partitionBy案例
作用:对pairRDD进行分区操作,如果原有的partionRDD和现有的partionRDD是一致的话就不进行分区, 否则会生成ShuffleRDD,即会产生shuffle过程。
需求:创建一个4个分区的RDD,对其重新分区
(1)创建一个RDD
scala> val rdd = sc.parallelize(Array((1,"aaa"),(2,"bbb"),(3,"ccc"),(4,"ddd")),4)
rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[44] at parallelize at <console>:24
(2)查看RDD的分区数
scala> rdd.partitions.size
res24: Int = 4
(3)对RDD重新分区
scala> var rdd2 = rdd.partitionBy(new org.apache.spark.HashPartitioner(2))
rdd2: org.apache.spark.rdd.RDD[(Int, String)] = ShuffledRDD[45] at partitionBy at <console>:26
(4)查看新RDD的分区数
scala> rdd2.partitions.size
res25: Int = 2
groupByKey案例
作用:groupByKey也是对每个key进行操作,但只生成一个sequence。
需求:创建一个pairRDD,将相同key对应值聚合到一个sequence中,并计算相同key对应值的相加结果。
(1)创建一个pairRDD
scala> val words = Array("one", "two", "two", "three", "three", "three")
words: Array[String] = Array(one, two, two, three, three, three)
scala> val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
wordPairsRDD: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[4] at map at <console>:26
(2)将相同key对应值聚合到一个sequence中
scala> val group = wordPairsRDD.groupByKey()
group: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[5] at groupByKey at <console>:28
(3)打印结果
scala> group.collect()
res1: Array[(String, Iterable[Int])] = Array((two,CompactBuffer(1, 1)), (one,CompactBuffer(1)), (three,CompactBuffer(1, 1, 1)))
(4)计算相同key对应值的相加结果
scala> group.map(t => (t._1, t._2.sum))
res2: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[6] at map at <console>:31
(5)打印结果
scala> res2.collect()
res3: Array[(String, Int)] = Array((two,2), (one,1), (three,3))
reduceByKey(func, [numTasks]) 案例
作用:在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置。
需求:创建一个pairRDD,计算相同key对应值的相加结果
(1)创建一个pairRDD
scala> val rdd = sc.parallelize(List(("female",1),("male",5),("female",5),("male",2)))
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[46] at parallelize at <console>:24
(2)计算相同key对应值的相加结果
scala> val reduce = rdd.reduceByKey((x,y) => x+y)
reduce: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[47] at reduceByKey at <console>:26
(3)打印结果
scala> reduce.collect()
res29: Array[(String, Int)] = Array((female,6), (male,7))
reduceByKey和groupByKey的区别
1、reduceByKey:按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是RDD[k,v].;
