Sharding-jdbc 官方文档讲的不是很全面和清楚,学习的时候特意再记录补充下
官方文档地址:http://shardingsphere.apache.org/index_zh.html
一、解析引擎
如果在大学期间学习过计算机编程原理课程,SQL的解析是比较简单的。 不过,它依然是一门完善的编程语言,因此对SQL的语法进行解析,与解析其他编程语言(如:Java语言、C语言、Go语言等)并无本质区别。
SQL解析引擎在 parsing包下:
1、 Lexer:词法解析器;
2、 Parser:SQL解析器;
两者都是解析器,区别在于 Lexer只做词法的解析,不关注上下文。讲字符串拆解成N个词法,而Perser在 Lexer的基础上,还需要理解SQL再进行解析
1.1 语法树
解析过程分为词法解析和语法解析。 词法解析器用于将SQL拆解为不可再分的原子符号,称为Token。并根据不同数据库方言所提供的字典,将其归类为关键字,表达式,字面量和操作符。 再使用语法解析器将SQL转换为抽象语法树。
例如,以下SQL:
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18
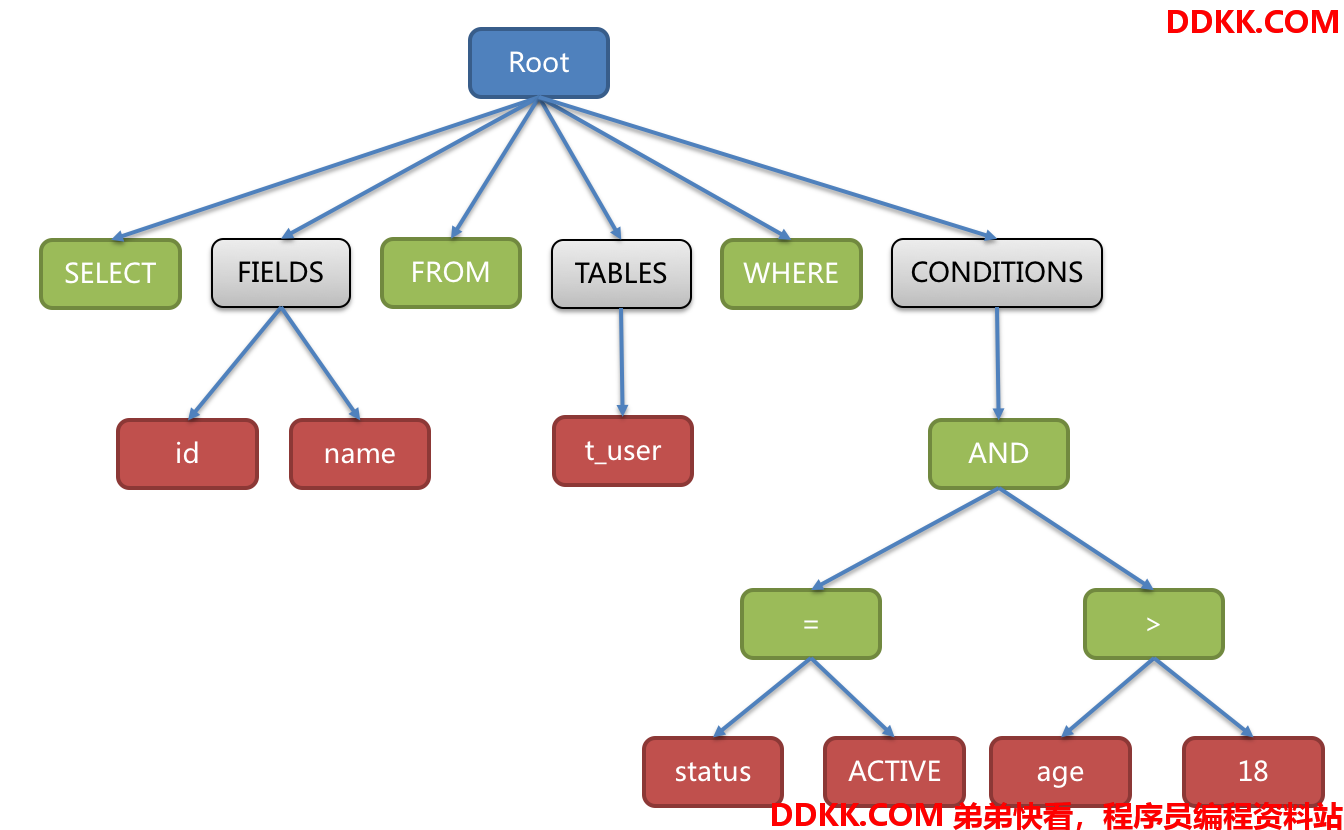
抽象语法树中的关键字的Token用绿色表示,变量的Token用红色表示,灰色表示需要进一步拆分。
最后,通过对抽象语法树的遍历去提炼分片所需的上下文,并标记有可能需要改写的位置。 供分片使用的解析上下文包含:
- 查询选择项(Select Items)
- 表信息(Table)
- 分片条件(Sharding Condition)
- 自增主键信息(Auto increment Primary Key)
- 排序信息(Order By)
- 分组信息(Group By)
- 分页信息(Limit、Rownum、Top)
SQL的一次解析过程是不可逆的,一个个Token的按SQL原本的顺序依次进行解析,性能很高。
二、Lexer词法解析器
Lexer 会按照循序解析SQL,将sql字符串分解成 N 个分词(token),且这个过程是不可逆的
Lexer类继承图
可以看出,当前sharding-jdbc支持的数据库就是H2、Oracle、PostgreSQL、Mysql、SQLServer
2.1 Token
token用于描述当前分解出的词法,包含3个属性:
1、 TokenTypetype:词法标记类型;
2、 Stringliterals:当前词法字面量;
3、 intendPosition:literals在SQL字符串中的位置(去除所有空格和注释);
TokenType 用于描述当前token的类型,分成 4 大类:
