Spark是什么?
Apache Spark是用于大规模数据处理的统一分析引擎,是一种通用的大数据计算框架,如传统的大数据技术:Hadoop的MapReduce、Hive引擎,以及Storm流式实时计算引擎等。
Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量硬件之上,形成集群。
Spark包含了大数据领域常见的各种计算框架:比如Spark Core用于离线计算,Spark SQL用于交互式查询,Spark Streaming用于实时流计算,Spark MLlib用于机器学习,Spark GraphX用于图计算。
Spark主要用于大数据的计算,而Hadoop主要用于大数据的存储(比如HDFS、Hive、HBase等),以及资源调度(Yarn)。
Spark+Hadoop的组合,是大数据领域最热门的组合,也是最有前景的组合!
官网
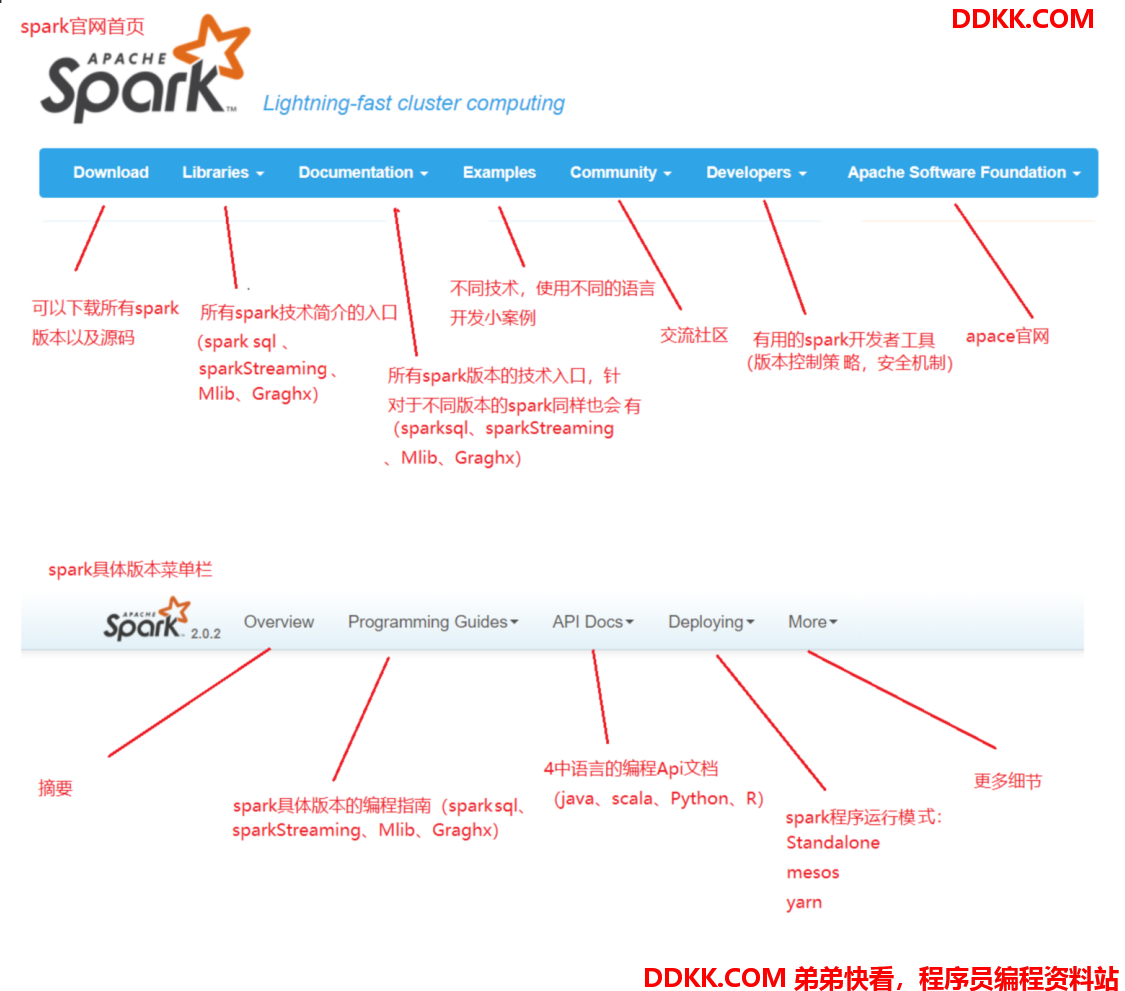
Spark的介绍
Spark,是一种"One Stack to rule them all"的大数据计算框架,期望使用一个技术堆栈就完美地解决大数据领域的各种计算任务。Apache官方,对Spark的定义就是:通用的大数据快速处理引擎。
Spark使用Spark RDD、Spark SQL、Spark Streaming、MLlib、GraphX成功解决了大数据领域中,离线批处理、交互式查询、实时流计算、机器学习与图计算等最重要的任务和问题。
Spark除了一站式的特点之外,另外一个最重要的特点,就是基于内存进行计算,从而让它的速度可以达到MapReduce、Hive的数倍甚至数十倍!
