Spark Local环境部署
下载地址
https://dist.apache.org/repos/dist/release/spark/spark-3.4.1/spark-3.4.1-bin-hadoop3.tgz
条件
- Python3.11.4
- JDK1.8
解压
解压下载的Spark安装包
tar -zxvf spark-3.4.1-bin-hadoop3.tgz -C /home/hadoop/opt/
环境变量
配置Spark 环境变量:
- SPARK_HOME: 表示Spark安装路径位置
- PYSPARK_PYTHON: 表示Spark想运行Python程序, 那么去哪里找Python执行解释器
- JAVA_HOME: 告知Spark Java的位置
- HADOOP_CONF_DIR: 告知Spark Hadoop的配置文件位置
- HADOOP_HOME: 告知Spark Hadoop安装位置
这5个环境变量都需要配置在: /etc/profile中
#JAVA环境变量
export JAVA_HOME=/home/hadoop/opt/jdk1.8.0_152
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
# scala
export SCALA_HOME=/home/hadoop/opt/scala-2.12.17
export PATH=$SCALA_HOME/bin:$PATH
# hadoop
export HADOOP_HOME=/home/hadoop/opt/hadoop-3.3.5
export PATH=$HADOOP_HOME/bin:$PATH
export PATH=$HADOOP_HOME/sbin:$PATH
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_CLASSPATH=hadoop classpath
# spark
export SPARK_HOME=/home/hadoop/opt/spark-3.4.1-bin-hadoop3
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
# pyspark_python
export PYSPARK_PYTHON=/usr/bin/python
PYSPARK_PYTHON和 JAVA_HOME 需要同样配置在当前用户(hadoop): vi /home/hadoop/.bashrc中
export PYSPARK_PYTHON=/usr/bin/python
export JAVA_HOME=/home/hadoop/opt/jdk1.8.0_152
测试
bin/pyspark
bin/pyspark 程序, 可以提供一个 交互式的 Python解释器环境, 在这里面可以写普通python代码, 以及spark代码
[hadoop@node01 spark-3.4.1-bin-hadoop3]$ bin/pyspark
Python 3.11.4 (main, Jun 20 2023, 16:29:19) [GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.
23/06/20 21:04:08 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ / __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.4.1
/_/
Using Python version 3.11.4 (main, Jun 20 2023 16:29:19)
Spark context Web UI available at http://node01:4040
Spark context available as 'sc' (master = local[*], app id = local-1687266249233).
SparkSession available as 'spark'.
>>> sc.parallelize([1,2,3,4,5,6,7,8,9]).map(lambda x: x * 10).collect()