2、groupByKey:按照key进行分组,直接进行shuffle;
3、开发指导:reduceByKey比groupByKey,建议使用但是需要注意是否会影响业务逻辑;
aggregateByKey案例
参数:(zeroValue:U,[partitioner: Partitioner]) (seqOp: (U, V) => U,combOp: (U, U) => U)
作用:在kv对的RDD中,,按key将value进行分组合并,合并时,将每个value和初始值作为seq函数的参数,进行计算,返回的结果作为一个新的kv对,然后再将结果按照key进行合并,最后将每个分组的value传递给combine函数进行计算(先将前两个value进行计算,将返回结果和下一个value传给combine函数,以此类推),将key与计算结果作为一个新的kv对输出。
1、 参数描述:;
(1)zeroValue:给每一个分区中的每一个key一个初始值;
(2)seqOp:函数用于在每一个分区中用初始值逐步迭代value;
(3)combOp:函数用于合并每个分区中的结果。
2、 需求:创建一个pairRDD,取出每个分区相同key对应值的最大值,然后相加;
3、 需求分析;
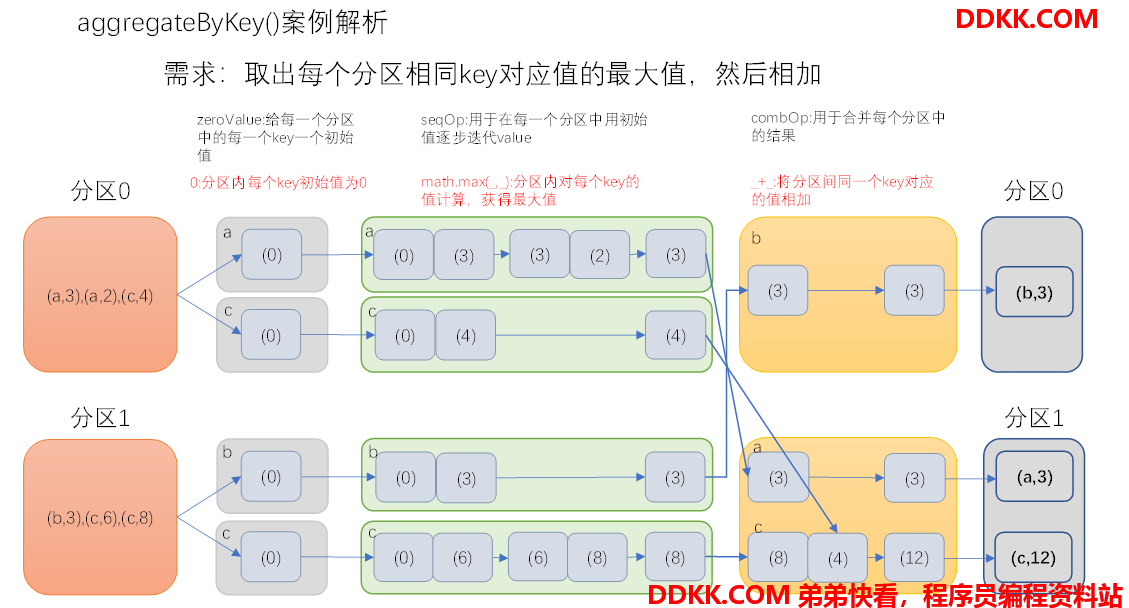
(1)创建一个pairRDD
scala> val rdd = sc.parallelize(List(("a",3),("a",2),("c",4),("b",3),("c",6),("c",8)),2)
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[0] at parallelize at <console>:24
(2)取出每个分区相同key对应值的最大值,然后相加
scala> val agg = rdd.aggregateByKey(0)(math.max(_,_),_+_)
agg: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[1] at aggregateByKey at <console>:26
(3)打印结果
scala> agg.collect()
res0: Array[(String, Int)] = Array((b,3), (a,3), (c,12))
foldByKey案例
参数:(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
作用:aggregateByKey的简化操作,seqop和combop相同
需求:创建一个pairRDD,计算相同key对应值的相加结果
(1)创建一个pairRDD
scala> val rdd = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),3)
rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[91] at parallelize at <console>:24
(2)计算相同key对应值的相加结果
scala> val agg = rdd.foldByKey(0)(_+_)
agg: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[92] at foldByKey at <console>:26
(3)打印结果
scala> agg.collect()
res61: Array[(Int, Int)] = Array((3,14), (1,9), (2,3))
combineByKey[C] 案例
参数:(createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C)
作用:对相同K,把V合并成一个集合。
1、参数描述:
(1)** createCombiner**: combineByKey() 会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就和之前的某个元素的键相同。如果这是一个新的元素,combineByKey()会使用一个叫作createCombiner()的函数来创建那个键对应的累加器的初始值
(2)** mergeValue**: 如果这是一个在处理当前分区之前已经遇到的键,它会使用mergeValue()方法将该键的累加器对应的当前值与这个新的值进行合并
(3)** mergeCombiners**: 由于每个分区都是独立处理的, 因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器, 就需要使用用户提供的 mergeCombiners() 方法将各个分区的结果进行合并。
2、需求:创建一个pairRDD,根据key计算每种key的均值。(先计算每个key出现的次数以及可以对应值的总和,再相除得到结果)
3、需求分析:
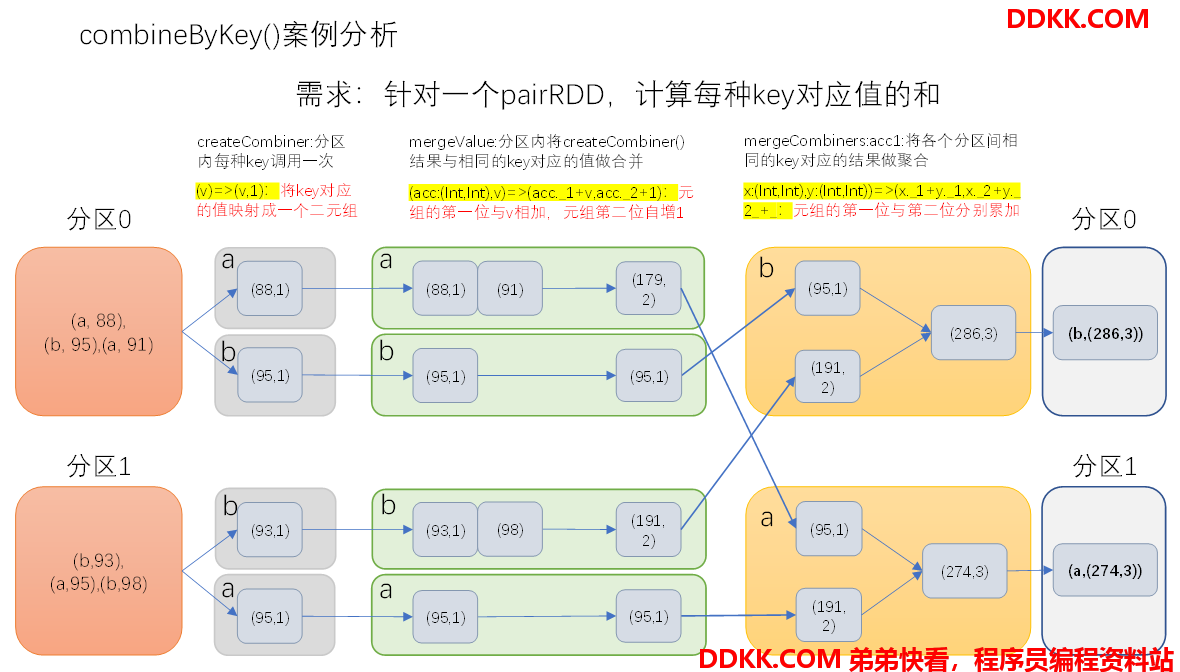