1、 DefaultKeyword:词法关键词;
已经定义了数据库的关键字,例如:SELECT 、FROM、WHERE、AND
2、 Literals:词法字面量标记;
sql分解出来的字符串实际值,例如关键字SELECT,table表名
3、 Symbol:词法符号标记;
Sql中的符号。例如 * 号,table1.name 中的点号,age,name中的逗号分隔符
4、 Assist:词法辅助标记;
Assist枚举只有2个属性,END和ERROR,END表示分解结束
Literals词法字面量标记,一共分成6种:
1、 IDENTIFIER:词法关键词;
2、 VARIABLE:变量;
3、 CHARS:字符串;
4、 HEX:十六进制;
5、 INT:整数;
6、 FLOAT:浮点数;
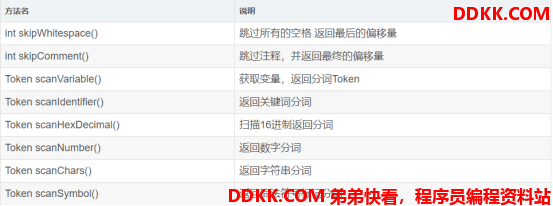
2.2 Tokenizer分词器
由于不同数据库遵守的 SQL 规范有所不同,所以不同的数据库对应存在不同的 Lexer实现,并且维护了各自对应的dictionary。
Sharding 会根据连接数据库的类型,选择相对应的Lexer实现类,并将对应的数据库词典覆盖父类Lexer的dictionary属性。Lexer内部根据相应数据库的dictionary与sql语句生成一个Tokenizer分词器进行分词。
public final class Tokenizer {
//SQL
private final String input;
//不同数据库对应的字典
private final Dictionary dictionary;
//偏移量
private final int offset;
}
分词器具体的方法如下:
2.3 Lexer分词核心实现代码
public class Lexer {
private final String input;
private final Dictionary dictionary;
private int offset;
private Token currentToken;
public final void nextToken() {
this.skipIgnoredToken();
if (this.isVariableBegin()) {
this.currentToken = (new Tokenizer(this.input, this.dictionary, this.offset)).scanVariable();
} else if (this.isNCharBegin()) {
this.currentToken = (new Tokenizer(this.input, this.dictionary, ++this.offset)).scanChars();
