前言
首先介绍一下 Spark 的创始团队开创的公司 Databricks。

Databricks 是湖仓一体概念的提出者和先驱者。目前除了 Spark,开源的热门项目还有 Delta Lake 和 Mlflow,服务客户超过一万,在全球有非常高的投资和年收入。
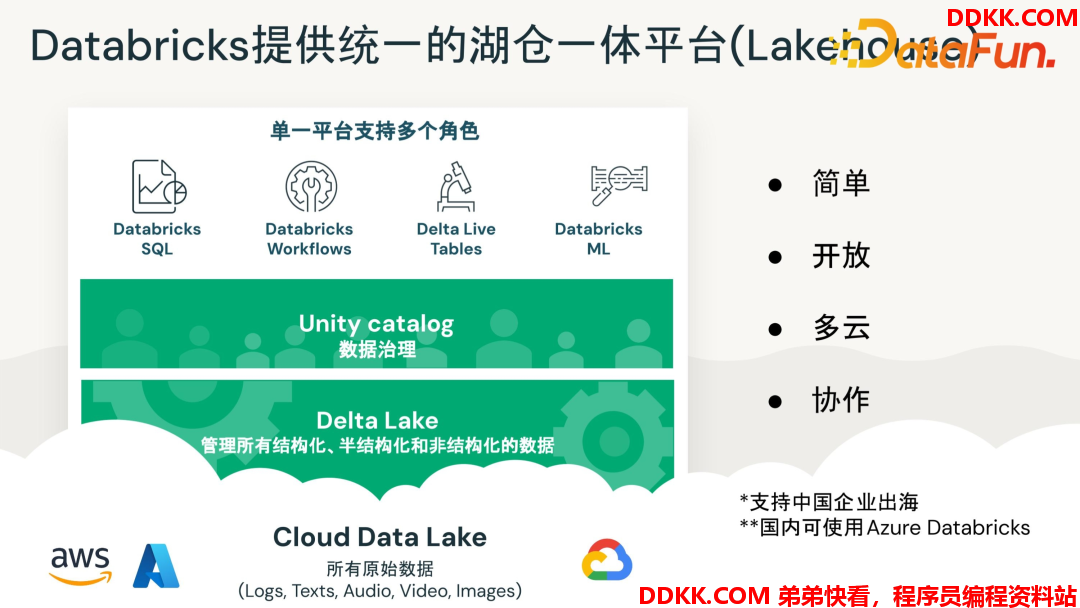
公司在大中华区开始开展业务。国内可通过 Azure Databricks 来使用公司的产品。Databricks 提供统一的湖仓一体平台(Lakehouse),可以支撑整个企业数据平台的使用,和一些AI相关的开发工作。

平台是非常通用的,可以涉及各行各业,目前已经服务的客户有医疗行业、制造业、娱乐业、金融行业等等。
接下来我们一起来看看 Spark 3.4 都有哪些有趣的新特性吧。
Community Updates
Spark 诞生于伯克利大学 AMPLab,属于伯克利大学的研究性项目,2013 年 Spark正式成为 Aparch 基金项目,到目前已经有十年时间。

