一、Inline行表达式分片策略InlineShardingStrategy
使用Groovy的Inline表达式,提供对SQL语句中的=和IN的分片操作支持。
InlineShardingStrategy只支持单分片键
对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: tuser${user_id % 8} 表示t_user表按照user_id按8取模分成8个表,表名称为t_user_0到t_user_7
二、StandardShardingStrategy配置实现
Sharding -jdbc 在使用分片策略的时候,与分片算法是成对出现的,每种策略都对应一到两种分片算法(不分片策略NoneShardingStrategy除外)
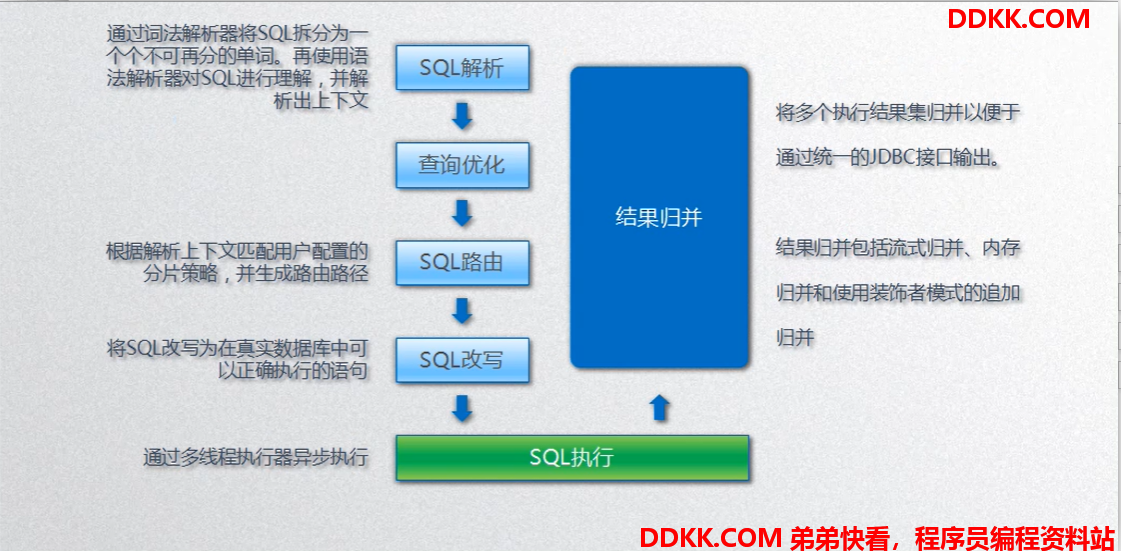
分库分表最核心的两点SQL 路由 、 SQL 改写
SQL 路由:解析原生SQL,确定需要使用哪些数据库,哪些数据表
Route (路由)引擎:为什么要用Route 引擎呢?
在实际查询当中,数据可能不只是存在一台MYSQL服务器上,
SELECT * FROM t_order WHERE order _id IN(1,3,6)
数据分布:
ds0.t_order0 (1,3,5,7)
ds1.t_order0(2,4,6)
这个SELECT 查询就需要走2个database,如果这个SQL原封不动的执行,肯定会报错(表不存在),Sharding-jdbc 必须要对这个sql进行改写,将库名和表名 2个路由加上
SELECT * FROM ds0.t_order0 WHERE order _id IN(1,3)
SELECT * FROM ds0.t_order1 WHERE order _id IN(6)
SQL 改写:将SQL 按照一定规则,重写FROM 的数据库和表名(Route 返回路由决定需要去哪些库表中执行SQL)
application.properties 配置
配置主要分为三个部分
1、 配置数据源;
2、 分库配置;
3、 分表配置;
数据源配置,有多少个数据库,就配置多少个数据源(库多的时候比较繁琐,可以采用数据治理),相比于Mycat 配置还是简单很多
数据源名字随意,但是配置数据源时必须名字能对应
sharding.jdbc.datasource.names=ds0,ds1
sharding.jdbc.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds0.url=jdbc:mysql://127.0.0.1:5306/ds0?useUnicode=yes&characterEncoding=utf8
sharding.jdbc.datasource.ds0.username=root
sharding.jdbc.datasource.ds0.password=root
sharding.jdbc.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds1.url=jdbc:mysql://127.0.0.1:5306/ds1?useUnicode=yes&characterEncoding=utf8
sharding.jdbc.datasource.ds1.username=root
sharding.jdbc.datasource.ds1.password=root
----------------------分库配置--------------------------
database-strategy.inline 库分片策略 + 指定分库的分片键
sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column=user_id
database-strategy.inline.algorithm-expression 分片算法表达式
sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression=ds$->{user_id % 2}
设置绑定表 t_order,t_order_item
sharding.jdbc.config.sharding.binding-tables=t_order,t_order_item
---------------------- t_order分表配置----------------------
t_order 分库分表后真实的数据节点(逻辑表 -> 真实表)
sharding.jdbc.config.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}
分片键设置
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order$->{order_id % 2}
主键生成 sharding jdbc 默认主键算法是 64位雪花算法
sharding.jdbc.config.sharding.tables.t_order.key-generator-class-name=io.shardingsphere.core.keygen.DefaultKeyGenerator
sharding.jdbc.config.sharding.tables.t_order.key-generator-column-name=id
---------------------- 绑定表t_order_item分表配置 ----------------------
sharding.jdbc.config.sharding.tables.t_order_item.actual-data-nodes=ds$->{0..1}.t_order_item$->{0..1}
分片键设置
sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.inline.algorithm-expression=t_order_item$->{order_id % 2}
定义广播表
sharding.jdbc.config.sharding.broadcast-tables=t_province
sharding.jdbc.config.props.sql.show=true