} else if (this.isIdentifierBegin()) {
this.currentToken = (new Tokenizer(this.input, this.dictionary, this.offset)).scanIdentifier();
} else if (this.isHexDecimalBegin()) {
this.currentToken = (new Tokenizer(this.input, this.dictionary, this.offset)).scanHexDecimal();
} else if (this.isNumberBegin()) {
this.currentToken = (new Tokenizer(this.input, this.dictionary, this.offset)).scanNumber();
} else if (this.isSymbolBegin()) {
this.currentToken = (new Tokenizer(this.input, this.dictionary, this.offset)).scanSymbol();
} else if (this.isCharsBegin()) {
this.currentToken = (new Tokenizer(this.input, this.dictionary, this.offset)).scanChars();
} else {
if (!this.isEnd()) {
throw new SQLParsingException(this, Assist.ERROR);
}
this.currentToken = new Token(Assist.END, "", this.offset);
}
this.offset = this.currentToken.getEndPosition();
}
总结:Lexer主要的执行逻辑就是 nextToken() 方法,不断解析出当前 Token。Lexer的nextToken()方法里,使用 skipIgnoredToken() 方法跳过空格和注释的部分,通过 isXxx() 方法判断好下一个 Token 的类型,交给 Tokenizer 进行分词并跟新偏移量后返回 Token。
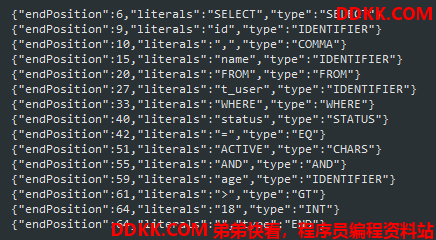
2.4 示例
@Test
public void lexerTest() {
String sql = "SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18";
