一、分库分表产生问题的原因
当系统数据库达到一定的量级,单数据库实例已经无法支撑的时候,我们就要考虑采用分库分表的策略了.那么进行数据分库分表后会
带来哪些影响呢?
1.1 垂直拆分的影响
1、 单机ACID打破了;
2、 一些Join操作变得困难;
3、 外键约束的场景受影响;
1.2 水平拆分的影响
1、 单机ACID打破了;
2、 一些Join操作变得困难;
3、 外键约束的场景受影响;
4、 依赖单库的自增序列生成id受影响;
5、 逻辑意义上的单表查询可能要跨库;
二、分库分表带来的难点问题
2.1 分布式全局唯一ID
在很多中小项目中,我们往往直接使用数据库自增特性来生成主键ID,这样确实比较简单。而在分库分表的环境中,数据分布在不同的分片上,如果每个分片都采用原有的主键自增策略。不可避免的会造成主键ID重复。简单介绍下使用和了解过的几种ID生成算法。
方案一 :设置主键自增id 的起始和步长
ds0.t_user 设置主键id 自动增长 起始1 步长2 -->> 1,3,5,7,9...
ds1.t_user 设置主键id 自动增长 起始2 步长2 -->> 2,4,6,8,10...
多少个库步长就为分库的数量
缺点:
1、 不利于扩展,新增库之后要维护所有表的自动增长步长,;
2、 中小型使用自增序列,但是大型项目不使用;
方案二 :UUID/GUID
优点:
1、 好处就是本地生成,不要基于数据库;
缺点:
1、 UUID使用字符串形式存储、太长占用空间大,作为主键性能太差了;
2、 UUID不具有有序性,会导致B+树索引在写的时候有过多的随机写操作(连续的ID可以产生部分顺序写),还有,由于在写的时候不能产生有顺序的append操作,而需要进行insert操作,将会读取整个B+树节点到内存,在插入这条记录后会将整个节点写回磁盘,这种操作在记录占用空间比较大的情况下,性能下降明显;
3、 采用无意义字符串,区别于SKUID,没有任何业务上体现(淘宝,京东等商品的SKUID包含商品的信息);
方案三 :Twitter的分布式自增ID算法Snowflake
雪花算法概述
有这么一种说法,自然界中并不存在两片完全一样的雪花的。每一片雪花都拥有自己漂亮独特的形状、独一无二。雪花算法也表示生成的ID如雪花般独一无二。
组成结构
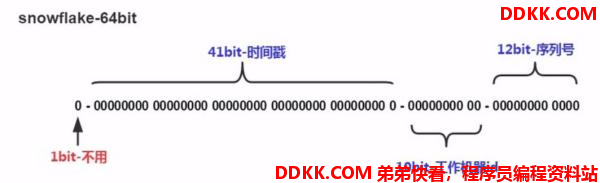
大致由:首位无效符、时间戳差值,机器(进程)编码,序列号四部分组成,雪花算法生成的ID是纯数字且具有时间顺序的。
- 时间位:可以根据时间进行排序,有助于提高查询速度。
- 机器id位:适用于分布式环境下对多节点的各个节点进行标识,可以具体根据节点数和部署情况设计划分机器位10位长度,如划分5位表示进程位等
- 序列号位:是一系列的自增id,可以支持同一节点同一毫秒生成多个ID序号,12位的计数序列号支持每个节点每毫秒产生4096个ID序号
优点:
1、 时间自增排序;
2、 适合分布式场景,整个分布式系统内不会产生ID碰撞(由datacenter和机器ID作区分);
3、 效率较高,每毫秒4096个ID序号;
缺点:
雪花算法在单机系统上ID是递增的,但是在分布式系统多节点的情况下,所有节点的时钟并不能保证不完全同步,所以有可能会出现不是全局递增的情况
简单配置实现
/zhuanlan/sharding/shardingjdbc/2/8.html
方案四:Redis Increment
incr可以用作计数器模式,它是原子自增操作
方案五:Zookeeper 分布式事务锁
方案六:MongoDB ObjectID(类似于UUID)
方案七:Ticket Server (数据库生成方式,Flickr采用这种方式)
2.2 常见分片规则
存储的规则
- 随机分片:hashcode 取模 (user_id % 片数量 ,取模结果为 0 ,insert t_user0,取模结果为 1,insert t_user1)
- 连续分片: 时间范围,int ,可能会造成数据倾斜(每个库数据量不平衡)
根据业务需求来决定分片键 ,在业务之初分片键确定之后一般情况不更换,如果更换,对数据迁移,数据维护 非常的麻烦
2.3 常见分片策略
Sharding-JDBC中的分片策略有两个维度:
- 数据源分片策略(DatabaseShardingStrategy):数据被分配的目标数据源
- 表分片策略(TableShardingStrategy):数据被分配的目标表
- 两种分片策略API完全相同,但是表分片策略是依赖于数据源分片策略的(即:先分库,然后才有分表)

Sharding分片策略继承自ShardingStrategy,提供了5种分片策略。
io.shardingsphere.core.routing.strategy.ShardingStrategy
--io.shardingsphere.core.routing.strategy.standard.StandardShardingStrategy
--io.shardingsphere.core.routing.strategy.standard.ComplexShardingStrategy
--io.shardingsphere.core.routing.strategy.standard.InlineShardingStrategy