这10年中 Spark 社区非常活跃,我们来看下当前Spark 社区的情况。
- Maven各个渠道的下载量超过了 10 亿
- Stack Overflow 上超过 10 万个问题
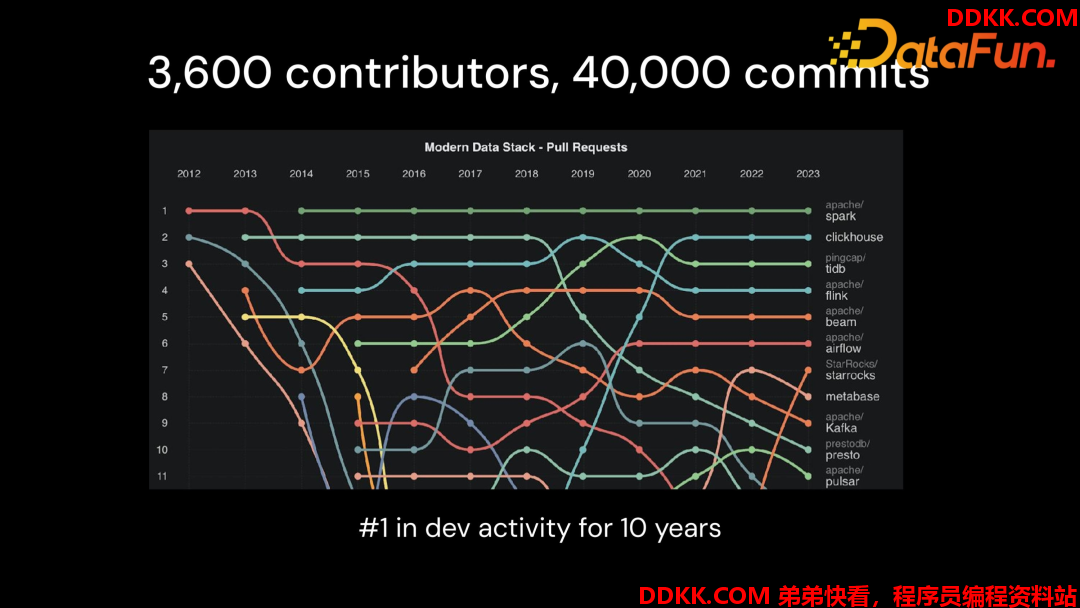
- GitHub上贡献作者超过 3600 个
- 整个Spark 生态超过 100 个 Data Source
- 超过44 万个 commits
- 下载和使用覆盖全球200 多个国家
可以看到 Spark 整个社区还是非常活跃的,在整个开源大数据项目里面,Spark 的开发活跃度一直遥遥领先。
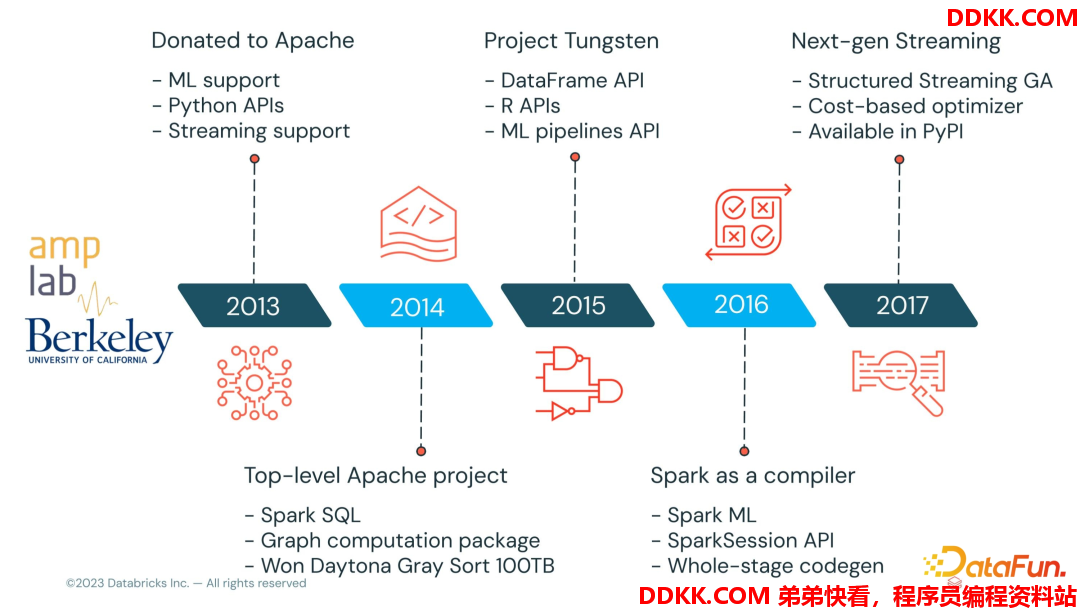
Spark 从创建后发展迅速,通过下图可以看到这10 年中,Spark 一直在创新的路上。比如 ML 支持,多语言丰富的 API,丰富的 data source 支持,较好的内存优化机制,且可使用 Spark SQL 进行流数据处理、离线数据处理,增加了ANSI SQL 使 Spark SQL 更加标准,方便大家从其他数据库的 SQL 脚本迁移到 Spark 上来。
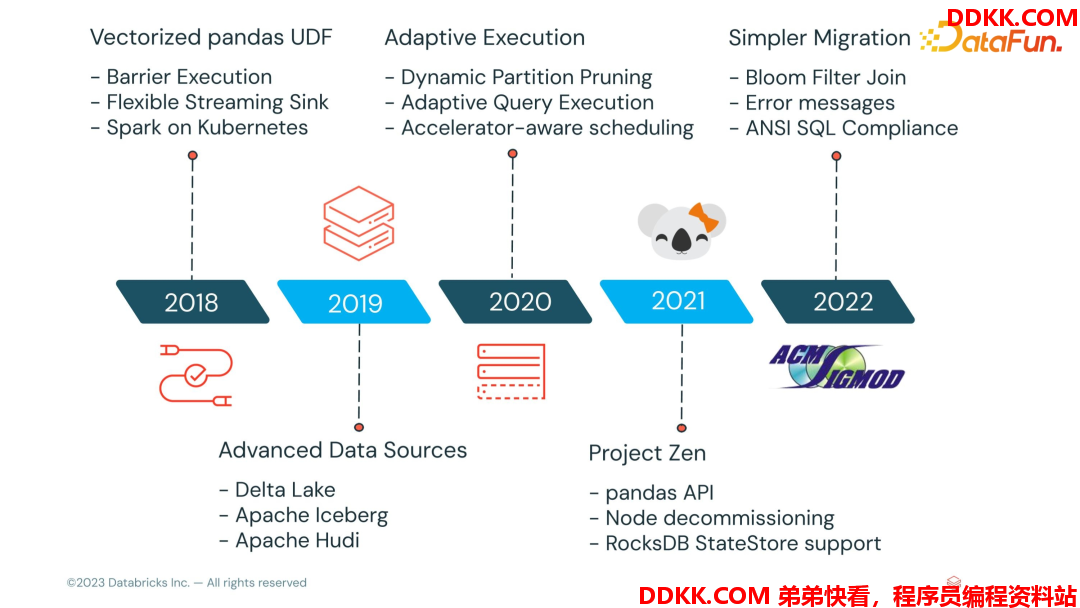
下面是Spark 3.4 发布的一些新特性,接下来将挑选其中一些有意思的特性来分享。