(1)创建一个pairRDD
scala> val input = sc.parallelize(Array(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)),2)
input: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[52] at parallelize at <console>:26
(2)将相同key对应的值相加,同时记录该key出现的次数,放入一个二元组
scala> val combine = input.combineByKey((_,1),(acc:(Int,Int),v)=>(acc._1+v,acc._2+1),(acc1:(Int,Int),acc2:(Int,Int))=>(acc1._1+acc2._1,acc1._2+acc2._2))
combine: org.apache.spark.rdd.RDD[(String, (Int, Int))] = ShuffledRDD[5] at combineByKey at <console>:28
(3)打印合并后的结果
scala> combine.collect
res5: Array[(String, (Int, Int))] = Array((b,(286,3)), (a,(274,3)))
(4)计算平均值
scala> val result = combine.map{
case (key,value) => (key,value._1/value._2.toDouble)}
result: org.apache.spark.rdd.RDD[(String, Double)] = MapPartitionsRDD[54] at map at <console>:30
(5)打印结果
scala> result.collect()
res33: Array[(String, Double)] = Array((b,95.33333333333333), (a,91.33333333333333))
sortByKey([ascending], [numTasks]) 案例
作用:在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD
需求:创建一个pairRDD,按照key的正序和倒序进行排序
(1)创建一个pairRDD
scala> val rdd = sc.parallelize(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[14] at parallelize at <console>:24
(2)按照key的正序
scala> rdd.sortByKey(true).collect()
res9: Array[(Int, String)] = Array((1,dd), (2,bb), (3,aa), (6,cc))
(3)按照key的倒序
scala> rdd.sortByKey(false).collect()
res10: Array[(Int, String)] = Array((6,cc), (3,aa), (2,bb), (1,dd))
mapValues案例
作用:针对于(K,V)形式的类型只对V进行操作
需求:创建一个pairRDD,并将value添加字符串"|||"
(1)创建一个pairRDD
scala> val rdd3 = sc.parallelize(Array((1,"a"),(1,"d"),(2,"b"),(3,"c")))
rdd3: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[67] at parallelize at <console>:24
(2)对value添加字符串"|||"
scala> rdd3.mapValues(_+"|||").collect()
res26: Array[(Int, String)] = Array((1,a|||), (1,d|||), (2,b|||), (3,c|||))
join(otherDataset, [numTasks]) 案例
作用:在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD
需求:创建两个pairRDD,并将key相同的数据聚合到一个 元组。
(1)创建第一个pairRDD
scala> val rdd = sc.parallelize(Array((1,"a"),(2,"b"),(3,"c")))
rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[32] at parallelize at <console>:24
(2)创建第二个pairRDD
scala> val rdd1 = sc.parallelize(Array((1,4),(2,5),(3,6)))
rdd1: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[33] at parallelize at <console>:24