[10, 20, 30, 40, 50, 60, 70, 80, 90]
>>>
在这个环境内, 可以运行spark代码,parallelize 和 map 都是spark提供的API。
WEB UI (4040)
Spark程序在运行的时候, 会绑定到机器的4040端口上。如果4040端口被占用, 会顺延到4041 ... 4042...。4040端口是一个WEBUI端口, 可以在浏览器内打开,输入:服务器ip:4040 即可。
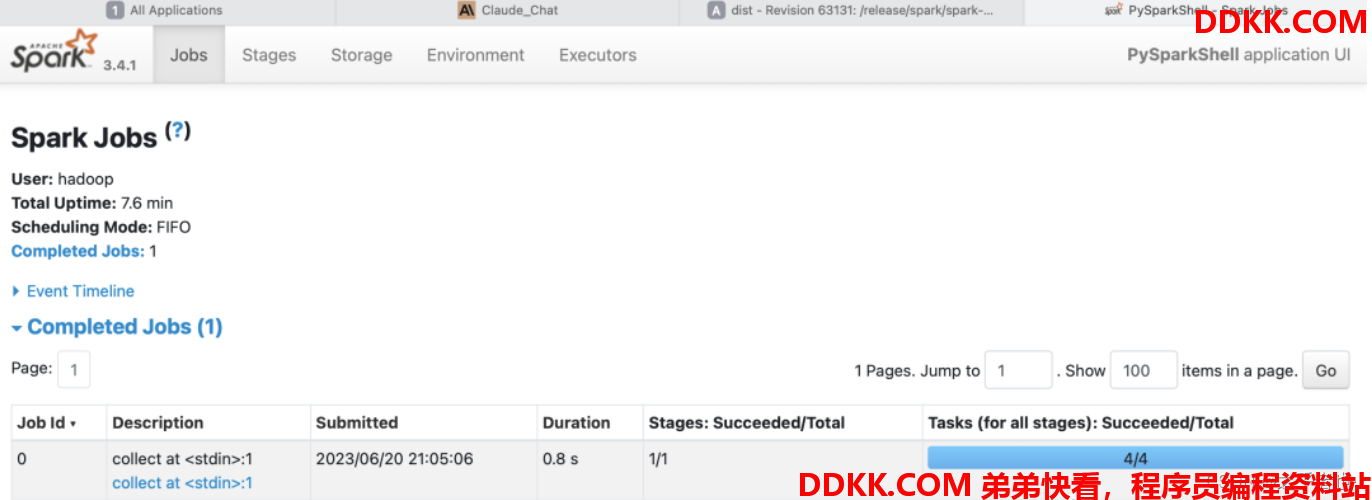
打开监控页面后, 可以发现在程序内仅有一个Driver,因为我们是Local模式, Driver即管理又干活。

bin/spark-shell
同样是一个解释器环境, 和bin/pyspark不同的是, 这个解释器环境 运行的不是python代码, 而是scala程序代码。
[hadoop@node01 spark-3.4.1-bin-hadoop3]$ bin/spark-shell
23/06/20 21:15:56 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://node01:4040
Spark context available as 'sc' (master = local[*], app id = local-1687266957286).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ / __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.4.1
/_/
Using Scala version 2.12.17 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_152)
Type in expressions to have them evaluated.
Type :help for more information.
scala> sc.parallelize(Array(1,2,3,4,5,6,7,8,9)).map(x=> x + 1).collect()
res0: Array[Int] = Array(2, 3, 4, 5, 6, 7, 8, 9, 10)
scala>
bin/spark-submit
作用:提交指定的Spark代码到Spark环境中运行
使用方法:
# 语法
bin/spark-submit [可选的一些选项] jar包或者python代码的路径 [代码的参数]
# 示例
bin/spark-submit /home/hadoop/opt/spark-3.4.1-bin-hadoop3/examples/src/main/python/pi.py 100
# 此案例 运行Spark官方所提供的示例代码 来计算圆周率值. 后面的10 是主函数接受的参数, 数字越高, 计算圆周率越准确.
三种提交方式对比
| 功能 | bin/spark-submit | bin/pyspark | bin/spark-shell |
|---|---|---|---|
| 功能 | 提交java\scala\python代码到spark中运行 |
提供一个python环境 |
提供一个scala环境 |
| 特点 | 提交代码用 | 解释器环境 写一行执行一行 | 解释器环境 写一行执行一行 |
| 使用场景 | 正式场合, 正式提交spark程序运行 | 测试\学习\写一行执行一行\用来验证代码等 | 测试\学习\写一行执行一行\用来验证代码等 |
Spark StandAlone环境部署
新角色 历史服务器
❝
历史服务器不是Spark环境的必要组件, 是可选的.
❝
在YARN中 有一个历史服务器, 其功能是将YARN运行的程序的历史日志记录下来, 通过历史服务器方便用户查看程序运行的历史信息.
[hadoop@node01 sbin]$ jps
31921 HistoryServer # Spark 的历史服务器进程
19202 JobHistoryServer # YARN 的历史服务器进程
Spark的历史服务器, 功能: 将Spark运行的程序的历史日志记录下来, 通过历史服务器方便用户查看程序运行的历史信息.
