WordCount思路
准备数据
将数据放在以下目录中
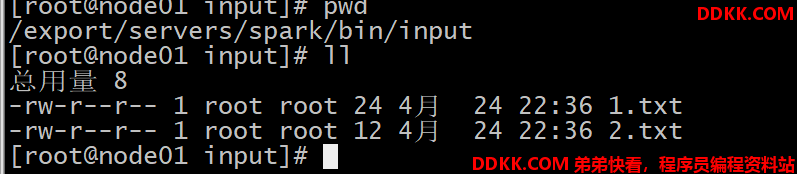
1.txt
Hello World
Hello Scala
2.txt
Hello Spark
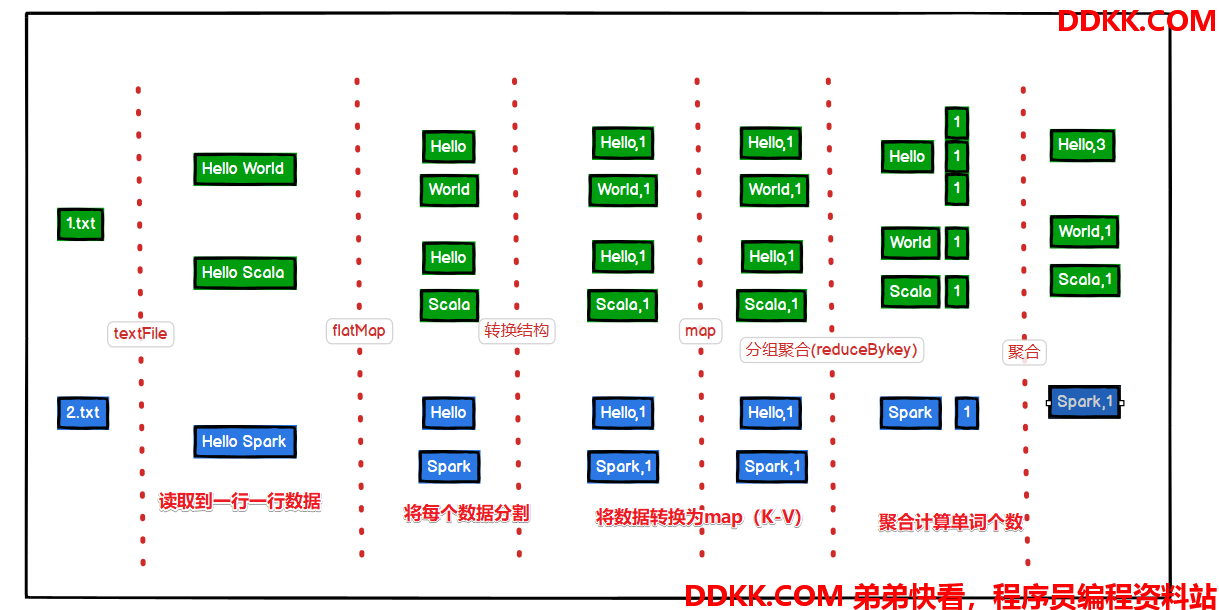
图解分析
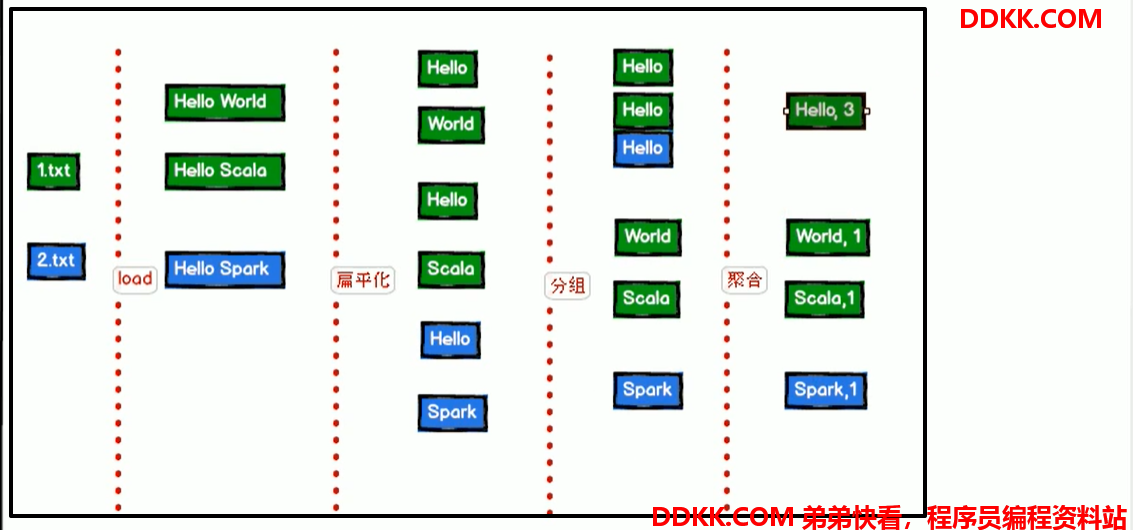
说明:
- 1、本地读取两个文件
- 2、两个文件内的数据
- 3、将文件内的数据进行扁平化
- 4、将相同单词进行分组
- 5、聚合计算每个单词的个数
WordCount代码实现
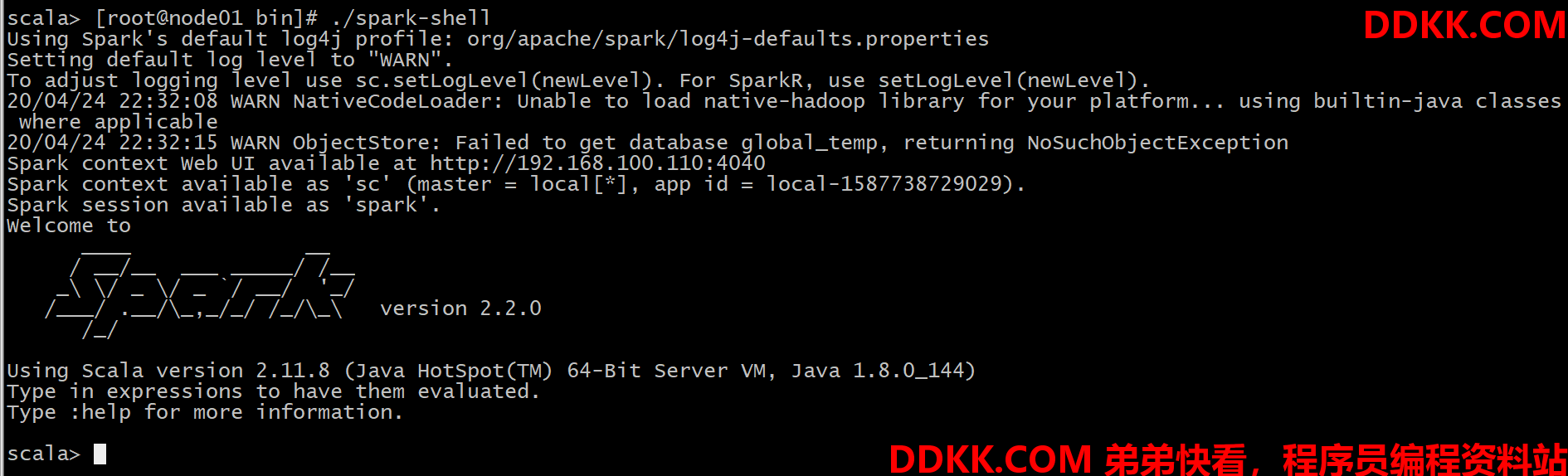
第一步:启动Spark-Shell
//进入spark
[root@node01 softwares]# cd ../servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
//进入bin目录
[root@node01 spark-2.2.0-bin-2.6.0-cdh5.14.0]# cd bin/
//启动本地Spark-shell
[root@node01 bin]# ./spark-shell
看到以下界面,说明启动成功
第二步:读取文件
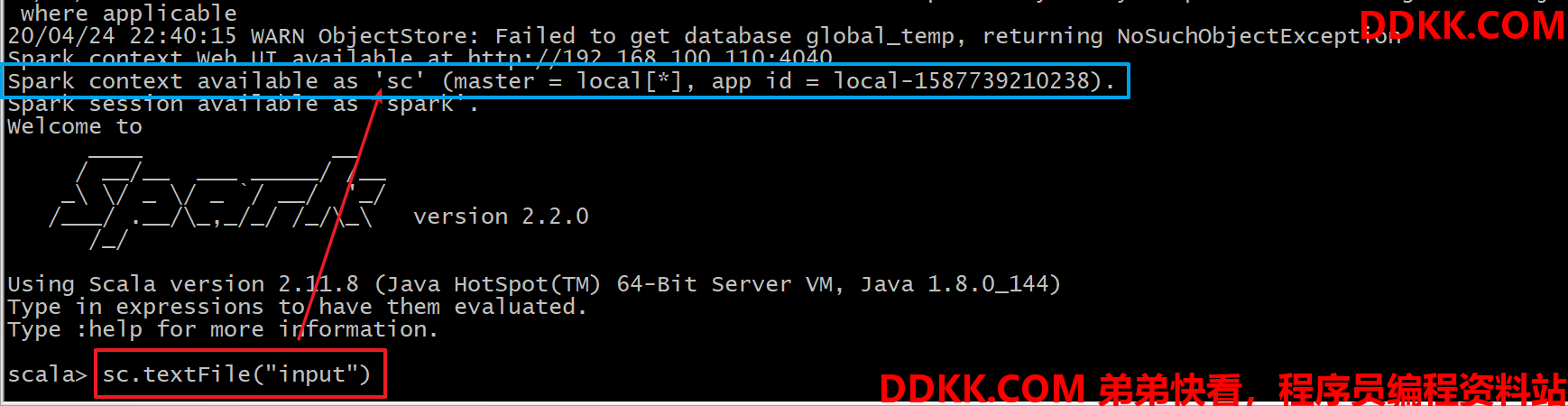
此处为什么可以直接将input路径输入,而不需要输入具体数据文件路径???
在Spark-Shell开启后,系统自带将SparkContext(上下文对象)创建,而input文件夹,在spark中,使用sc刚好可以读取到(这是一个相对路径)文件数据,所以不需要具体到数据文件。
转换图解:与上图对比
//读取数据(textFile)
scala> val textFile=sc.textFile("input")
//读取文件,得到String类型的字符串(RDD)
textFile: org.apache.spark.rdd.RDD[String] = input MapPartitionsRDD[1] at textFile at <console>:24
//扁平化数据(flatMap)
scala> sc.textFile("input").flatMap
def flatMap[U](f: String => TraversableOnce[U])(implicit evidence$4: scala.reflect.ClassTag[U]): org.apache.spark.rdd.RDD[U]
//将数据结构转换(map)
scala> sc.textFile("input").flatMap(_.split(" ")).map((_,1))
//使用算子计算单词个数(reduceByKey)
scala> sc.textFile("input").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
res3: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[16] at reduceByKey at <console>:25
//调用collect查询结果
scala> res3.collect
res4: Array[(String, Int)] = Array((Spark,1), (World,1), (Scala,1), (Hello,3))