SQL Features
Spark3.4 博采众长,参考了很多其他数据库里常见的函数,把它们内置到 Spark 里方便大家使用。

- Set DEFA****ULT Values for Columns in Tables
我们在使用数据库的时候,可以在一个 value 上设置一个默认值,这样在插入数据时不需要每次指定一个值,而是让它提供一个默认值,如将一个ID、日期设置成默认填充。

- Supported table formats include CSV, JSON, Orc, and Parquet.
支持多种文件格式

- This works either at initial table creation table time, or afterwards.
针对表已存在,可以通过 alter table 去修改列默认值属性

下面来看看如何使用。
- INSERT commands may then refer to any column’s default value using the DEFAULT keyword.
- 数据插入

- 结果

可以看到当前时间的默认值已经插入进去。
如果column 没有设默认值,且这个 column 可以为 NULL,那么 DEFAULT默认就是 NULL。如下这个例子,两行都插入那个默认值,第一列虽然没有设置默认值属性,但是会默认填充NULL 值。

- Use DESCRIBE EXTENDED to check default value
可以使用 DESCRIBE EXTENDED 来查看列属性信息。

- Use DESCRIBE EXTENDED to check default value
我们在使用 INSERT 赋值时可以指定比目标表更少的列的显示列表,它会自动为其余列添加默认值,UPDATE 和 MERGE 也是如此。如下:
- INSERT

- UPDATE

- MERGE

- TIMESTAMP WITHOUT TIMEZONE Data Type
目前timestamp 类型的语义不符合标准,它会参考一个local time zone 去解释当前的 timestamp的年月日,导致不同时区读取的字段内容不一致。目前3.4 引入了 TIMESTAMP_NTZ 来解决这个问题。

- Lateral Column Alias References
之前在SQL 使用当前 query 的别名列需要通过子查询,在新的 query 中去引用该别名字段。Spark 3.4 解决了这个问题,可以使用变量列名来引用到 select 左边的那些别名列。如下:
- Before

- Now

Parameterized SQL Queries
参数化SQL 查询,给 SQL 语句一个 statement,通过 API 往里填参数,降低 SQL注入攻击的风险。此功能无缝集成到 SparkSession API 中。
如下是该功能的 API,主要有两个参数:
SQLText:SQL 字符串
Args:Map 类型,存放参数和参数值

示例:

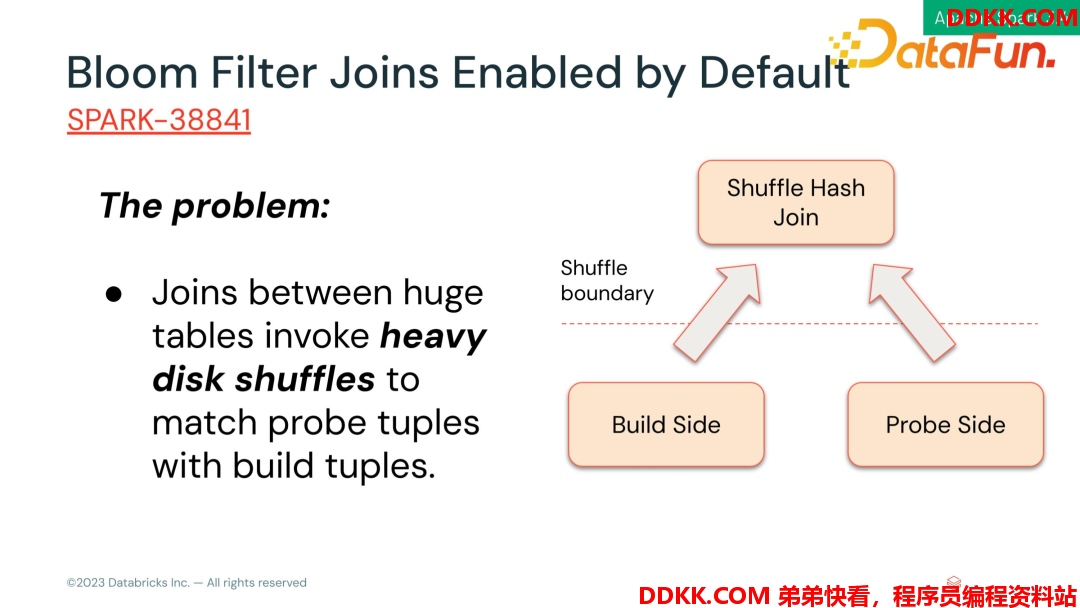
- Bloom Filter Joins Enabled by Default
大表之间的 join shuffle 需要借用大量磁盘空间。假设是要做一个shuffle 的 hash join,两边的 table 都要 shuffle 一下,如果左表不是那么大,右边很大,shuffle 就会导致整个右表都会写入消费文件,导致整个 IO 非常重,性能差。解决方法就是把左边中型表制作为Bloom FILTER,来过滤右表,把数据提前过滤后再写 shuffle,从而降低 shuffle 的 IO 量,提高整个查询的性能。
- The OFFSET Clause
Offset 主要用来做翻页使用。