现在很多大公司都在生产环境下深度地使用Spark作为大数据计的计算框架,包括eBay、BAT、网易、京东、华为、大众点评、优酷土豆、搜狗等等。
Spark同时也获得了多个世界顶级IT厂商的支持,包括IBM、Intel等。
Spark的整体架构
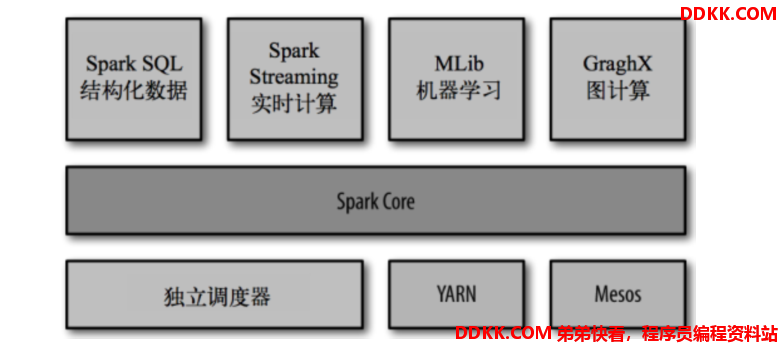
目前,Spark已经发展成为一个包含多个子项目的集合,其中包含Spark SQL、Spark Streaming、GraphX、MLlib等子项目。
- Spark Core:实现了Spark 的基本功能,包含RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。
- Spark SQL:Spark用来操作结构树数据的程序包。通过Spark SQL,可以使用SQL操作数据。
- Spark Streaming:Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API。
- Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同、过滤等,还提供了模型评估、数据导入等额外的支持功能。
- GraphX(图计算):Spark中用于图计算的API,性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
Spark的历史
Spark是当今大数据领域最活跃、最热门、最搞笑的大数据通用计算平台。
- 2009年诞生于美国加州大学伯克利分销AMP实验室。
- 2010年通过BSD许可协议开源发布
- 2013年捐赠给Apache软件基金会并切换开源协议到切换许可协议至Apache2.0 。进入高速发展期,第三方开发者贡献了大量的代码,活跃度非常高。
- 2014年2月,Spark成为Apache的顶级项目
- 2014年11月,Spark的母公司Databricks团队使用Spark刷新数据排序世界纪录
- 2015年~,Spark在国内IT行业变得愈发火爆,大量的公司开始重点部署或者使用Spark来替代MapReduce、Hive、Storm等传统的大数据计算框架。
Spark的特点
- 速度快:Spark基于内存进行计算(当然也有部分计算基于磁盘,比如shuffle),与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG(有向无环)执行引擎,可以通过基于内存来高效处理数据流。
- 易用(容易上手开发):MapReduce只支持一种计算(算法),Spark支持多种算法。Spark的基于RDD的计算模型,比如Hadoop的基于Map-Reduce的计算模型要更加易于理解,更加易于上手开发,实现各种复杂功能,比如二次排序,TopN等复杂操作时,更加便捷。支持Java、Python、R和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来盐城解决问题的方法。
- 通用:Spark提供了统一的解决方案。Spark可以用于批处理(Spark RDD)、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)等技术组件。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
- 集成Hadoop:Spark并不是要称为一个大数据领域的"独裁者",一个人霸占大数据领域的所有"地盘",而是与Hadoop进行了高度的集成,两者可以完美的配合使用。Hadoop的HDFS、Hive、HBase负责存储,YARN负责资源调度;Spark负责大数据计算。实际上。Hadoop+Spark的组合,是一种"double win"的组合。
- 兼容性:Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。
- 极高的活跃度:Spark目前是Apache基金会的顶级项目,全世界有大量的优秀工程师是Spark的committer。并且世界上很多顶级的IT公司都在大规模地使用Spark。
Spark为什么会流行?
