上篇分析Service我们知道,在Service中主要涉及到Connector和Engine,我们先走Engine这条线,因为这涉及到tomcat内部工作机制,Connector是涉及到http与我们tomcat的连接,这个也是重点以后分析,这篇开始我们将进入Container系统组件,首先要看的Engine,下图是Engine的继承关系。
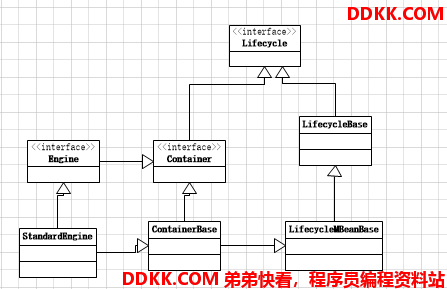
从上图可以比较清晰的看出StandardEngine的继承关系,所以看Engine组件之前,要大概的看下接口Container和抽象类ContainerBase。
Container接口主要方法:
//接口继承了Lifecycle接口
public interface Container extends Lifecycle {
//addChild事件,添加的listner可以监听
public static final String ADD_CHILD_EVENT = "addChild";
//addValve事件,这个valve是很重要的存在,将来分析tomcat执行http请求流程的时候会重点涉及到
public static final String ADD_VALVE_EVENT = "addValve";
// removeChild事件
public static final String REMOVE_CHILD_EVENT = "removeChild";
// removeValve事件
public static final String REMOVE_VALVE_EVENT = "removeValve";
………………………..
//这个Pipleline是valve的集合,将来分析tomcat解析请求的时候会重点分析
public Pipeline getPipeline();
//cluster涉及到集群,这个后面也会重点分析
public Cluster getCluster();
public void setCluster(Cluster cluster);
//BackgroundProcessorDelay 标记后台任务多久执行一次,如果为负数,child的backgroundProccess都不会被执行
public int getBackgroundProcessorDelay();
public void setBackgroundProcessorDelay(int delay);
………………….
//realm也是tomcat提供的一个机制,将来会重点分析
public Realm getRealm();
public void setRealm(Realm realm);
// --------------------------------------------------------- Public Methods
//执行一个周期性的任务在后台
public void backgroundProcess();
//下面都是跟child和listener相关的方法
public void addChild(Container child);
public void addContainerListener(ContainerListener listener);
public void addPropertyChangeListener(PropertyChangeListener listener);
public Container findChild(String name);
public Container[] findChildren();
public ContainerListener[] findContainerListeners();
public void removeChild(Container child);
public void removeContainerListener(ContainerListener listener);
public void removePropertyChangeListener(PropertyChangeListener listener);
public void fireContainerEvent(String type, Object data);
………….
//StartStopThreads?
public int getStartStopThreads();
public void setStartStopThreads(int startStopThreads);
…………..
}
ContainerBase 类:
从上面继承关系可以看出ContainerBase最终还是实现了LifeCycle,所以我们要重点看的是XXXXInternal几个回调方法,看源码可以发现很多addXXX,get/setXXX方法,从前面的分析我们可以知道这些基本上是Digester解析的时候需要调用的方法。
initInternal 方法:
//总的来说就是实例化startStopExecutor给后面的调用做准备
protected void initInternal() throws LifecycleException {
BlockingQueue<Runnable> startStopQueue = new LinkedBlockingQueue<>();
startStopExecutor = new ThreadPoolExecutor(
getStartStopThreadsInternal(),
getStartStopThreadsInternal(), 10, TimeUnit.SECONDS,
startStopQueue,
new StartStopThreadFactory(getName() + "-startStop-"));
startStopExecutor.allowCoreThreadTimeOut(true);
super.initInternal();
}
startInternal 方法:
// synchronized?
