance = new Util();操作,在大体上会涉及到分配内存、初始化内存、将内存地址设置到instance变量几个步骤。而初始化内存和将内存地址设置到instance变量两个操作是没有直接依赖关系的,对于单线程程序而言,谁先执行谁后执行是不会造成异常结果的,这两个操作也就可能会发生乱序:也就是在分配内存成功之后,首先将内存地址设置到了instance变量,然后再初始化内存。
我们提到了在单线程情况下,这样是不会有什么问题的,但是多线程情况下呢?初始状态instance变量为空,如果现在有一个线程A调用getInstance()方法,执行到了instance = new Util();这里,而这里发生了指令重排,实例对象的内存空间被分配之后就给了instance变量,并且将最新值同步回了主内存(对于普通共享变量而言,如果没有使用任何同步措施,工作内存中的值何时同步到主内存其实是“不明确的”,所以可能会出现提前可见的可能),接下来再去做内存空间的初始化操作。
但是在内存初始化之前,又有一个B线程调用了getInstance()方法,而这个时候instance变量已经不为空了,将会直接返回该变量,但是instance对应的内存空间还没有被初始化,实例的创建都还没有真正完成,这时候就把一个还初始化完成的对象提供给了调用者,明显就是有问题的,这就是一个不安全发布对象的情况。
指令重排的实质
那么指令重排的实质是什么呢?除了编译器的优化和CPU自身的优化之外。回到我们最开始提到的MESI缓存一致性协议。如果cpu(核心)1要修改share状态的数据,需要通过总线通知其它cpu(核心)2将对应的缓存修改为invalid状态,然后核心1会等待核心2的回执,再更新数据回缓存。但是这个总线上的通知和等待回执是有时间消耗的,等待的时候内核阻塞那岂不是不好了?
所以在内核和缓存之间引入了另一个叫做存储缓存(Store Buffer) 的区域,核心1计算数据之后,先将数据放到存储缓存中(延缓更新操作),然后通知核心2,这个时候,核心1就不用等待回执了,可以转而去执行其他指令,等到收到核心2的回执后再把存储缓存中的数据更新到缓存;同时,站在核心2的角度,它收到核心1发过来的invalid指令也不会立即响应,而是将指令存储在一个叫做无效队列(Invalid Queue) 的地方,然后立即响应核心1,核心2稍后再从这个队列中取出指令处理。这有点类似于生产消费模型。
正是因为这个区域的存在,可以实现内核不用等待一个指令执行完成,就转而去处理另外一个指令(当然前提是两者没有依赖关系),所以就表现出了另一种形式的指令重排。这种指令重排的本质不能简单的说是乱序执行,而是对于没有依赖关系的两个指令,其实没有严格按照:指令1开始执行->指令1执行完毕->指令2开始执行->指令2执行完毕,这种我们编码的既定顺序处理(想想连续两个rpc调用,能保证按照调用顺序返回吗)。
有了这个背景,也就好理解了,核心2由于没有立即响应invalid指令,所以在这期间,核心1对数据的修改其实没有让核心2立即感知到,也就有了可见性的问题。而后面提到的内存屏障能解决这个问题。
我们使用volatile之所以能解决指令重排带来的问题,在前面分析汇编的时候已经提到了,如果变量增加了volatile修饰,那么在变量赋值的操作后面会有一个lock前缀操作,这个lock前缀可以解决指令重排的问题,也能保证变量的更新对其它CPU立即可见。而这个lock前缀在这里也充当了一个内存屏障(Memory Barrier)的角色。
内存屏障
关于内存屏障,从意义上来说,它算是一个同步点,此点之前的所有读写操作都执行完之后才能执行此点之后的操作,指令重排不能把屏障之后的指令重排到屏障之前。
总的来将,内存屏障分为读屏障(Load Barrier)和写屏障(Store Barrier):
- 在读操作前插入读屏障,可以使缓存中数据失效,从主存中获取数据,对应到前面无效队列的情况:处理器在读数据之前,要先执行无效队列中的invalid指令,这样等到读数据的时候,发现数据失效了,就需要到主存获取最新数据
- 在写操作后插入写屏障,可以让最新数据立即写回主存,对应到前面存储缓存的情况:处理器在执行下一个指令之前,要先把存储缓存中的未执行的修改操作都执行完毕,也就实现了下个指令之前的更新操作全部执行完毕
在java中,内存屏障则分为四种,是上面两种读写屏障的组合,分别为:LoadLoad、LoadStore、StoreStore、StoreLoad。
内存屏障是一个底层的原语,在不同的CPU体系架构下差别可能很大,需要参考具体的硬件手册。java屏蔽了底层硬件架构的差异,对于不同的硬件架构会采取相对应的手段,我们上面的lock前缀加上一个空操作就是x86/x64结构的一种手段,只是这个空操作不能是nop指令,所以采取的操作是rsp寄存器加0。意思就是lock不是内存屏障,但是它能实现内存屏障的功能,它实现的功能就是写读屏障,同时具备读屏障和写屏障的特性。那么内存屏障是怎么实现禁止指令重排的呢?