- Table-Valued Generator Functions in the FROM Clause
FROM 子句中的表值生成器函数,如EXPLODE,在老版本中不易理解。

现在放在 FROM 子句中这个语法更易解读,更加符合标准。

- GROUP BY ALL / ORDER BY ALL
这一特性非常有用,比如在一个查询中需要 group by 很多字段,一个个填的话会很麻烦。在3. 4 中提供了 group by all,这样不用再挨个填写分组字段,它会自动识别到分组的字段,使分组更加便捷。order by all 也是一样道理。
(1)GROUP BY ALL

(2)ORDER BY ALL

PySpark and Streaming
下面介绍 PySpark 和 Steaming 的一些特性。
1. PySpark

(1)Spark Connect Python Client
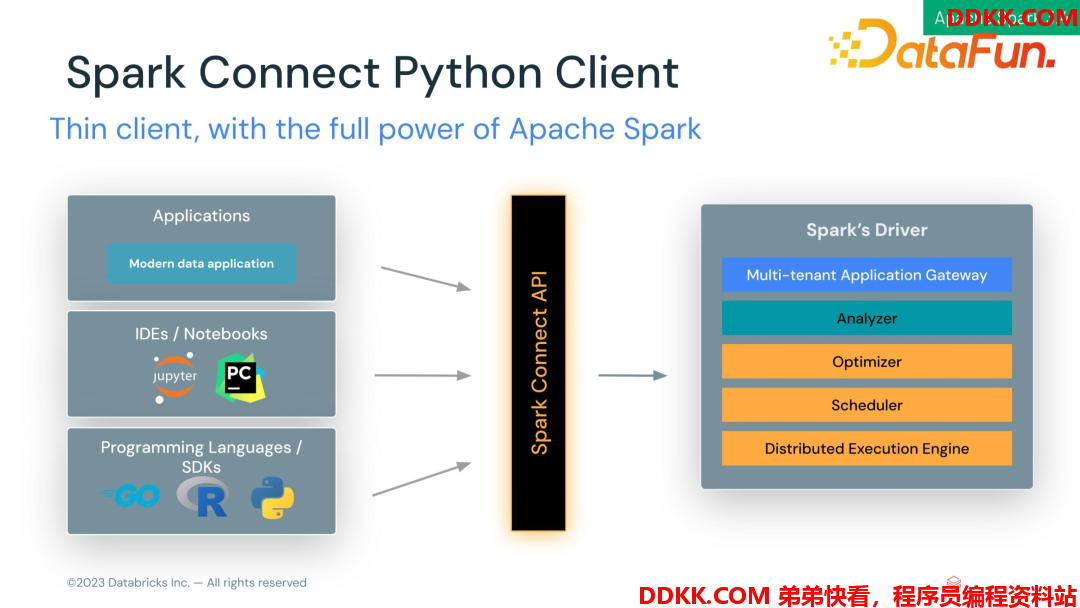
Spark Driver 以前的工作是很重的,不仅要做查询优化,还要做调度。Spark Connect 的目标是把这个重的工作作为一个 service 长期存在,API 重新通过 client 来定义,这样 client 只做 API 的调用,不涉及任何的计算过程,将 API 请求发送给 Spark Driver。这样 client 就会非常轻量,可以在各个地方去使用,比如在 IDEA 里面、Jupyter 里面去实现,都会比较简单。
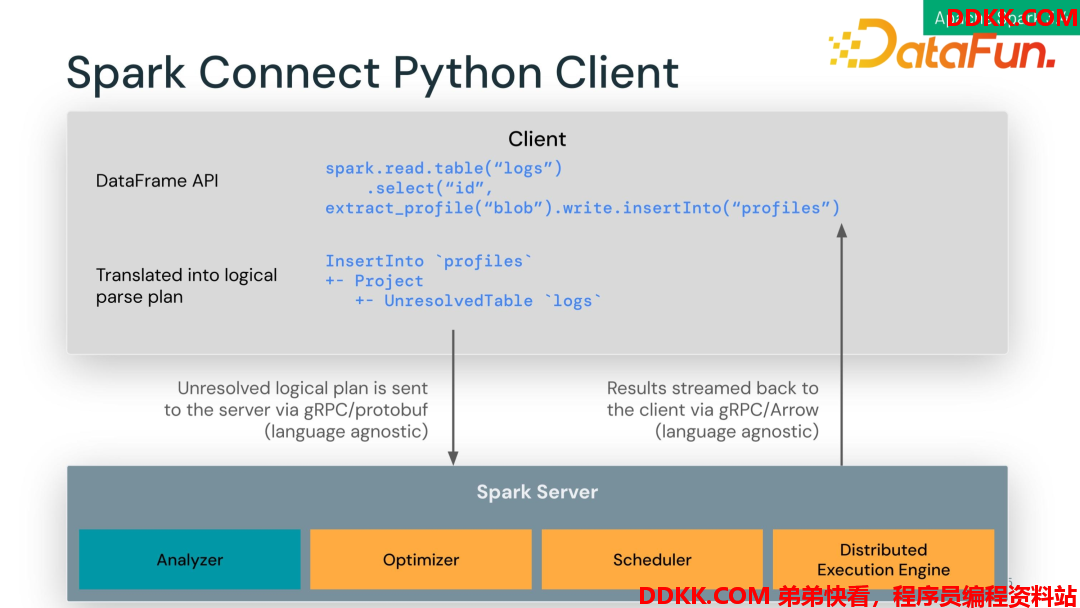
它的底层是 client 端定义的 DataFrame API,API 会被翻译成一个 query plan,将 query plan 序列化通过 gRPC 发送给 Spark Server,也就是 Spark Driver,Spark Driver 计算之后再将结果发回 client 端。Client 针对各个语言,定义好 API,之后执行计划解析都是通用的,所以可以极大地降低 client 端开发成本,同时整个架构也更加通用。
那么我们如何使用 Spark Connect Server 呢?
- 代码上指定
- 启动脚本时指定