搭建集群环境, 我们一般推荐将历史服务器也配置上, 方面以后查看历史记录
# 打开配置文件
vi /home/hadoop/opt/spark-3.4.1-bin-hadoop3/conf/spark-env.sh
# 设置历史服务器 将spark程序运行的历史日志 存到hdfs的/spark_history_log文件夹中
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_history_log/ -Dspark.history.fs.cleaner.enabled=true"
启动历史服务器
[hadoop@node01 sbin]$ start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /home/hadoop/opt/spark-3.4.1-bin-hadoop3/logs/spark-hadoop-org.apache.spark.deploy.history.HistoryServer-1-node01.out
[hadoop@node01 sbin]$
集群规划
| ip | hostname | 角色 |
|---|---|---|
| 192.168.40.131 | node01 | Master进程 和 1个Worker进程 |
| 192.168.40.132 | node02 | 1个worker进程 |
| 192.168.40.133 | node03 | 1个worker进程 |
整个集群提供: 1个master进程 和 3个worker进程。
安装
1、 在所有机器安装Python、Java环境;
2、 在所有机器配置环境变量,参考Local模式下环境变量的配置内容,确保3台都配置;
修改配置文件
进入到spark的配置文件目录中, cd $SPARK_HOME/conf
配置workers文件
# 改名, 去掉后面的.template后缀
mv workers.template workers
# 编辑worker文件,这个文件就是指示了 当前SparkStandAlone环境下, 有哪些worker。
vim workers
# 将里面的localhost删除, 追加
node01
node02
node03
到workers文件内
配置spark-env.sh文件
# 1. 改名
mv spark-env.sh.template spark-env.sh
# 2. 编辑spark-env.sh, 在底部追加如下内容
#设置JAVA安装目录
JAVA_HOME=/home/hadoop/opt/jdk1.8.0_152
# HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
# 指定spark老大Master的IP和提交任务的通信端口
# 告知Spark的master运行在哪个机器上
export SPARK_MASTER_HOST=node01
# 告知spark master的通讯端口
export SPARK_MASTER_PORT=7077
# 告知spark master的 webui端口
SPARK_MASTER_WEBUI_PORT=8080
# worker cpu可用核数
SPARK_WORKER_CORES=1
# worker可用内存
SPARK_WORKER_MEMORY=1g
# worker的工作通讯地址
SPARK_WORKER_PORT=7078
# worker的 webui地址
SPARK_WORKER_WEBUI_PORT=8081
## 设置历史服务器
# 配置的意思是 将spark程序运行的历史日志 存到hdfs的/spark_history_log文件夹中
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_history_log/ -Dspark.history.fs.cleaner.enabled=true"
在HDFS上创建程序运行历史记录存放的文件夹:
hadoop fs -mkdir /spark_history_log
hadoop fs -chmod 777 /spark_history_log
配置spark-defaults.conf文件
# 1. 改名
mv spark-defaults.conf.template spark-defaults.conf
# 2. 修改内容, 追加如下内容
# 开启spark的日期记录功能
spark.eventLog.enabled true
# 设置spark日志记录的路径
spark.eventLog.dir hdfs://node01:8020/spark_history_log/
# 设置spark日志是否启动压缩
spark.eventLog.compress true
配置log4j.properties 文件 [可选配置]
# 1. 改名
mv log4j.properties.template log4j.properties
# 2. 打开文件
vi log4j.properties
# 3. 日子级别由 info 改为 warn
rootLogger.level = warn
将Spark安装文件夹分发到其它的服务器上
scp -r spark-3.4.1-bin-hadoop3 hadoop@node02:/home/hadoop/opt/
scp -r spark-3.4.1-bin-hadoop3 hadoop@node03:/home/hadoop/opt/
检查
检查每台机器的:
JAVA_HOME
SPARK_HOME
PYSPARK_PYTHON
等等环境变量是否正常指向正确的目录
启动历史服务器
sbin/start-history-server.sh
启动Spark的Master和Worker进程
# 启动全部master和worker
sbin/start-all.sh
# 或者可以一个个启动
# 启动当前机器的master
sbin/start-master.sh
# 启动当前机器的worker
sbin/start-worker.sh
# 停止全部
sbin/stop-all.sh
# 停止当前机器的master
sbin/stop-master.sh
# 停止当前机器的worker
sbin/stop-worker.sh
查看Master的WEB UI
默认端口master我们设置到了8080
如果端口被占用, 会顺延到8081 ...;8082... 8083... 直到申请到端口为止
可以在日志中查看, 具体顺延到哪个端口上:
Service 'MasterUI' could not bind on port 8080. Attempting port 8081.
连接到StandAlone集群
bin/pyspark
执行:
# 通过--master选项来连接到 StandAlone集群
# 如果不写--master选项, 默认是local模式运行
bin/pyspark --master spark://node01:7077
# 测试
[hadoop@node01 spark-3.4.1-bin-hadoop3]$ bin/pyspark --master spark://node01:7077
Python 3.11.4 (main, Jun 20 2023, 16:29:19) [GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.