--io.shardingsphere.core.routing.strategy.standard.HintShardingStrategy
--io.shardingsphere.core.routing.strategy.standard.NoneShardingStrategy
由于分片算法和业务实现紧密相关,因此Sharding-JDBC并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
分策策略一:标准分片策略StandardShardingStrategy
简单配置实现链接:/zhuanlan/sharding/shardingjdbc/2/4.html
- 提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持
- StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm(精准分片)和RangeShardingAlgorithm(范围分片)两个分片算法
- PreciseShardingAlgorithm是必选的,用于处理=和IN的分片
- RangeShardingAlgorithm是可选的,用于处理BETWEEN AND分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理
- 如果需要使用RangeShardingAlgorithm,必须和PreciseShardingAlgorithm配套使用
分片策略二:复合分片策略ComplexShardingStrategy
简单配置实现链接:/zhuanlan/sharding/shardingjdbc/2/6.html
- 提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持
- ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此Sharding-JDBC并未做过多的封装,而是直接将分片键值组合以及分片操作符交于算法接口,完全由应用开发者实现,提供最大的灵活度
分片策略三:Inline表达式分片策略InlineShardingStrategy
简单配置实现链接:/zhuanlan/sharding/shardingjdbc/2/5.html
- 使用Groovy的Inline表达式,提供对SQL语句中的=和IN的分片操作支持。
- 只支持单分片键
- InlineShardingStrategy只支持单分片键,对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: tuser
${user_id % 8} 表示t_user表按照user_id按8取模分成8个表,表名称为t_user_0到t_user_7
分片策略四:Hint分片HintShardingStrategy
简单配置实现链接:/zhuanlan/sharding/shardingjdbc/2/7.html
在分库分区中,有些特定的SQL,Sharding-jdbc、Mycat、Vitess都不支持(可以查看相关文档各自对哪些SQL不支持),例如:insert into table1 select * from table2 where ....这种SQL 路由很麻烦,需要解析table2的路由(是在ds0 /ds1 table2_0/table_1),结果集归并,insert 语句也需要同样的路由解析。这种情况Sharding-jdbc可以使用Hint分片策略来实现各种Sharding-jdbc不支持语法的限制
- 通过Hint而非SQL解析的方式分片的策略。对于分片字段非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段
- Hint分片策略是绕过SQL解析的,所以对于这些比较复杂的需要分片的查询,采用Hint分片策略性能可能会更好
- 在读写分离数据库中,Hint 可以通过HintManager.setMasterRouteOnly()方法,强制读主库(主从复制存在一定延时,但在某些特定的业务场景中,可能更需要保证数据的实时性)
分片策略五:NoneShardingStrategy
不分片的策略。和直接不使用Sharding-JDBC 效果相同
2.4 分片算法
Sharding提供了以下4种算法接口:
- PreciseShardingAlgorithm:精确分片算法,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
- RangeShardingAlgorithm:范围分片算法用于处理使用单一键作为分片键的BETWEEN AND进行分片的场景。需要配合StandardShardingStrategy使用。如果需要使用RangeShardingAlgorithm,必须和PreciseShardingAlgorithm配套使用,否则会报错
- HintShardingAlgorithm:Hint分片算法
- ComplexKeysShardingAlgorithm:复合分片算法