MySQLLexer mySQLLexer = new MySQLLexer(sql);
boolean bool = true;
Token token;
do {
mySQLLexer.nextToken();
token = mySQLLexer.getCurrentToken();
System.out.println(JSONObject.toJSONString(token));
if (mySQLLexer.getCurrentToken().getType().toString().equals("END")) {
bool = false;
}
} while (bool);
}
三、Parser 语法解析器
Parser有三个组件
1、 SQLParsingengine:SQL解析引擎(掉用StatementParser解析SQL);
2、 SQLParser:SQL解析器(调用SQLParser解析SQL表达式);
3、 StatementParser:SQL语句解析(调用Lexer解析SQL词法解析器);
3.1 SQLParser 语法解析器
SQLParser 语法解析器,根据不同类型的语句有不同的语法解析器去解析成SQLStatement
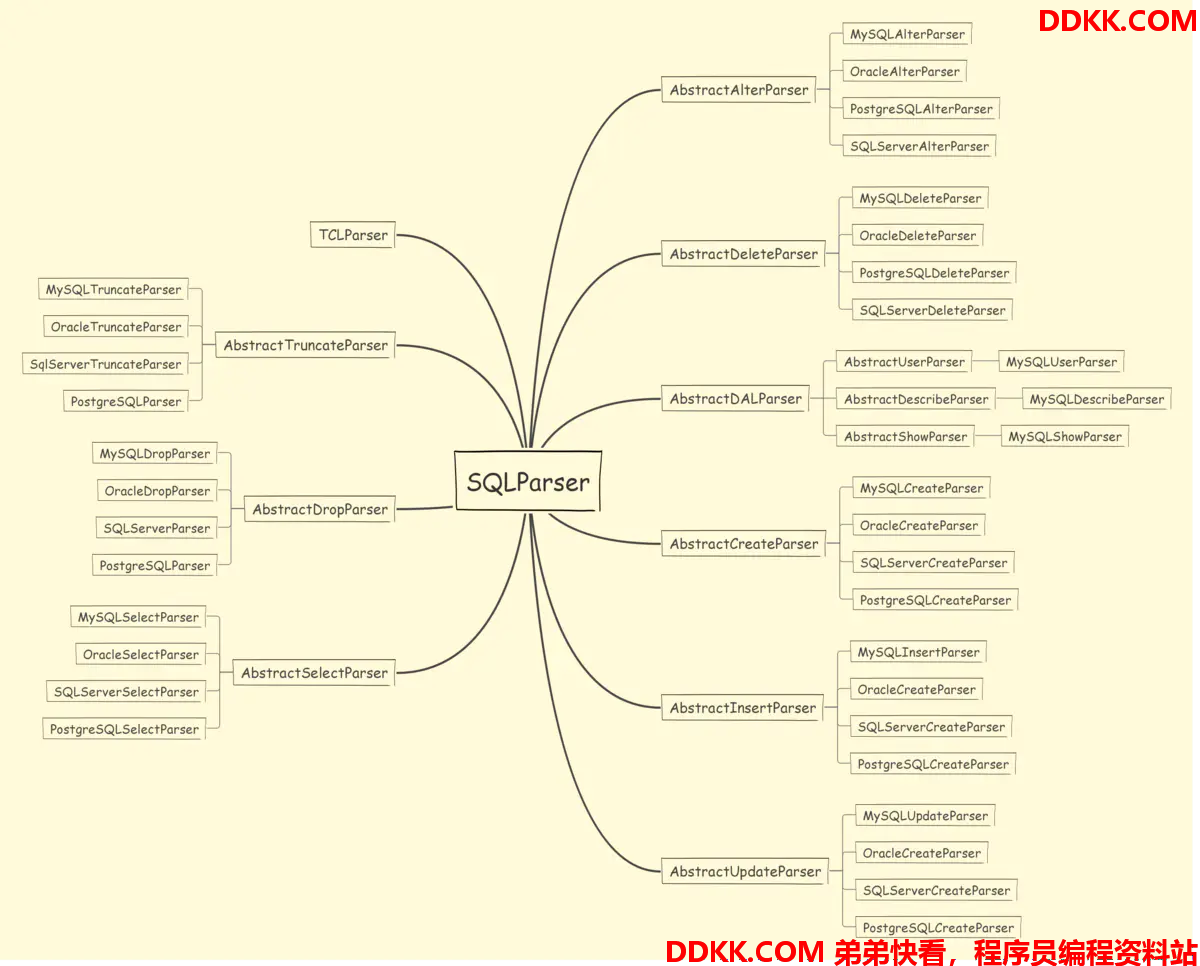
可以看到,不同类型的sql,不同厂商的数据库,存在不同的处理解析器去解析,解析完成之后,会将SQL解析成SQLStatement。
SQLParsingEngine类 ,sql的解析引擎,其 parse() 方法作为 SQL 解析入口,本身不带复杂逻辑,通过调用对应的 SQLParser 进行 SQL 解析,返回SQLStatement
public SQLStatement parse(boolean useCache) {
//ShardingSphere将使用PreparedStatement的SQL解析的语法树放入缓存。 因此建议采用PreparedStatement这种SQL预编译的方式提升性能。
Optional<SQLStatement> cachedSQLStatement = this.getSQLStatementFromCache(useCache);
if (cachedSQLStatement.isPresent()) {
return (SQLStatement)cachedSQLStatement.get();
} else {
//词法解析
LexerEngine lexerEngine = LexerEngineFactory.newInstance(this.dbType, this.sql);
//语法解析