23/06/20 22:03:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
23/06/20 22:03:50 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
23/06/20 22:03:50 WARN Utils: Service 'SparkUI' could not bind on port 4041. Attempting port 4042.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ / __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.4.1
/_/
Using Python version 3.11.4 (main, Jun 20 2023 16:29:19)
Spark context Web UI available at http://node01:4042
Spark context available as 'sc' (master = spark://node01:7077, app id = app-20230620220351-0000).
SparkSession available as 'spark'.
>>> sc.parallelize([1,2,3,4,5,6,7,8,9]).map(lambda x: x * 10).collect()
[10, 20, 30, 40, 50, 60, 70, 80, 90]
>>>
bin/spark-shell
# 同样适用--master来连接到集群使用
bin/spark-shell --master spark://node01:7077
# 测试
[hadoop@node01 spark-3.4.1-bin-hadoop3]$ bin/spark-shell --master spark://node01:7077
23/06/20 22:05:51 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
23/06/20 22:05:51 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
23/06/20 22:05:51 WARN Utils: Service 'SparkUI' could not bind on port 4041. Attempting port 4042.
Spark context Web UI available at http://node01:4042
Spark context available as 'sc' (master = spark://node01:7077, app id = app-20230620220551-0001).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ / __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.4.1
/_/
Using Scala version 2.12.17 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_152)
Type in expressions to have them evaluated.
Type :help for more information.
scala> sc.parallelize(Array(1,2,3,4,5,6,7,8,9)).map(x=> x + 1).collect()
res0: Array[Int] = Array(2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> sc.parallelize(Array(1,2,3,4,5,6,7,8,9)).map(x=> x * 10).collect()
res1: Array[Int] = Array(10, 20, 30, 40, 50, 60, 70, 80, 90)
scala>
bin/spark-submit
# # 同样使用--master来指定将任务提交到集群运行
bin/spark-submit --master spark://node01:7077 /home/hadoop/opt/spark-3.4.1-bin-hadoop3/examples/src/main/python/pi.py 100
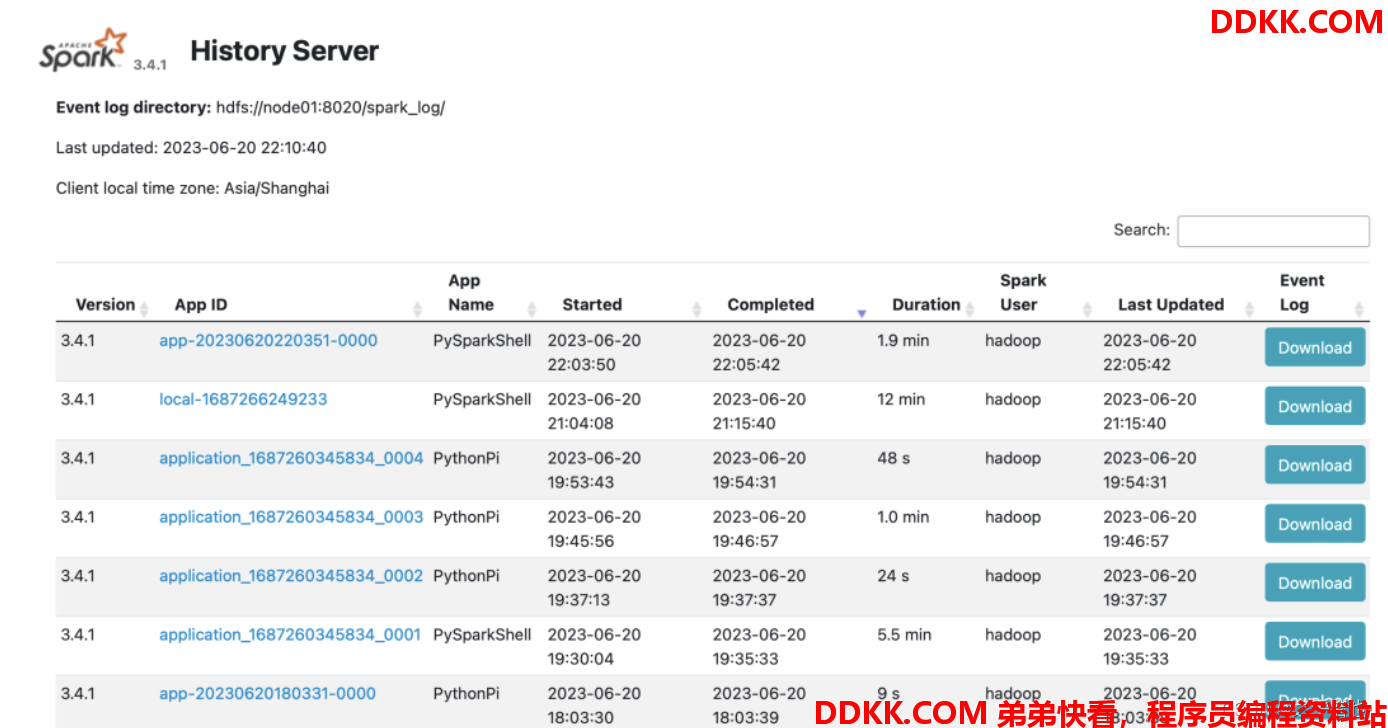
查看历史服务器WEB UI
历史服务器的默认端口是: 18080
我们启动在node01上, 可以在浏览器打开:node1:18080来进入到历史服务器的WEB UI上。
Spark StandAlone HA 环境搭建
步骤
❝
前提: 确保Zookeeper 和 HDFS 均已经启动
