编程模型
在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换。经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,action可以是向应用程序返回结果(count, collect等),或者是向存储系统保存数据(saveAsTextFile等)。在Spark中,只有遇到action,才会执行RDD的计算(即延迟计算),这样在运行时可以通过管道的方式传输多个转换。
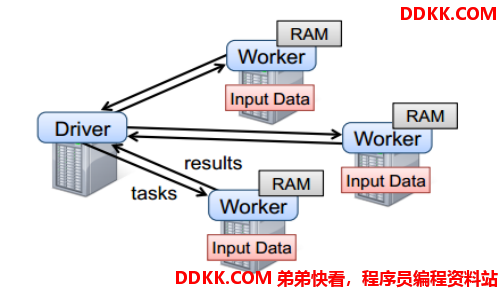
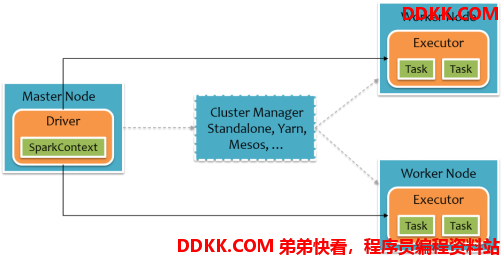
要使用Spark,开发者需要编写一个Driver程序,它被提交到集群以调度运行Worker,如下图所示。Driver中定义了一个或多个RDD,并调用RDD上的action,Worker则执行RDD分区计算任务。
RDD的创建
在Spark中创建RDD的创建方式可以分为三种:
- 从集合中创建RDD;
- 从外部存储创建RDD;
- 从其他RDD创建。
1、 由一个已经存在的Scala集合创建;
valrdd3 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
或者
valrdd4 = sc.makeRDD(List(1,2,3,4,5,6,7,8))
makeRDD方法底层调用了parallelize方法

2、 由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等;
valrdd1 = sc.textFile(“hdfs://node01:8020/wordcount/input/words.txt”)
3、 通过已有的RDD经过算子转换生成新的RDD;
valrdd2=rdd1.flatMap(_.split(" "))