原因1:优秀的数据模型和计算抽象
- 支持多种计算模型,而且基于内存(内存比硬盘速度更快)
- RDD 是一个可以容错且并行的数据结构
Spark 产生之前,已经有MapReduce这类非常成熟的计算系统存在了,并提供了高层次的API(map/reduce),把计算运行在集群中并提供容错能力,从而实现分布式计算。
虽然MapReduce提供了对数据访问和计算的抽象,但是对于数据的复用就是简单的将中间数据写到一个稳定的文件系统中(例如HDFS),所以会产生数据的复制备份,磁盘的I/O以及数据的序列化,所以在遇到需要在多个计算之间复用中间结果的操作时效率就会非常的低。而这类操作是非常常见的,例如迭代式计算,交互式数据挖掘,图计算等。
认识到这个问题后,学术界的 AMPLab 提出了一个新的模型,叫做 RDD。RDD 是一个可以容错且并行的数据结构(其实可以理解成分布式的集合,操作起来和操作本地集合一样简单),它可以让用户显式的将中间结果数据集保存在内存中,并且通过控制数据集的分区来达到数据存放处理最优化.同时 RDD也提供了丰富的 API (map、reduce、foreach、redeceByKey…)来操作数据集。后来 RDD被 AMPLab 在一个叫做 Spark 的框架中提供并开源.
简而言之,Spark 借鉴了 MapReduce 思想发展而来,保留了其分布式并行计算的优点并改进了其明显的缺陷。让中间数据存储在内存中提高了运行速度、并提供丰富的操作数据的API提高了开发速度。
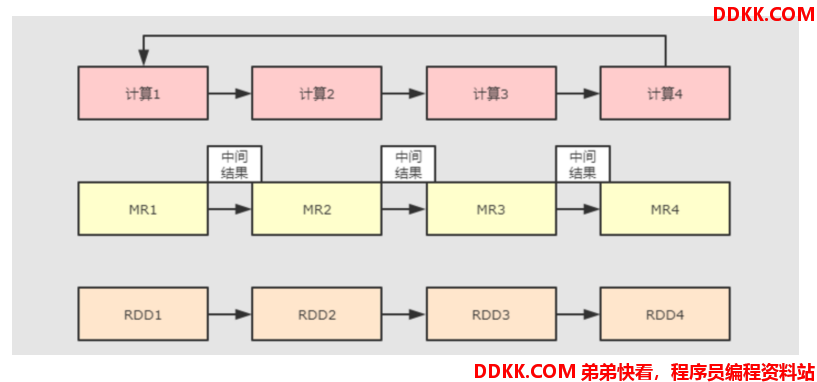
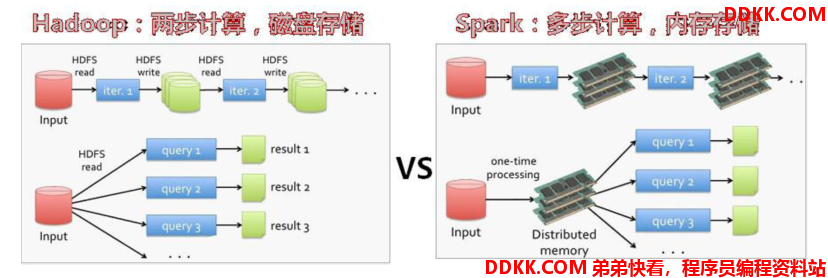
原因2:完善的生态圈
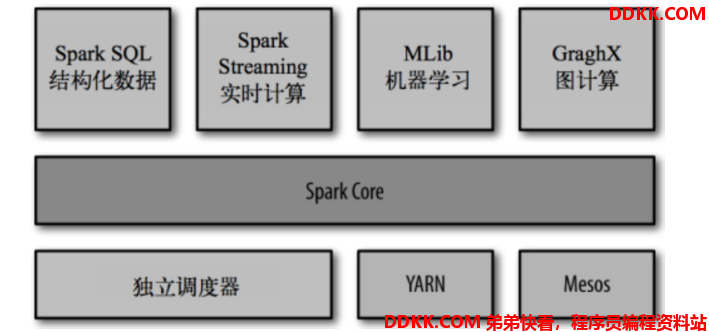
- Spark Core:实现Spark的基本功能(RDD)
- Spark SQL:操作结构化数据
- Spark Streaming:对实时数据进行流式计算
- Spark MLlib:机器学习(ML)功能
- GraphX:用于图计算的API
Spark的运行模式
local本地模式(单机)--开发测试使用
分为local单线程和local-cluster多线程
standalone独立集群模式--开发测试使用
典型的Mater/slave模式
standalone-HA高可用模式--生产环境使用
基于standalone模式,使用zk搭建高可用,避免Master是有单点故障的
on yarn集群模式--生产环境使用
运行在 yarn 集群之上,由 yarn 负责资源管理,Spark 负责任务调度和计算,
好处:计算资源按需伸缩,集群利用率高,共享底层存储,避免数据跨集群迁移。
FIFO
Fair
Capacity
on mesos集群模式--国内使用较少
运行在 mesos 资源管理器框架之上,
由 mesos 负责资源管理,
Spark 负责任务调度和计算
on cloud集群模式--中小公司未来会更多的使用云服务
比如 AWS 的 EC2,使用这个模式能很方便的访问 Amazon的 S3