2.3 跨分片技术问题
2.3.1 跨分页的排序分页
跨节点多库进行查询时,会出现limit分页、order by排序等问题
分页需要按照指定字段进行排序当排序字段就是分片字段时,通过分片规则就比较容易定位到指定的分片。
当排序字段非分片字段时,就变得比较复杂。各分片节点中的数据可能是随机的,为了排序的准确性,必须把所有分片节点的前N页数据都排序好后做合并,最后再进行整体的排序。很显然,这样的操作是比较消耗资源的,用户越往后翻页,系统性能将会越差。
例如:现有db0.t_user0 ,db1.t_user1 ,db2.t_user2 三张表
select id from t__user where id < 10 order by id limit 0,2
每张表的数据:
db0.t_user0 1,4,7
db1.t_user1 5,2,8
db2.t_user2 9,6,3
必须要对db0.t_user0 ,db1.t_user1 ,db2.t_user2 三张表进行排序,然后合并为结果 1,4,7,2,5,8,3,6,9 ,再对合并的结果排序分页
2.3.2 跨分页的函数处理
在使用Max、Min、Sum、Count之类的函数进行统计和计算的时候,需要先在每个分片数据源上执行相应的函数处理,然后再将各个结果集进行二次处理
2.3.3 跨分片join
Join是关系型数据库中最常用的特性,但是在分片集群中,join也变得非常复杂(这种场景,比上面的跨分片分页更加复杂,而且对性能的影响很大),应该采取尽量避免跨分片的join查询。在分库分表中,尽量减少跨库的join,基本上所有的组件都不提供跨库join的功能,目前没有好的办法去解决
a)全局表
全局表(等同于维度表,例如省份表,城市表,名族表等),使用的是空间换时间的思想,每个db数据库上都存在一张相同数据的表,维护同步
b) ER表
在关系型数据库中,表之间往往存在一些关联的关系。如果我们可以先确定好关联关系,并将那些存在关联关系的表记录存放在同一个分片上,那么就能很好的避免跨分片join问题
2.4 跨分片事务问题
跨分片事务也叫分布式事务,想要了解分布式事务,就需要了解“XA接口”和“两阶段提交”。值得提到的是,MySQL5.5x和5.6x中的xa支持是存在问题的,会导致主从数据不一致。直到5.7x版本中才得到修复。Java应用程序可以采用Atomikos框架来实现XA事务(J2EE中JTA)
三、Sharding JDBC 概念
真实表
如果t_user 表分库分表之后四张表(ds0.t_user0、ds0.t_user1、ds1.t_user0、ds1.t_user1)
在sharding-jdbc 查询时:直接select * from t_user where age =18 ,shardig-jdbc回去查询四张表中符合的数据,对于程序代码sql 中t_user 是逻辑表,并不存在,而 ds0.t_user0、ds0.t_user1、ds1.t_user0、ds1.t_user1 是存放了数据并且存在的真实表(可以参考接口和实现类,接口不能不能被实例化)
广播表
也就是上面的 2.3.3中的全局表
绑定表
sharding-jdbc使用绑定表名称,Mycat使用ER表名称
例如
主表-> t_person_main(id,name,age,qq_level);
子表-> t_person_detail (id,gender,address,phone_num,e-mail,city_id);
如果主表id = 1 分表时在ds0,子表id=1 在ds1 。
Select * from t_person_main as mian left join t_person_detail as detail on mian .id = detail .id where mian .id=1;查询时就需要跨库join.
sharding-jdbc 使用绑定表解决跨库join ,判断相关联的数据插入时是否在同一个库,例如 t_person_main id=1在ds0上,那么t_person_detail id=1 就不会插入到ds1上,保障主表和子表相同数据在同一个库中。出现上面id相同不同库的情况, join时也不会去其他的库上查找数据。避免跨库join
四、系统是否分库分表分析
mysql单表经验
- 300W Mysql 可以轻松抗住
- 600 W 数据开始卡,优化可以解决(表结构,索引设计)
- 800W ~ 1000W 牛逼的DBA 优化都会遇到瓶颈
一般MySQL单表1000W左右的数据是可以不需要考虑分表的。当然,除了考虑当前的数据量和性能情况时,我们需要提前考虑系统半年到一年左右的业务增长情况。但是要避免过度设计(考虑了很多未来几年的需求。例如一张表在未来几年内 数据预计会达到几千万(存在很多的不确定性))
根据数据量增长速度,选择实现步骤
第一步:不分库不分表
第二步:同库内的分表
第三步:分库分表
不要过度设计,一上来玩大的就进行分库分表
分库如果多个实例存在同一台服务器上,只是解决了数据库最大连接数的问题
但是io(数据库数据是存储在硬盘上,每次获取都需要去硬盘把数据捞出来),cpu 等服务器资源瓶颈并没有解决。数据库的性能取决于服务器等性能