一、 Sharding-JDBC主键
软件项目开发中,主键自动生成是基本需求。而各个数据库对于该需求也提供了相应的支持,比如:数据库自增( MySQL, Oracle等)。但在分布式环境中,分库分表之后,不同表生成全局唯一的Id是非常棘手的问题。因为同一个逻辑表内的不同实际表之间的自增键是无法互相感知的, 这样会造成重复Id的生成。我们当然可以通过约束表生成键的规则(设置不同的起始和步长)来达到数据的不重复,但是这需要引入额外的运维力量来解决重复性问题,如果数据库节点变更会使框架缺乏扩展性。
目前有许多第三方解决方案可以完美解决这个问题,如:
UUID/GUID(一般应用程序和数据库均支持)
Redis| increment
Mongo DB ObjectID(类似UUID的方式)
Zookeeper分布式锁
Twitter的 Snowflake(又名“雪花算法”)
Ticket server(数据库生存方式, Flick采用的就是这种方式)
而ShardingSphere不仅提供了内置的分布式主键生成器,例如UUID、 Snowflake。还抽离出分布式主键生成器的接口(io.shardingsphere.core.keygen.KeyGenerator),方便用户自行实现自定义的自增主键生成器。
二、Twitter的分布式自增ID算法Snowflake
雪花算法概述
有这么一种说法,自然界中并不存在两片完全一样的雪花的。每一片雪花都拥有自己漂亮独特的形状、独一无二。雪花算法也表示生成的ID如雪花般独一无二
snowflake算法是一款本地生成的(ID生成过程不依赖任何中间件,无网络通信),保证ID全局唯一,并且ID总体有序递增,
组成结构
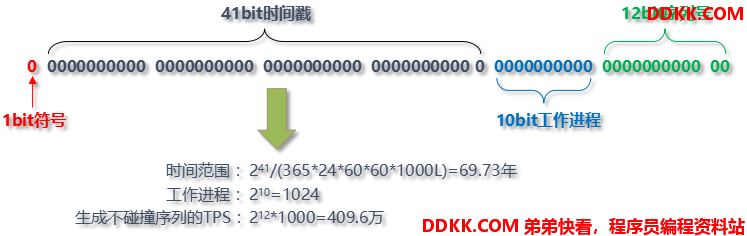
大致由:首位无效符、时间戳差值,机器(进程)编码,序列号四部分组成,雪花算法生成的ID是纯数字且具有时间顺序的。
- **1 bit:**不用,因为二进制里第一个 bit 为如果是 1,那么都是负数,但是我们生成的 id 都是正数,所以第一个 bit 统一都是 0
- **时间位:**可以根据时间进行排序,有助于提高查询速度。41 bit 可以表示的数字多达 2^41 - 1,也就是可以标识 2 ^ 41 - 1 个毫秒值,换算成年就是表示 69 年的时间。
- **机器id位:**适用于分布式环境下对多节点的各个节点进行标识,可以具体根据节点数和部署情况设计划分机器位10位长度,如划分5位表示进程位等,这个服务最多可以部署在 2^10 台机器上,也就是 1024 台机器。
- **序列号位:**是一系列的自增id,可以支持同一节点同一毫秒生成多个ID序号,12位的计数序列号支持每个节点每毫秒产生4096个ID序号
优点
1、 时间自增排序;
2、 适合分布式场景,整个分布式系统内不会产生ID碰撞(由datacenter和机器ID作区分)效率较高,一个节点每毫秒4096个ID序号,服务最大每毫秒409.6万个序列号;
缺点:
1、 雪花算法在单机系统上ID是递增的,但是在分布式系统多节点的情况下不是绝对递增,所有节点的时钟(System.currentTimeMillis())并不能保证不完全同步,所以有可能会出现不是全局递增的情况;
2、 不能在一台服务器上部署多个分布式ID服务;
3、 时钟回拨问题;
三、Sharding JDBC 使用Snowflake生成唯一主键ID
ShardingSphere 在分片规则配置模块可配置每个表的主键生成策略,默认使用为雪花算法(io.shardingsphere.core.keygen.DefaultKeyGenerator)
配置文件制定
主键生成 sharding jdbc 默认主键算法是 64位雪花算法
sharding.jdbc.config.sharding.tables.t_order.key-generator-class-name=io.shardingsphere.core.keygen.DefaultKeyGenerator
sharding.jdbc.config.sharding.tables.t_order.key-generator-column-name=id
使用DefaultKeyGenerator 类获取
DefaultKeyGenerator generator = new DefaultKeyGenerator();
generator.generateKey();
对Snowflake时钟回拨问题处理
private boolean waitTolerateTimeDifferenceIfNeed(long currentMilliseconds) throws Throwable {
try {
//lastMilliseconds 最后一次生成序列时间
if (this.lastMilliseconds <= currentMilliseconds) {
//如果lastMilliseconds
return false;
} else {
long timeDifferenceMilliseconds = this.lastMilliseconds - currentMilliseconds;
Preconditions.checkState(timeDifferenceMilliseconds < (long) maxTolerateTimeDifferenceMilliseconds,
"Clock is moving backwards, last time is %d milliseconds, current time is %d milliseconds",
new Object[]{this.lastMilliseconds, currentMilliseconds});
Thread.sleep(timeDifferenceMilliseconds);
return true;
}
} catch (Throwable var5) {
throw var5;
}
}

服务器时钟回拨会导致产生重复序列,因此默认分布式主键生成器提供了一个最大容忍的时钟回拨毫秒数。如果时钟回拨的时间超过最大容忍的毫秒数值,则程序报错;如果在可容忍的范围内,默认分布式主键生成器会等待(Thread.sleep)时钟同步到最后一次主键生成的时间后再继续工作。最大咨忍的时钟回拨室秒数的默认值为0,可通过调用静态方法 Defaultkey Generator setMaxTolerate Time DifferenceMilliseconds设置
生成主键实现理解
public synchronized Number generateKey() {
long currentMilliseconds = timeService.getCurrentMillis();
if (this.waitTolerateTimeDifferenceIfNeed(currentMilliseconds)) {
currentMilliseconds = timeService.getCurrentMillis();
}
if (this.lastMilliseconds == currentMilliseconds) {
if (0L == (this.sequence = this.sequence + 1L & 4095L)) {
currentMilliseconds = this.waitUntilNextTime(currentMilliseconds);
}
} else {
this.vibrateSequenceOffset();
this.sequence = (long)this.sequenceOffset;
}
this.lastMilliseconds = currentMilliseconds;
return currentMilliseconds - EPOCH << 22 | workerId << 12 | this.sequence;
}
核心代码如下,几个实现的关键点:
- synchronized保证线程安全;
- 如果出现时间回拨,判断时钟回拨的时间是否超过最大容忍的毫秒数值,如果超过抛出异常;
- 如果当前时间和上一次是同一秒时间,那么sequence自增。如果同一秒内sequence自增值超过2^13-1,那么就会自旋等待下一秒(getNextSecond);
- 如果是新的一秒,那么sequence重新从0开始;