(3)join操作并打印结果
scala> rdd.join(rdd1).collect()
res13: Array[(Int, (String, Int))] = Array((1,(a,4)), (2,(b,5)), (3,(c,6)))
cogroup(otherDataset, [numTasks]) 案例
作用:在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable,Iterable))类型的RDD
需求:创建两个pairRDD,并将key相同的数据聚合到一个 迭代器。
(1)创建第一个pairRDD
scala> val rdd = sc.parallelize(Array((1,"a"),(2,"b"),(3,"c")))
rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[37] at parallelize at <console>:24
(2)创建第二个pairRDD
scala> val rdd1 = sc.parallelize(Array((1,4),(2,5),(3,6)))
rdd1: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[38] at parallelize at <console>:24
(3)cogroup两个RDD并打印结果
scala> rdd.cogroup(rdd1).collect()
res14: Array[(Int, (Iterable[String], Iterable[Int]))] = Array(
(1,(CompactBuffer(a),CompactBuffer(4))),
(2,(CompactBuffer(b),CompactBuffer(5))),
(3,(CompactBuffer(c),CompactBuffer(6)))
)
案例实操
1、 数据结构:时间戳,省份,城市,用户,广告,中间字段使用空格分割;
样本如下(数据在博主网盘):
链接:https://pan.baidu.com/s/1Tq4nV0ZrTKR1Miuqi8Yp-Q
提取码:prqr
1516609143867 6 7 64 16
1516609143869 9 4 75 18
1516609143869 1 7 87 12
2、 需求:统计出每一个省份广告被点击次数的TOP3;
3、 实现过程:;
package com.package.practice
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
//需求:统计出每一个省份广告被点击次数的TOP3
object Practice {
def main(args: Array[String]): Unit = {
//1.初始化spark配置信息并建立与spark的连接
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Practice")
val sc = new SparkContext(sparkConf)
//2.读取数据生成RDD:TS,Province,City,User,AD
val line = sc.textFile("E:\\IDEAWorkSpace\\SparkTest\\src\\main\\resources\\agent.log")
//3.按照最小粒度聚合:((Province,AD),1)
val provinceAdToOne = line.map {
x =>
val fields: Array[String] = x.split(" ")
((fields(1), fields(4)), 1)
}
//4.计算每个省中每个广告被点击的总数:((Province,AD),sum)
val provinceAdToSum = provinceAdToOne.reduceByKey(_ + _)
//5.将省份作为key,广告加点击数为value:(Province,(AD,sum))
val provinceToAdSum = provinceAdToSum.map(x => (x._1._1, (x._1._2, x._2)))
//6.将同一个省份的所有广告进行聚合(Province,List((AD1,sum1),(AD2,sum2)...))
val provinceGroup = provinceToAdSum.groupByKey()
//7.对同一个省份所有广告的集合进行排序并取前3条,排序规则为广告点击总数
val provinceAdTop3 = provinceGroup.mapValues {
x =>
x.toList.sortWith((x, y) => x._2 > y._2).take(3)
}
//8.将数据拉取到Driver端并打印
provinceAdTop3.collect().foreach(println)
//9.关闭与spark的连接
sc.stop()
}
}