protected synchronized void startInternal() throws LifecycleException {
…………………
//获得Digester解析得到的Cluster,并启动
Cluster cluster = getClusterInternal();
if (cluster instanceof Lifecycle) {
((Lifecycle) cluster).start();
}
//获得Digester解析得到的Realm,并启动
Realm realm = getRealmInternal();
if (realm instanceof Lifecycle) {
((Lifecycle) realm).start();
}
//通过刚才实例化的Executor多线程的来启动child
Container children[] = findChildren();
List<Future<Void>> results = new ArrayList<>();
for (int i = 0; i < children.length; i++) {
results.add(startStopExecutor.submit(new StartChild(children[i])));
}
//利用Future特性进行失败处理
boolean fail = false;
for (Future<Void> result : results) {
try {
result.get();
} catch (Exception e) {
log.error(sm.getString("containerBase.threadedStartFailed"), e);
fail = true;
}
}
if (fail) {
throw new LifecycleException(
sm.getString("containerBase.threadedStartFailed"));
}
//启动pipleline中的valve
if (pipeline instanceof Lifecycle)
((Lifecycle) pipeline).start();
setState(LifecycleState.STARTING);
//后面分析
threadStart();
}
现在看下threadStart 方法:
protected void threadStart() {
if (thread != null)
return;
//当backgroundProcessorDelay为负数不进行线程调用
if (backgroundProcessorDelay <= 0)
return;
//重要标志,标记什么时候不执行ContainerBackgroundProcessor
threadDone = false;
//设置thread name,设置为Daemon线程,线程内容是ContainerBackgroundProcessor类,
String threadName = "ContainerBackgroundProcessor[" + toString() + "]";
thread = new Thread(new ContainerBackgroundProcessor(), threadName);
thread.setDaemon(true);
thread.start();
}
ContainerBackgroundProcessor类:
看源码可以知道处理的是子container的backgroundProcess方法。
stopInternal和destroyInternal方法就是相对应的按大概相反的顺序调用realm ,cluster相对应的stop 、destroy方法。
现在可以开始看Engine了,跟之前一样我们从Catalina的createStartDigester开始来看init过后StandardEngine的对象链以及Server.xml中关于Engine的配置。
上篇我们知道关于Engine的rule是EngineRuleSet。
EngineRuleSet 类:
重点是看addRuleInstances 方法
//解析到Engine标签的时候,创建StandardEngine对象
digester.addObjectCreate(prefix + "Engine",
"org.apache.catalina.core.StandardEngine",
"className");
//设置Engine标签相对应属性给StandardEngine对象
digester.addSetProperties(prefix + "Engine");
//如果Engine标签设置了engineConfigClass属性值,将实例化然后add给engine的LifeCyecleListener,没有设置就默认用EngineConfig类
digester.addRule(prefix + "Engine",
new LifecycleListenerRule
("org.apache.catalina.startup.EngineConfig",
"engineConfigClass"));
//调用Service的setContainer方法,参数为StandardEngine
digester.addSetNext(prefix + "Engine",
"setContainer",
"org.apache.catalina.Engine");
//解析到Engine/Cluster,通过标签上的className属性值实例化Cluster对象
digester.addObjectCreate(prefix + "Engine/Cluster",
null,
"className");
//设置Cluster标签上相对应的属性值进Cluster对象
digester.addSetProperties(prefix + "Engine/Cluster");
//调用Engine的setCluster方法,参数是Cluster对象
digester.addSetNext(prefix + "Engine/Cluster",
"setCluster",
"org.apache.catalina.Cluster");
//同之前解析Listener
digester.addObjectCreate(prefix + "Engine/Listener",
null, "className");
digester.addSetProperties(prefix + "Engine/Listener");
digester.addSetNext(prefix + "Engine/Listener",
"addLifecycleListener",
"org.apache.catalina.LifecycleListener");
//根据RealmRuleSet规则设置StandardEngine
digester.addRuleSet(new RealmRuleSet(prefix + "Engine/"));
//解析到Engine/Valve标签是通过标签上className属性创建valve对象
digester.addObjectCreate(prefix + "Engine/Valve",
null,
"className");
//设置标签上相对应属性进Valve
digester.addSetProperties(prefix + "Engine/Valve");
//调用StandardEngine上的addValve方法,参数是实现Valve的对象,这个Valve将添加进container的Pipeline,这个Pipeline是tomcat解析请求流程的重要一员,后面会详细分析。
digester.addSetNext(prefix + "Engine/Valve",
"addValve",
"org.apache.catalina.Valve");
跟之前一样,看StandardEngine ,主要关注XXXInternal几个方法,因为它同时也是Container,所以还要关注另外跟Container相关的方法
看具体方法之前我们先看下Engine接口
public interface Engine extends Container {
//Engine下默认的childhost
public String getDefaultHost();
public void setDefaultHost(String defaultHost);
//跟cluster相关的Engine都要有个jvmroute
public String getJvmRoute();
public void setJvmRoute(String jvmRouteId);
//我们的Service
public Service getService();
public void setService(Service service);
}
现在看StandardEngine 相关方法,观察源码,发现XXXInternal不是重点,重点是StandardEngine 的构造方法
public StandardEngine() {
super();
//设置pipleline的basicValve为StandardEngineValve,后面大概看下StandardEngineValve类,valve类主要是在处理请求的过程中发挥作用
pipeline.setBasic(new StandardEngineValve());
try {
//设置JvmRoute
setJvmRoute(System.getProperty("jvmRoute"));
} catch(Exception ex) {
log.warn(sm.getString("standardEngine.jvmRouteFail"));
}
//设置backgroundProcessorDelay为10,表明Engine会启动线程每隔10×1000 s 来调用它的child的backgroudProcess
backgroundProcessorDelay = 10;
}
initInternal 方法:
protected void initInternal() throws LifecycleException {
//确保realm被设置,如果没有配置,设置NullRealm
getRealm();
super.initInternal();
}
startInternal 方法:
protected synchronized void startInternal() throws LifecycleException {
//记log
if(log.isInfoEnabled())
log.info( "Starting Servlet Engine: " + ServerInfo.getServerInfo());
super.startInternal();
}
Valve和Pipeline有必要单独分析,涉及到tomcat请求流程的处理。
**总结:**这篇开始就进入了tomcat的相对核心的部分,新的Container继承链,跟Container相关的有几个重要的类,Valve和Pipeline、Cluster、Realm,都是tomcat提供的一些相对应的特性,后面会有单独分析,每个不同的Container重点在于他们想对应的Valve,渐渐进入核心,目前我们只关注tomcat的启动和停止,关于Valve和Pipeline的分析我们只是介绍方便后面Container的介绍,关于流程的处理后面会专门大篇幅分析,流程的处理的代码比较复杂。