先在spark-env.sh中, 删除: SPARK_MASTER_HOST=node01
原因:配置文件中固定master是谁, 那么就无法用到zk的动态切换master功能了.
在spark-env.sh中, 增加:
# spark.deploy.recoveryMode 指定HA模式 基于Zookeeper实现
# 指定Zookeeper的连接地址
# 指定在Zookeeper中注册临时节点的路径
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"
将spark-env.sh 分发到每一台服务器上
scp spark-env.sh hadoop@node02:/home/hadoop/opt/spark-3.4.1-bin-hadoop3/conf/
scp spark-env.sh node3:/home/hadoop/opt/spark-3.4.1-bin-hadoop3/conf/
停止当前StandAlone集群
sbin/stop-all.sh
启动集群:
# 在node01上 启动一个master 和全部worker
sbin/start-all.sh
# 注意, 下面命令在node02上执行
sbin/start-master.sh
# 在node2上启动一个备用的master进程
master主备切换
提交一个spark任务到当前alivemaster上:
bin/spark-submit --master spark://node01:7077 /home/hadoop/opt/spark-3.4.1-bin-hadoop3/examples/src/main/python/pi.py 1000
在提交成功后, 将alive master直接kill掉不会影响程序运行,当新的master接收集群后, 程序继续运行, 正常得到结果。
❝
结论:HA模式下主备切换不会影响到正在运行的程序,最大的影响会让它中断大约30秒左右。
Spark On YARN 环境搭建
部署
确保:
- HADOOP_CONF_DIR
- YARN_CONF_DIR
在spark-env.sh 以及 环境变量配置文件中即可,具体参考Local模式配置。
连接到YARN中
bin/pyspark
# --deploy-mode 选项是指定部署模式, 默认是 客户端模式
# client就是客户端模式
# cluster就是集群模式
# --deploy-mode 仅可以用在YARN模式下
bin/pyspark --master yarn --deploy-mode client|cluster
❝
注意: 交互式环境 pyspark 和 spark-shell 无法运行 cluster模式
bin/spark-submit
bin/spark-submit --master yarn --deploy-mode client|cluster /xxx/xxx/xxx.py 参数
# deploy-mode client
[hadoop@node01 spark-3.4.1-bin-hadoop3]$ bin/spark-submit --master yarn --deploy-mode client --driver-memory 512m --executor-memory 512m --num-executors 3 --total-executor-cores 3 /home/hadoop/opt/spark-3.4.1-bin-hadoop3/examples/src/main/python/pi.py 100
23/06/20 22:26:27 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
23/06/20 22:26:28 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
Pi is roughly 3.143160
# deploy-mode cluster(未输出结果)
[hadoop@node01 spark-3.4.1-bin-hadoop3]$ bin/spark-submit --master yarn --deploy-mode cluster --driver-memory 512m --executor-memory 512m --num-executors 3 --total-executor-cores 3 /home/hadoop/opt/spark-3.4.1-bin-hadoop3/examples/src/main/python/pi.py 100
23/06/20 22:27:19 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
23/06/20 22:27:19 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
[hadoop@node01 spark-3.4.1-bin-hadoop3]$