如何部署 Spark Connect Server?

Spark Connect Server 是一个长期运行的服务,为了容错性高,后面计划给它做一个高可用,也可能会考虑和一些开源项目合作,如Gateway 网关项目等,让它们直接能够使用 Spark Connect Server 作为后台的计算引擎。
(2)Python UDF Memory Profiler
在写Python UDF 时 debug 函数性能或者memory 占用情况是比较麻烦的。当前Spark 版本提供了一个比较方便的方式,去 debug Python UDF 的memory 占用情况。
要使用这个功能首先指定开启 Profile 的功能。
举个例子:

这个UDF 是一个非常简单的加一操作,并返回加一的结果值。在select 里面用一下, show 出执行结果。最后调用 sc.show profiles() 查看 Profile 的结果。

Profile 首先打印这个UDF 的 ID,接着打印 UDF每一行 memory 的使用量。可以看到 UDF 初始量为974M,然后计算加一操作,内存涨了 0. 4 MB。这样就可以清晰地看到每一步UDF 里面内存是怎么变化的。同时可以通过 UDF ID 和 explain 里的执行计划去做对应。
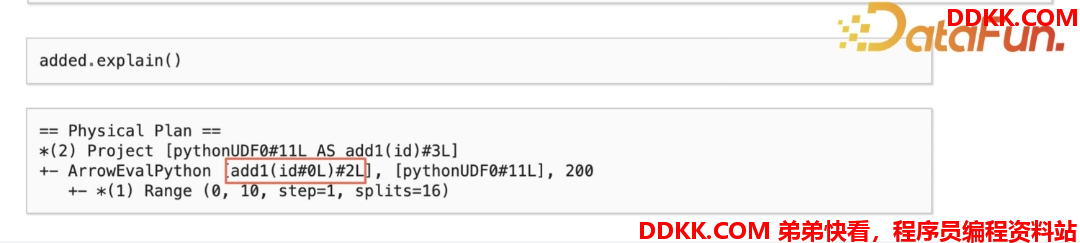
如刚刚执行的 select,能看到执行计划里执行定义的UDF 函数的 UDF ID 同Profile 中可以进行对应,如果逻辑复杂,UDF 非常多,可以一一对应上,就可以清晰地知道哪个UDF 在哪里使用。
(3)PyTorch Distributor
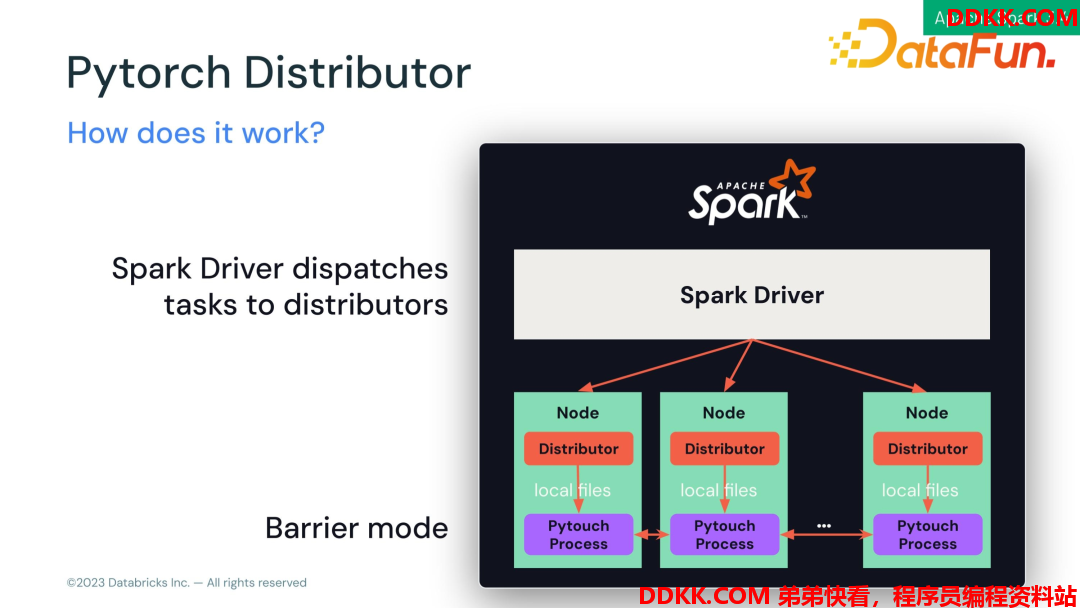
PyTorch Distributor 是为了方便在 Spark 上跑模型的训练函数。算法模型数据的清洗和训练操作一般是分开的,比如用 Spark 做 ETL,将结果存在数据库里或者 parquet 定文件里,用 PyTorch 分布式地做模型训练,把这些数据再读出来。分布式从同一个地方读取数据这个操作其实是比较慢的,存在大量IO,现在可以使用 Spark 协同合作,可以保证 Spark worker 和 PyTorch worker 是在同一个结点,使用Spark 把数据先写本地文件,然后启动一个 PyTorch 进程读本地文件,然后把PyTorch 进程都串起来做模型训练,减少不必要的 IO。
下面我们看看如何在程序中使用。