SQLStatement result = SQLParserFactory.newInstance(this.dbType, this.shardingRule, lexerEngine, this.shardingTableMetaData, this.sql).parse();
if (useCache) {
ParsingResultCache.getInstance().put(this.sql, result);
}
return result;
}
}
SQLStatement对象是个超类,具体实现类有很多。按照不同的语句,解析成不同的SQLStatement。
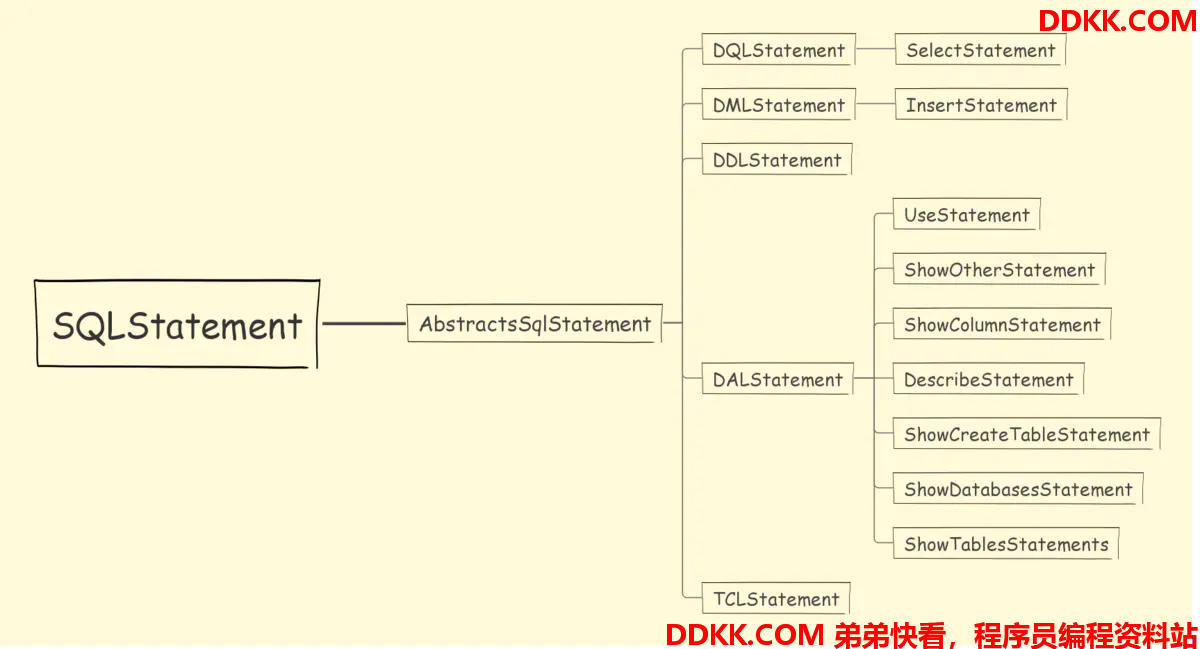
SQLStatement api:
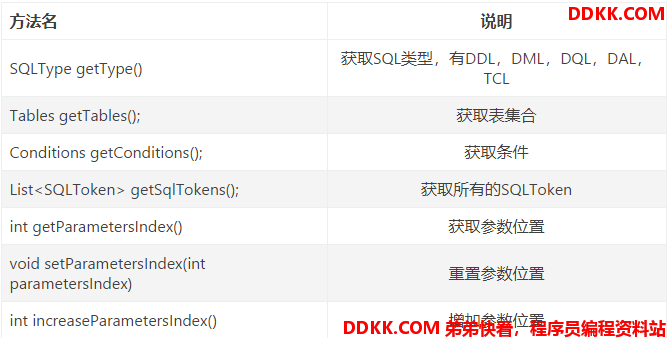
不同的语句,ddl,dml,tcl等,有不同的语法解析器SQLParser去解析,与词法分析器一样使用工厂模式,词法分析器Lexer在解析Sql的时候,第一个分词就是SQL的具体类型(select,update),所以在执行sql的时候,首先调用词法分析器解析第一个分词,再按照不同类型的SQL选择不同的语法解析器。根据数据库类型,DB类型分词解析器获取语法解析器。
public final class SQLParserFactory {
public static SQLParser newInstance(DatabaseType dbType, ShardingRule shardingRule, LexerEngine lexerEngine, ShardingTableMetaData shardingTableMetaData, String sql) {
lexerEngine.nextToken();
TokenType tokenType = lexerEngine.getCurrentToken().getType();
if (DQLStatement.isDQL(tokenType)) {
return (SQLParser)(DatabaseType.MySQL == dbType ? new AntlrParsingEngine(dbType, sql, shardingRule, shardingTableMetaData) : getDQLParser(dbType, shardingRule, lexerEngine, shardingTableMetaData));
} else if (DMLStatement.isDML(tokenType)) {
return getDMLParser(dbType, tokenType, shardingRule, lexerEngine, shardingTableMetaData);