指令重排是建立在正确处理依赖关系的前提下的。对于指令重排本身而言,一个操作如果要依赖一个值,那么这个值必须是正确的,所以在一个CPU内,即使发生了重排序,其结果也会是正确的(as-if-serial)。而我们使用lock前缀将修改同步到主内存时,就代表lock前缀之前的操作都已经执行完毕了,对应上面的例子,就不会出现其它线程获取到一个还没有初始化好的对象了。所以在其它CPU观测同一块内存的情况下,达到了指令重排无法越过内存屏障的效果。
四、volatile之原子性
我们都知道,volatile不能保证原子性,具体是什么意思呢?还是以i++的例子来进行说明。前面的文章已经不止一次提到了i++,它包含获取i、加一、赋值等操作,如果i是一个静态变量的话,那么涉及到的字节码就有:
getstatic
iconst_1
iadd
putstatic
如果我们现在没有任何同步措施,那么多个线程执行i++,是可能会出现并发问题的,简单的说就是可能会出现以下情况(假设i的初始值为1):
1> A线程从主存中读取了i的值,并且拷贝到自己的工作内存中,并执行了加一操作,此时副本2,但是并没有立即将2同步回主内存;
2> 然后B线程从主存中读取i的值,由于A线程并没有将自己的最新值刷新到主存,所以B线程此时获取的i值还是为1,然后加1的结果为2;
3> 然后A和B线程都把值刷新到主内存,最终结果为2
当然,i++能发生并发问题的不止上面这个情况,这里只是结合该情况分析volatile的效果而已。按照上面情况的描述,我们做了两次加一操作,但是结果却相当于做了一次加一。如果我们将变量i增加volatile修饰呢?这个时候能够保证B线程执行getstatic指令将最新的正确的i值取到操作栈顶,但是如果B线程将当前最新的i值取到了栈顶之后,接着正在执行iconst_1、iadd等指令的时候,其它线程更新了主存中i的值,这时B线程的操作栈顶的值就成了过期数据了,这样执行下去还是会出现并发问题。所以我们说volatile并不能保证原子性。
注:这里有的朋友可能会有疑问。我们前面提到了,volatile指令反应到JIT汇编使用了内存屏障,而屏障会让本Cache写入缓存,同时让其它CPU(内核)的Cache无效化(Invalid),就这样实现每次使用都从主存获取,每次更新都立即同步回主存的语义。那么既然会使其它缓存无效化,那么如果B线程执行到iadd等指令的时候,i的值被其它线程更新了,应该会让B线程中的缓存无效化啊?这样iadd指令就不会用过期数据去做操作了才对啊?这里我们需要注意的是,volatile只能保证getstatic指令会从主内存获取最新的i值,如果已经获取了i的值,将其取到了操作栈顶,那就会用获取到的值做运算了,但是我们再次调用getstatic指令的话,是能保证从主存获取最新值的,而不会出现从工作内存获取“旧”值的情况,因为工作内存中的值已经无效了。换句话说,如果没有volatile修饰,那么每次调用getstatic指令,我们并不能保证会从主存获取最新值,而可能直接从工作内存获取副本值。
五、使用场景
我们前面提到了volatile的特性,现在总结几条适合使用volatile的场景:
1、运算并不依赖变量的当前值
i++就是一个典型的依赖自身值的一个运算,如果我们的运算并不依赖自身的值,也就不会出现B线程先获取值,然后其它线程更新了最新值,接着B线程使用过期数据继续运算的情况了。比如i=1,就是简单的赋值操作而已。
2、只有单一的线程会修改变量的值
这个比较好理解,如果是单一线程修改变量,就不会出现并发更新,也就避免了并发更新的问题,而volatile也能保证更新的最新值能及时反映到其它线程中。
3、变量不需要和其它的状态变量共同参与不变约束
关于这段话,我的理解是:在理解这句话之前需要先明白什么叫做不变约束(不变式),不变约束表达的是一种对状态的约束,它可以在一定程度上表征特定的规则。比如,性别只能是男(1)或女(2):gender == 1 or gender == 2、年龄要大于0:age > 0。它其实就是一个条件表达式,而该表达式在模型的任何行为前后都成立。
我们设想一个条件表达式:a > b,表达式包含a和b两个变量,初始状态它们满足不变约束,比如a==9,b==8(9>8)。现在如果有一个线程A要更新a和b的值,当然更新的值也要满足不变约束,假设更新的结果为a==4,b==3,如下述代码所示:
public static volatile int a;
public static volatile int b;
public static void change(int newA,int newB){
a = newA;
b = newB;
}
//A线程调用更新a和b的值
change(4,3);
//B线程检查不变约束
a > b == true?
我们将变量a和变量b都增加了volatile修饰,现在A线程负责调用change方法更新a和b的值,B线程负责检查不变约束。初始状态,a==9,b==8,明显不变约束a>b没有被打破。现在A线程调用change(4,3),当执行了a = newA,但还没有执行b = newB的时候,B线程检查不变约束就已经出问题了:a变量被volatile修饰,当A线程将其更新为4之后就立即反馈到了B线程中,此时B线程“看到”a==4,但是b==8,明显不变约束a>b已经被打破了(现在a < b)。当然,这不能算作volatile引发的问题,我们如果不使用volatile,也不能够保证不变约束,只能说volatile解决不了这样的问题。
六、总结
对于volatile,我们要理解它的“原理”,明白它能解决什么问题,不能解决什么问题,才能在合适的场景下正确使用它。我们前文有提到,不同的CPU架构可能允许不同的重排规则,而对应这些规则也有相应的内存屏障类型,这在本文没有详细地进行总结,博主的想法是对于volatile,理解到这里对我们绝大多数人来说已经足够了,更多概念性的、更深层次的东西,大家结合自己的兴趣爱好做一定程度的研究就行。我们的初衷并不是要对这些技术挖掘到电信号的深度,而是为了以理解它为手段,达到能更好地运用它的目的。
参考:<<深入理解Java虚拟机>>
注:本文是博主的个人理解,如果有错误的地方,希望大家不吝指出,谢谢