假设定义好一个 train 的函数,使用 Python API 直接在 Python 里创建一个Python distributor,将 train 函数作为参数传入。
当然也可以直接写到文件里面,指定文件位置,将文件位置作为参数传入,如下所示:

(4)API Coverage

Pandas API 增强,因为 Pandas 在升级,会有新的 API,Spark 也需要不停地去做适配。比如在 Spark3.4 里面做了 Numpy 的支持。之前如果创建一个 dataframe,只能用 Python 本地的一些类型和 Pandas 的一些数据类型来创建。在 Spark3.4 之后也可以使用 Numpy 来创建。
2、 Streaming;

Spark 采用微批模型来处理流式数据,也就是streaming 会被分割成一个个批次,然后做计算。为保证事务性,在每个微批前后都会加 log commit,下面来了解一下 Spark3.4 在 log commit 上做的改动。
**(1)**Asynchronous Progress Tracking
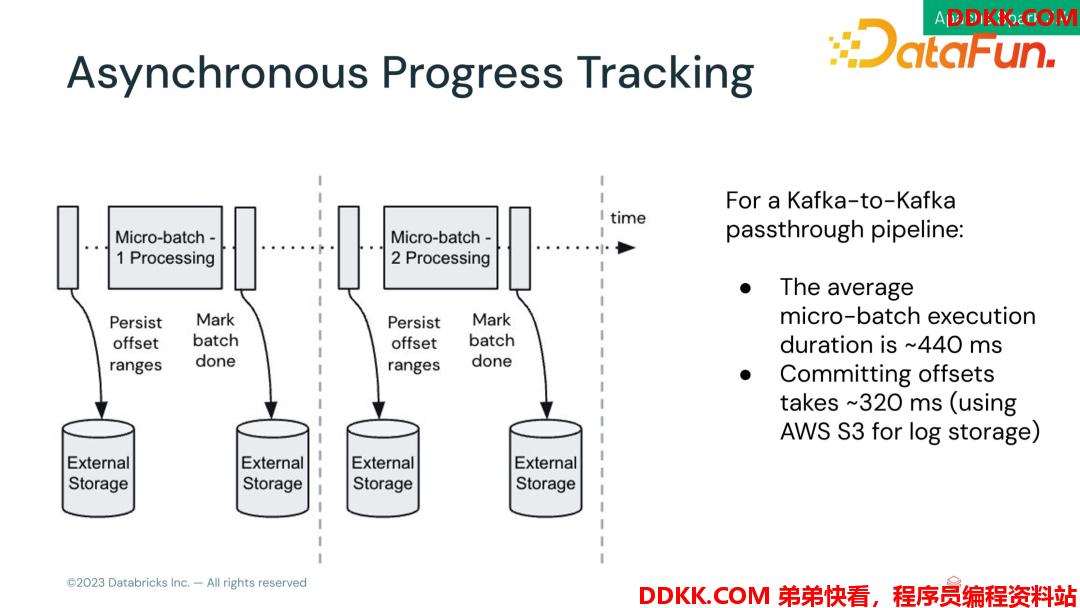
举一个Kafka to Kafka 的示例,程序中间没有复杂算子和 shuffle,每个微批大约需要耗时 440ms,其中 320ms 都是在做 log commit。也就是有超过一半多的时间都没有在干正事。优化的思路也很简单,就是把log commit 做异步提交,这样计算和 log commit 的开销时间是重叠的。
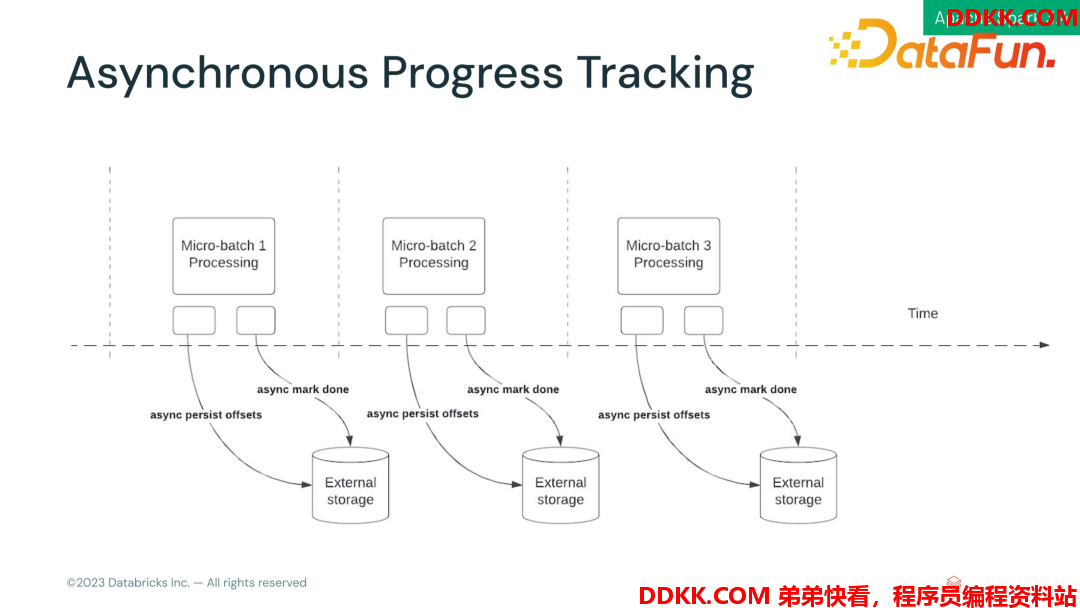
思考1:如果计算时间非常短,log commit 异步的队列会不会越来越长?
这个情况肯定会存在,解决方式是对 log commit 做一些合并,降低commit 的频率。比如每10个微批做一次 log commit。
思考2:如果任务失败,合并的动作会不会导致数据丢失?
因为我们对 log commit 做了合并,如果任务失败,日志还未写入到磁盘,是会丢失这段时间数据的。所以我们需要使用这个特性的话需要关注任务的稳定性是否高,以及是否允许报错后较短时间的数据丢失。
接下来我们看看如何使用这一特性:

- 开启asyncProgressTracking。
- 结合业务设置日期提交的间隔时间。
(2)Python Arbitrary Stateful Processing
自定义streaming 状态处理。在程序中可能会自定义一些操作,可以使用对应的API去检查、控制和更改这个状态。
Scala API**:**

Python API**:**

(3)Other Features
①Error Message Improvement
采用新的 error message 框架,对错误日志改进,便于排查问题。提升点如下:
- 给错误定义一个ID,便于网上搜索或者Spark文档上找到这个问题。
- 错误的信息里面加入SQL的那个上下文,便于定位错误代码位置。
- 标记疑似错误的具体代码位置。
后面会考虑将这个框架应用到更多地方。

②Scalable Spark Live UI
之前当集群任务很多的时候 Spark Live UI 就会卡顿,因为Spark 会把所有的历史任务的 UI 数据都存在 memory 里面,任务多的时候就会占用大量资源。当前版本对 Spark UI 框架做了架构调整,使用RocksDB 来保存的 UI 数据,物化存储,用的时候再读出来,效率得到了很大提升。
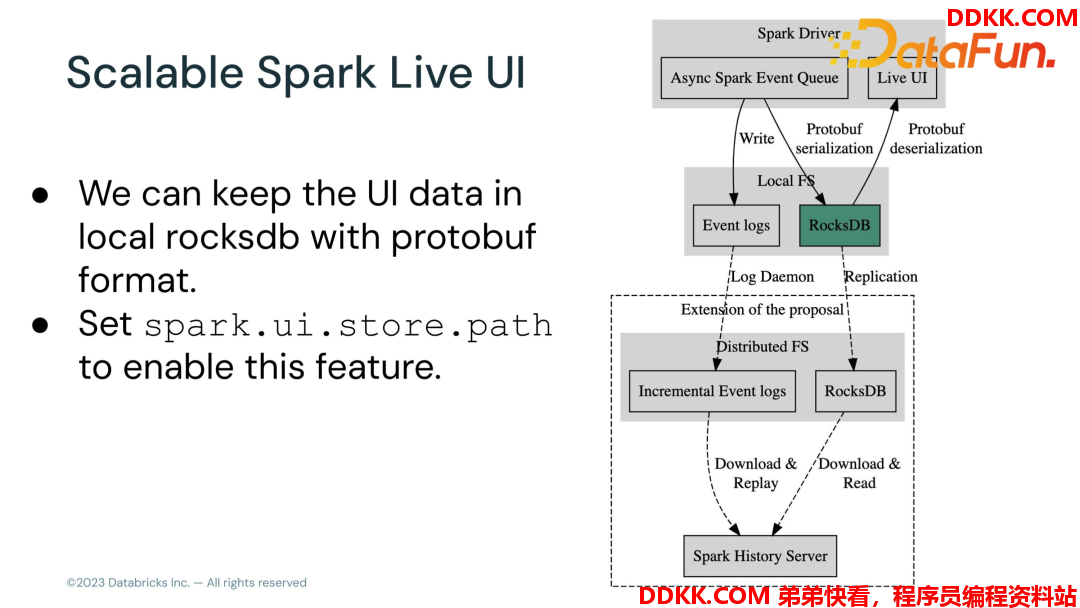
使用这个特性需要设置这个 Spark.ui.store.path参数,指定 RocksDB 的文件位置,就可以开启这个特性了。
最后罗列一些特性,大家感兴趣可以去官网查看。