} else if (TCLStatement.isTCL(tokenType)) {
return new AntlrParsingEngine(dbType, sql, shardingRule, shardingTableMetaData);
} else if (DALStatement.isDAL(tokenType)) {
return getDALParser(dbType, (Keyword)tokenType, shardingRule, lexerEngine);
} else {
lexerEngine.nextToken();
TokenType secondaryTokenType = lexerEngine.getCurrentToken().getType();
if (DCLStatement.isDCL(tokenType, secondaryTokenType)) {
return new AntlrParsingEngine(dbType, sql, shardingRule, shardingTableMetaData);
} else if (DDLStatement.isDDL(tokenType, secondaryTokenType)) {
return new AntlrParsingEngine(dbType, sql, shardingRule, shardingTableMetaData);
} else if (TCLStatement.isTCLUnsafe(dbType, tokenType, lexerEngine)) {
return new AntlrParsingEngine(dbType, sql, shardingRule, shardingTableMetaData);
} else if (DefaultKeyword.SET.equals(tokenType)) {
return SetParserFactory.newInstance();
} else {
throw new SQLParsingUnsupportedException(tokenType);
}
}
}
}
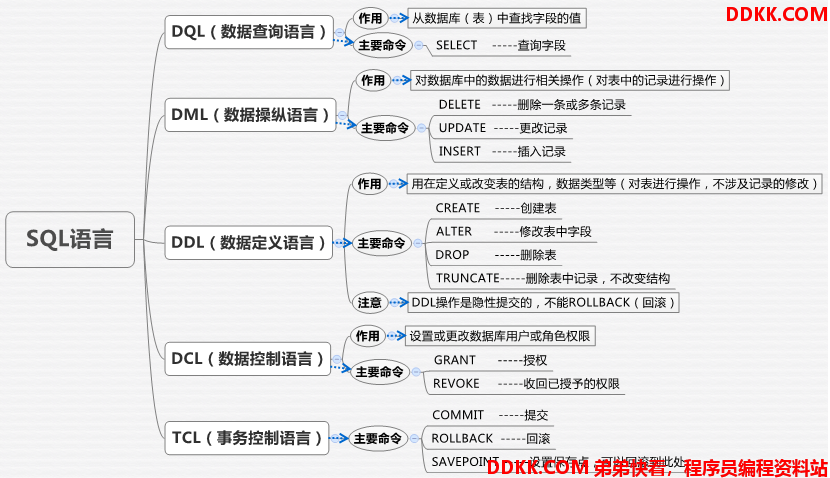
3.2 SQLParsingEngine
一条sql在执行的时候,如何知道是什么类型的语句??
词法分析器Lexer在解析Sql的时候,第一个分词就是SQL的具体类型(select,update),所以在执行sql的时候,首先调用词法分析器解析第一个分词,获取语句类型,然后选择具体的语法解析器解析。和分词器引擎一样,SQL语句解析器也有自己的解析引擎