AI Ecosystem
Databricks 的架构师 Reynold Xin 认为,基于目前所呈现的趋势,以后大家可能不再需要学习编程语言,AI 会变成新的编译器,帮助我们把自然语言编译成代码来执行。
目前English SDK for Spark 已经提供了一些 API,使用 English 来描述需求,AI帮你编写 Spark 代码。
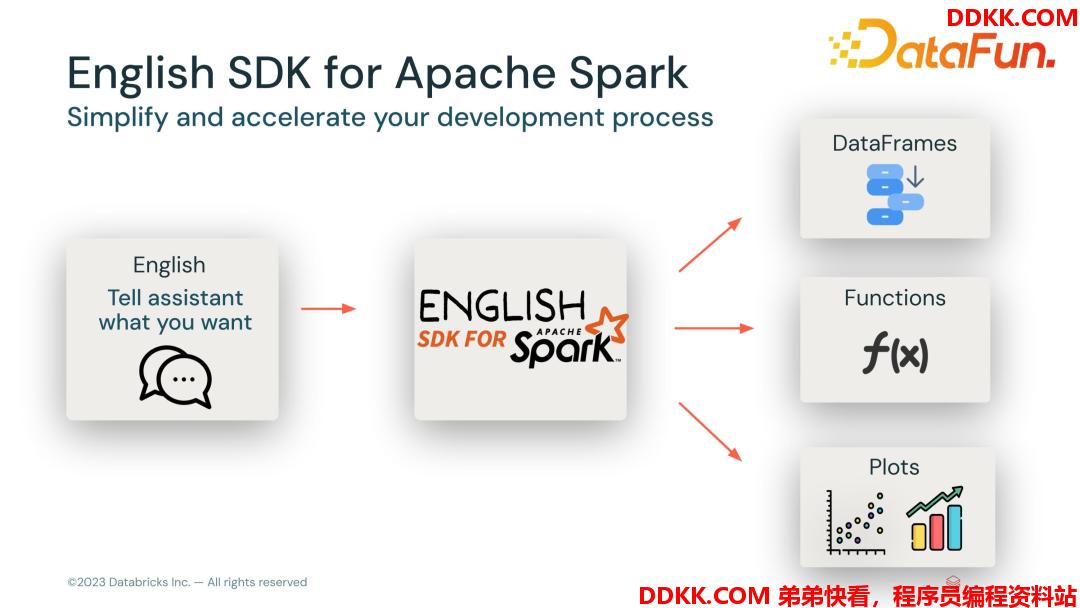
它的整个 API 是前端用户通过自然语言描述需求,Spark AI 会根据描述生成DataFrames,也可以帮你定义 UDF 或者图标分析,当然这些功能的自动生成都需要依赖用户的描述。
我们来看看 API 的使用。
- DataFrame的创建和转换

用户描述需求,AI 可以从知识库里面检索到这个信息,生成 DataFrame,或者直接指定网站地址,AI 可以做爬虫,分析这个网址的内容,帮助判断这个网页上有什么数据是可以被抽取的,最后帮助你生成一个 DataFrame。
当需要生成的 DataFrame 做转换操作时,也可以直接将需求提给Spark AI,AI 会帮你做转换操作。
- 数据可视化

Spark AI 也可以对筛选好的数据结果做数据可视化,都不需要用户自己写代码。
- 功能描述

当用户对生成的 DataFrame 疑惑时,AI 的 explain API 可以解释这个 DF 的生成过程,它主要是做什么事情。
- 验证

Spark AI 可以帮忙校验生成的DF 是否合法。无需用户自己写一个函数,剔除需求,AI 可以帮你做校验。

如果想实现一个 Spark UDF,Spark AI 也是可以帮忙实现的。
最后来看一下未来的一些工作方向:
- Expanding DataFrame operations for more comprehensive analyses.
- Enhancing text-to-SQL generation for seamless database interactions.
- Developing user-defined table value functions and data sources for custom data handling.
- Facilitating test case generation to improve development quality and speed
如果大家想更多地了解 Spark AI,可以访问http://pySpark.ai。
以上就是本次分享的内容,谢谢大家。